Hands On Machine Learning with Scikit Learn and TensorFlow(第十二章)
使用tensorflow为多种设备(GPU和CPU)分配计算,并并行运行。与其他框架相比,tensorflow可以让你把图分到不同的设备或者服务器上运行。能让你的操作并行化和同步化。并行化可以让你频繁的使用新数据来训练神经网络,并且可以使你在微调神经网络的时候尝试大量超参数。
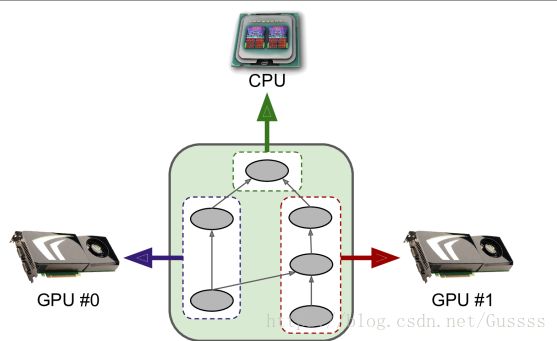
图中把图分成几个部分,交给不同的devices处理
Multiple Devices on a Single Machine
在一台机器上使用8个GPU比多台机器使用16个GPU来的快,因为多台机器之间的神经网络通信有延迟。
需要装CUDA和cuDNN
CUDA:使用CUDA激活的显卡处理所有的计算,不仅仅是显卡加速。
cuDNN:提供优化之后的DNN函数,例如normalization,前向后向卷积,poling等。
可以使用nvidia-smi命令查看有没有正确安装显卡,同时列出了每张显卡上运行的进程。
Managing the GPU RAM
一旦你运行一个图,那么tensorflow会自动抓取所有可用GPUs的所有RAM。所以一旦第一个图在运行,那么就不能开始第二个tensorflow程序。
其中一个解决方法是在不同的GPU中运行不同的图,可以用CUDA_VISIBLE_DEVICES环境变量来指定
$ CUDA_VISIBLE_DEVICES=0,1 python3 program_1.py
# and in another terminal:
$ CUDA_VISIBLE_DEVICES=3,2 python3 program_2.py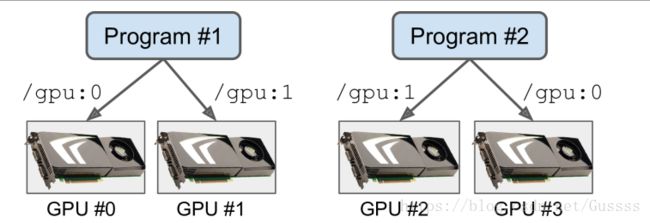
另一种解决方法为:告诉tensorflow只抓取其中一小部分的内存。例如让tensorflow抓取每张GPU的40%的内存。我们要做的是:首先创建一个ConfigProto object,然后设置gpu_options.per_process_gpu_memory_fraction为0.4。
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
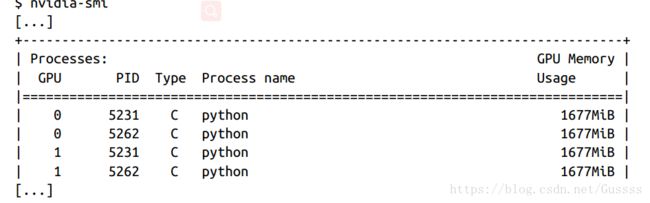
session = tf.Session(config=config)这样做的话,可以使得两个程序同时运行,但是不能3个同时运行,因为0.4X3=1.2大于1了。
这时候使用nvidia-smi查看内存管理,可以看到每个程序大约使用每张显卡的40%的内存。
Placing Operations on Devices
tensorflow中有一种算法名为:dynamic placer algorithm,可以考虑诸多因素自动的把operations 放在所有可用的设备中,然而并不开源,其实在小规模的布置中,用户自己指定规则比dynamic placer algorithm要效率的多。因此,我们使用simple placer来完成这个目的。
Simple placement
你运行一个图的时候,假如tensorflow需要计算一个尚未放在设备上的节点,那么tensorflow会使用simple placer来place这个节点。遵守以下3条原则
- 假如一个节点在上一次运行图中,已经被放置在一个设备中,那么这个节点还是留在那个设备中
- 假如一个节点被绑定在一个设备中,那么simple placer会把这个节点放在这个设备中
- 默认设备为0号GPU,没有GPU就用CPU
把operations放在合适的device(cpu,gpu)中,主要取决于你,假如不做任何操作,那么会把图放在默认的device中。为了把节点pin在一个device中,使用device()函数,如下函数。
with tf.device("/cpu:0"):
a = tf.Variable(3.0)
b = tf.constant(4.0)
c = a * b ##默认放在GPU #0中这个函数 把变量a和常量b pin在cpu(device)中,乘法运算c没有在with块中,所以c没有被pin,所以被放在(place)默认device中(GPU #0,)。其中"/cpu:0"这一句话是把所有的cpus结合到一个多CPU系统,是自动调用所有的CPU的。
Logging placements
现在我们来检查simple placer是否按照刚刚的3条原则来处理。你可以把log_device_placement设置为true.这条命令的作用为告诉simple placer,在它放置一个节点的时候,记录一条信息。
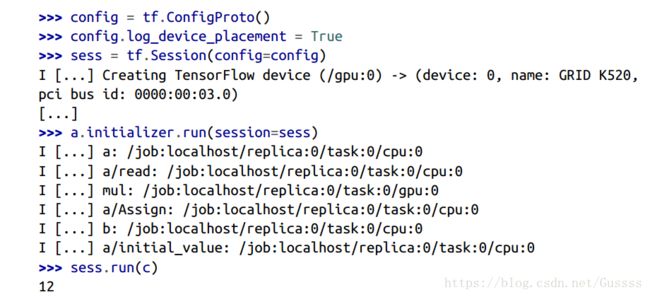
前面的I代表Log 信息。当我们创建一个session的时候,tensorflow记录了一条信息,告诉我们它找到了一个GPU.当我们第一次运行我们定义的图的时候,simple placer开始运行,它把我们刚刚赋值的节点,就是pin的节点 放置到对应的设备中。当我们第二次运行这个图的时候,placer没有被使用,因为所有的节点已经被分配完毕。
Dynamic placement function
当我们像上面一样,创建设备块的时候(一个with块),我们可以不传入设备的名字,而传入一个函数。tensorflow会为在这个with块中,需要被place到设备中的每个operation,自动调用这个函数。需要注意的是,这个函数需要返回设备的名字,用来Pin operation。
def variables_on_cpu(op):
if op.type == "Variable":
return "/cpu:0"
else:
return "/gpu:0"
with tf.device(variables_on_cpu):
a = tf.Variable(3.0)
b = tf.constant(4.0)
c = a * b在上面的代码中,tensorflow会把所有变量都pin在cpu中,把其他的节点放在GPU中。
Operations and kernels
对于一个tensorflow opreration来说,假如需要在一个device中运行,需要拥有对应device的implementation,这种implementation叫一个kernel。许多操作都有对应CPU和GPU的双版本的kernel。但是不是所有的操作都有的。对于一个整数变量来说,它没有对应于GPU的kernel,所以在GPU中运行,会报错。
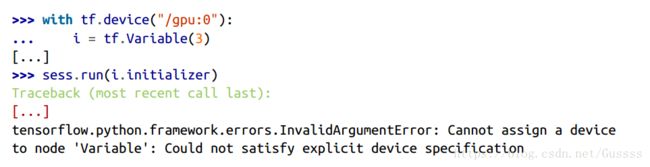
因为tensorflow从那行语句中的初始值3可以推断出这个变量一定是int32型的。假如你把3用3.0来代替,或者直接指定dtype=tf.float32,那么不会报错。
Soft placement
假如你尝试把操作pin在一个device中,这个操作没有对应的kernel,那么还是会像上面那样报错。为了解决此,可以隐形的把操作放在cpu中运行,如下

Parallel Execution
当TensorFlow运行一个图时,它首先查找需要计算的节点列表,然后计算每个节点有多少依赖项。然后tensorflow开始计算没有依赖项的节点(源节点)。假如这些源节点被放置在不同的设备上,那么它们显然会被并行运行。假如它们被放置在同一个device中,这些源节点会在不同的线程中计算,所以也会并行运行。(在单独的GPU线程或者CPU核中)
tensorflow管理每个设备的a thread pool,用来并行化操作。这个工具叫做inter-op thread pool,假如有些操作拥有多线程的核(multi‐threaded kernels:),那么这些操作能使用另一种线程工具-intra-opthread pools
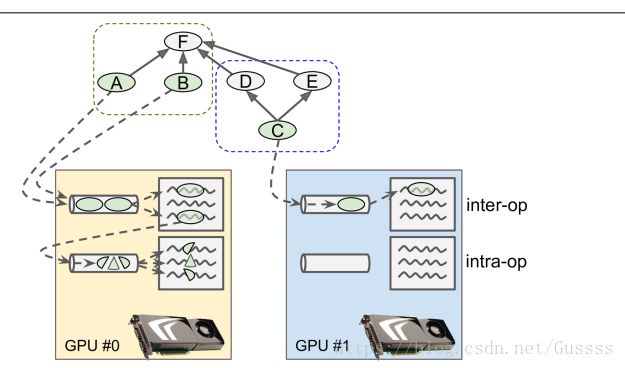
操作A,B,C都是源操作,所以它们能够被立即计算。A,B被放在GPU0中,然后被送入此设备的inter-op thread pool中,立刻被并行运行。操作A碰巧有multithreaded kernel,它的计算被分成3个部分,能够被intra-op thread pool并行执行。操作C进入GPU1的inter-op thread pool。一旦C完成了,D和E的dependency counters会被减少到0,然后这两个操作也会被送入inter-op thread pool中去执行。 就是多线程的并行运算。
就是多线程的并行运算。
可以通过
inter_op_parallelism_threads 来设置每个inter-op pool中线程的数量。第一个Session创建了the inter-op thread pools,后面所有的Session都只是复用而已,除非设置
use_per_session_threads为真。但是你可以控制每个设备中intra-op pool中线程的数量,通过设置
intra_op_parallelism_threads 选项。
Control Dependencies
在某些情况下,即使操作所依赖的所有操作都已执行,推迟对此操作的评估也是明智的。比如这个操作会占用大量的内存,但是它的值只会在图的最后被使用,那么最好在图的最后在评估此操作的值,避免额外占用RAM,来给其他操作腾出空间。另一个例子为:有一系列的操作依赖于device之外的数据,假如这些操作同时运行,会使得此device的通信带宽饱和,使得I/O接口过载。其他的操作想要和数据做通信,也会被阻塞。最好一个接一个的执行这些 重通信的操作,好让这个device并行的执行其他操作。
为了使得某些节点延期,我们使用control dependencies。以下代码告诉tensorflow,只有当a和b被计算了,才能计算x和y。
a = tf.constant(1.0)
b = a + 2.0
with tf.control_dependencies([a, b]):
x = tf.constant(3.0)
y = tf.constant(4.0)
z = x + y即使这里的z没有放在with块中,计算z也意味着等待a和b计算之后才能计算,因为这里z依赖x和y。
因为这里b依赖于a,所以这里可以使用[b]来代替[a,b],但是一般情况下,还是写具体比较好。
Multiple Devices Across Multiple Servers
A cluster是由一个或者多个TensorFlow servers(tasks)组成的,这些servers通常分布在几个机器当中。
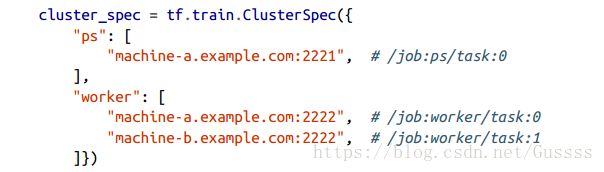
每一个task属于一个job,一个job只是把所有的有共同角色的tasks组合起来,形成一个组。ps代表parameter server,worker的作用为进行运算。下面整张图就是一个cluster

机器A,拥有两个TF server(task),放在不同的端口监听。
以下的cluster specifcation定义了两个jobs
为了开始一个tensorflow server,先定义一个Server object,把刚刚定义的 cluster specifcation传入进去,这样这个server就可以于其他的server通信了,还要传入job 的名字,以及task的编号。
server = tf.train.Server(cluster_spec, job_name="worker", task_index=0)一台机器上所有的任务都会共享一个CPU。如果你想让这个进程只运行tensorflow server,你可以阻塞主线程,通过join()的方法告诉主线程等到server结束(否则,一旦主线程退出,服务器就会被终止)。当前没有方法去停止server,那么会永久的阻塞
server.join()Opening a Session
一旦所有任务都启动并运行 ,你可以从一台客户机上发出一条指令,使你在任意一个server上打开一个session。
a = tf.constant(1.0)
b = a + 2
c = a * 3
with tf.Session("grpc://machine-b.example.com:2222") as sess:
print(c.eval()) # 9.0以上代码从机器B上的tensorflow server中打开了一个session,我们把机器B称为master,然后通知这个session去计算c,master首先将操作放在适当的设备上。在这个例子中,没有把操作pin在任何device上,所以这个master把操作全都放在默认的设备上(B的GPU),
The Master and Worker Services
客户机使用gRPC(Google Remote Procedure Call)协议来和其他的server进行通信。数据以protocol buffers的形式进行传送。tensorflow中的一个cluster种的任意server都有可能与其他的server进行通信,所以要保证打开防火墙上合适的端口。
server提供两种服务:1.master服务以及worker服务,master允许客户机打开sessions,并用sessions运行图, master协调跨任务的计算,其实worker服务器才是真正用作计算用的。
一个client能够通过在不同线程打开多个会话来连接到多个servers。一个server可以同时处理多个sessions(从多个clients发出)
你可以运行一个client来处理一个task,也可以运行一个client来控制多个task。
Pinning Operations Across Tasks
with tf.device("/job:ps/task:0/cpu:0"):
a = tf.constant(1.0)
with tf.device("/job:worker/task:0/gpu:1"):
b = a + 2
c = a + b把a pin在parameters server(ps) job中的第一个任务中的第一个cpu中(使用的是机器A的CPU),第二句是把b pin在管理worker(计算任务)的第一个task的第二块GPU中(A号机器的2号GPU),C没有规定,所以放在默认的设备中(机器B的0号GPU)
假如省略设备以及编号,如这么写/job:ps/task:0",那么会放在默认设备中。假如更省略的话,如这样,"/job:ps"那么会默认在task:0中,假如全都省略了,那么会默认放在session’s master task(如上面代码,放在客户机的默认设备中)
Sharding Variables Across Multiple Parameter Servers
使用分布式设置训练一个神经网络中一种常见模式为:把模型参数放在一系列的参数服务器中(这些参数服务器都放在job中),其他的task专注于进行计算,也就是说把这些task放在worker job中。在拥有百万计的神经网络中,有必要在多个参数服务器中共享参数,减少单个参数服务器网络过载的风险。假如手动的把每个variables pin在不同的参数服务器,那么将是非常繁琐的。幸运的是,可以使用replica_device_setter()函数,可以把变量分配到所有ps tasks中。以下代码把5个变量(variables)pin到2个参数服务器(parameter server)中。
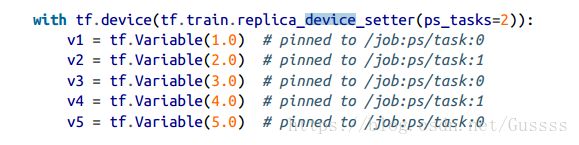
除了传入ps_tasks,还可以传入cluster=cluster_spec,tensorflow会自动的统计在ps job中 task的数量
假如你在这个块中添加了其他操作,不仅仅是变量操作,tensorflow会自动的把这些操作放在/job:worker"中,可以通过worker_device参数把这些操作pin到其他的device中,在内部块中,可以重写外部块的job,task,device,例如以下代码

在上面的例子中,parameter servers仅仅是CPU,这种情况是典型的情况,因为在本例中只需要存储参数,并与其他参数进行通信。而不需要稠密的计算。
Sharing State Across Sessions Using Resource Containers
当你使用本地的session的时候(不是分布式的情况),每一个变量的状态都由这个session管理。在这个session结束的时候,所有变量的值都会丢失。多个本地的session不能共享状态,即使它们运行的是同一张图。每个session都由变量的副本。然而,在你使用distributed sessions(分布式session)的时候,变量的状态由cluster中的资源容器(resource containers)管理,而不是由session管理。假如使用client session来创建一个变量,那么只要在同一个cluster中,任何session都可以调用,即使两个session连接到不同的server中
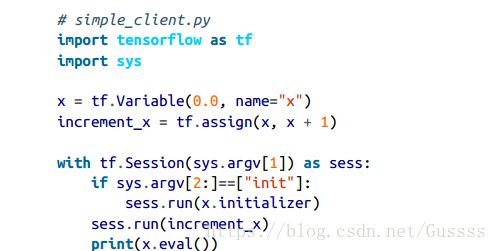
在客户机(client)上使用以下命令运行,在机器A上用server打开一个session。
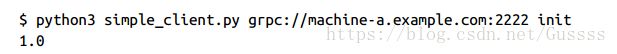
然后重新使用以下代码重新启用客户端,它会在机器B上连接上这个server,重用变量x,
![]()
这会造成矛盾,比如说你想在多个session中共享变量,或者是在同一个cluster中完全进行独立的运算(必须小心不能使用相同的变量名字)。可以给每个计算分配一个名字,例如。默认的container的名字是空字符“”

但是最好还是用container block,如下
![]()
使用container的好处在于变量的名字可以保持nice和短,另一个好处便是:你可以容易的重置一个已经命名的container。以下代码连接到机器A上的server,让这个server重置名为my_problem_1的container,会把这个container所用的资源都释放掉(包括在这个server上打开的session)。假如你想重新使用这个container上的变量,必须重新初始化这个变量。
tf.Session.reset("grpc://machine-a.example.com:2222", ["my_problem_1"])资源容器(Resource containers)使得在多个session之间共享变量很容易。如下图,4个client在同一个cluster中运行4个不同的图,但是共享了一些变量。A,B共享了默认container的x,C,D共享my_problem_1这个container的变量x。值得注意的是,C同时公用了两个containers的x.

Asynchronous Communication Using TensorFlow Queues
queues(队列)也是一种在多个sessions中交换数据的方式。通常做法就是:使得一个client创建一个读取训练数据的图,然后把这个图放到queues中,另一个client创建一个取出数据的图,用来训练模型。这样可以加速训练过程,因为在每一步训练中不需要等待下一次的mini-batch。如下图

tensorflow中由很多queues,最简单的是frst-in frstout (FIFO) queue,以下代码创建了一个FIFO的queue,能够存储10个tensor,每个tensor包含两个float的值。
q = tf.FIFOQueue(capacity=10, dtypes=[tf.float32], shapes=[[2]],
name="q", shared_name="shared_q")假如需要在多个sessions中共享变量,你只需要在客户机两端设置相同的变量名字以及相同的container。在使用queues的时候,tensorflow不用name属性,而使用shared_name属性,当然也要使用相同的container。
Enqueuing data
为了把训练数据放入queue中,你需要创建一个enqueue(入队)操作,例如,以下代码把三个训练实例放到了queue中。

为了把训练例子一次都入队,使用enqueue_many

这两个例子都把3个tensor放入queue中,
Dequeuing data
把训练实例从queue中取出,需要使用dequeue操作。
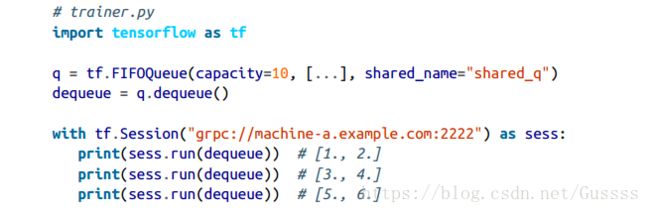
通常情况下,需要取出整个MIni-batch,而不是一个实例一个实例的取出,需要使用dequeue_many操作,指定mini_batch的尺寸。

当一个queque里满了,我们使用enqueue操作会被阻塞,直到dequeue操作把数组取出。同样的道理,假如使用dequeue操作时,queue中的项目是空的,那么dequeue会被阻塞,直到enqueue操作把新的数据放入queue。
Queues of tuples
每一个queue中的数据(item),可以是一个元组,元组里面是tensor。如下代码中,存储了两个tensor,一个是int32,shape为(),另一个tensor为float32,shape为[3,2]。
q = tf.FIFOQueue(capacity=10, dtypes=[tf.int32, tf.float32], shapes=[[],[3,2]],
name="q", shared_name="shared_q")这里需要注意enqueue操作需要给两个tensor,这两个tensor形成queue中的一个item,

如下代码创建了两个dequeue的操作
dequeue_a, dequeue_b = q.dequeue()通常,这两个操作也需要一起被执行

假如你只运行dequeue_a 这一个操作,那么还是会dequeue两个tensor,但是另一个tensor会丢失。
假如使用dequeue_many()函数,会返回两个items
batch_size = 2
dequeue_as, dequeue_bs = q.dequeue_many(batch_size)
with tf.Session([...]) as sess:
a, b = sess.run([dequeue_a, dequeue_b])
print(a) # [10, 11]
print(b) # [[[1., 2.], [3., 4.], [5., 6.]], [[2., 4.], [6., 8.], [0., 2.]]]
a, b = sess.run([dequeue_a, dequeue_b]) # blocked waiting for another pairClosing a queue
关闭队列可以向其他会话发出信号,表明不再需要对数据进行排队

使用了上面的语句,那么接下来的enqueue or enqueue_many会报错。默认情况下,等待入队(pending enqueue request)的请求都会被执行 ,除非你执行以下命令q.close(cancel_pending_enqueues=True)
dequeue 或者 dequeue_many(出队),只要queue中有items,那么就会执行。当queue的items少于一个mini-batch的时候,使用dequeue_many,queue中的数据会丢失。这时候,你可以使用dequeue_up_to,它和dequeue_many唯一不同的地方在于:当queue被关闭的时候,里面的items少于mini-batch,可以使用这条命令把里面所有的items取出。
RandomShuffleQueue
RandomShuffle Queue啊,在使用的时候可以像FIFOQueue一样,但是使用dequeue的时候,是随机顺序的。这样可以在训练的时候打乱一个epoch中训练实例的个数。
q = tf.RandomShuffleQueue(capacity=50, min_after_dequeue=10,
dtypes=[tf.float32], shapes=[()],
name="q", shared_name="shared_q")min_after_dequeue指定了在使用了dequeue操作之后,需要保留在queue中的items的数目。这可以保证queue拥有足够的实例个数来保证随机性(一旦queue关闭了,那么此参数会被忽略)。如下代码使用queue中有22个训练例子来说明。queue中items是从1到22的数字。
dequeue = q.dequeue_many(5)
with tf.Session([...]) as sess:
print(sess.run(dequeue)) # [ 20. 15. 11. 12. 4.] (17 items left)
print(sess.run(dequeue)) # [ 5. 13. 6. 0. 17.] (12 items left)
print(sess.run(dequeue)) # 12 - 5 < 10: blocked waiting for 3 more instancesPaddingFifoQueue
PaddingFIFOQueue使用和FIFOQueue一样,除了它接受一个 size可变的tensor,但是这个rank是固定的,例如(none,none),rank为2,size可变。然后当使用dequeue_many 和 dequeue_up_to的时候,里面的tensor会变成这个mini-batch中最大size的tensor,用0填充的方法。如下例
q = tf.PaddingFIFOQueue(capacity=50,
dtypes=[tf.float32], shapes=[(None, None)],
name="q", shared_name="shared_q")
v = tf.placeholder(tf.float32, shape=(None, None))
enqueue = q.enqueue([v])
with tf.Session([...]) as sess:
sess.run(enqueue, feed_dict={v: [[1., 2.], [3., 4.], [5., 6.]]}) # 3x2
sess.run(enqueue, feed_dict={v: [[1.]]}) # 1x1
sess.run(enqueue, feed_dict={v: [[7., 8., 9., 5.], [6., 7., 8., 9.]]}) # 2x4当使用dequeue命令一次只输出一个item的时候,输出尺寸和输入尺寸一样,但是当使用dequeue_many() 或者dequeue_up_to()的形式使item出队的时候,那么queue会自动填充tensor到合适的尺寸,例如下面代码,每次输出3个items,那么输出的每一个tensor都会被填充为3X4的tensor,找到最大的行和列。

这种queue在处理单词序列的时候非常有用,因为可以处理可变长度的输入。
Loading Data Directly from the Graph
到目前为止,我们假设client加载训练数据并使用占位符将其提供给集群。这样很不效率,因为有3点
- 从文件系统到client
- 从client到master task
- 从一个master task 到另一个需要数据的master task。
假如你使用同一组训练数据,使用几台clients来训练多个神经网络的话(目的是为了微调参数), 那会变得很糟糕。假如client同时加载数据,那么会使得file server或者网络的带宽饱和。
Preload the data into a variable
假如内存中能够存下数据集,那么一个好的做法为:只加载一次数据集,然后把数据集放到一个变量中,这种方法称为:预加载数据集(preloading the training set)。使用这种方法,这个数据集只会从client传送到cluster一次,但是在不同task之间,需要加载多次。以下代码告诉我们如何加载数据集。
training_set_init = tf.placeholder(tf.float32, shape=(None, n_features))
training_set = tf.Variable(training_set_init, trainable=False, collections=[],
name="training_set")
with tf.Session([...]) as sess:
data = [...] # load the training data from the datastore
sess.run(training_set.initializer, feed_dict={training_set_init: data})必须把trainable=False,这样optimizer才不会更新这个变量。并且需要把collections=[]设置为空,这样,这个变量才不会被添加到GraphKeys.GLOBAL_VARIABLES这个collection,中, GraphKeys.GLOBAL_VARIABLES这个collection用来保存和恢复变量的checkpoints,在11章取出模型的变量的时候会使用。
上面这个例子假设变量都是float32型的,如果不是这种情况,需要单独为每个变量设置类型。
Reading the training data directly from the graph
假如内存大小不够,不能容下训练集,那么通常做法为:使用reader操作:reader操作可以从文件系统中直接读取文件。使用read操作,数据不需要放到client之中。支持以下格式的数据
• CSV
• Fixed-length binary records
• TensorFlow’s own TFRecords format, based on protocol buffers
假设你有一个名为my_test.csv的文件,你想创建一个read操作来读取。这个csv种的内容如下

实现使用TextLineReader来读取这个文件,一旦我们告诉TextLineReader文件的路径,那么它就会一行一行的读。TextLineReader是一种有状态的操作,就像variable和queue一样,它在多次运行图的时候能保存状态,能够追踪当前阶段读取的是哪一个文件,以及读到了这个文件种的哪个位置(例如csv文件中的哪一行)。
reader = tf.TextLineReader(skip_header_lines=1)接下来,我们创建一个queue,这个queue的作用为:给reader文件的路径,让这个reader明白接下来需要读取文件的路径。并且,我们还创建了enqueue 操作和 一个 placeholder,用来传输文件的名字。最后创一个了一个关闭操作,假如不需要传入文件名字。
filename_queue = tf.FIFOQueue(capacity=10, dtypes=[tf.string], shapes=[()])
filename = tf.placeholder(tf.string)
enqueue_filename = filename_queue.enqueue([filename])
close_filename_queue = filename_queue.close()接下来创建一个read操作,用来读取一个record(在csv文件中就是一行),并且返回一个key/value的对。key是这一条record的唯一标识符(identifier):文件名的字符串+一个“:”+行的序号。value就是包含这行内容的字符串,
key, value = reader.read(filename_queue)最后一步,需要对value字符串进行解析,
x1, x2, target = tf.decode_csv(value, record_defaults=[[-1.], [-1.], [-1]])
features = tf.stack([x1, x2])第一行使用tensorflow的csv解析器来取出当前行的值,当一个field处于缺失状态(例如上图中的第三个例子中的x2)会使用默认值来进行填充(-1),默认值还被用来确定每个位置数字的类型(这里是两个float和一个Int)
接下来创建一个RandomShuffleQueue,这个RandomShuffleQueue会和训练图表共享,这样就可以从queue中取出mini-batch,当我们不需要向queue中传入数据的时候,我们关闭queue。
instance_queue = tf.RandomShuffleQueue(
capacity=10, min_after_dequeue=2,
dtypes=[tf.float32, tf.int32], shapes=[[2],[]],
name="instance_q", shared_name="shared_instance_q")
enqueue_instance = instance_queue.enqueue([features, target])
close_instance_queue = instance_queue.close()以上就是创建图的过程,现在run这个图
with tf.Session([...]) as sess:
sess.run(enqueue_filename, feed_dict={filename: "my_test.csv"})
sess.run(close_filename_queue)
try:
while True:
sess.run(enqueue_instance)
except tf.errors.OutOfRangeError as ex:
pass # no more records in the current file and no more files to read
sess.run(close_instance_queue)以上代码首先打开一个session,然后把my_test.csv这个文件enqueue到文件queue中,然后立即关闭了文件queue,因为不需要传入文件了。接下来创建一个无限训练来把训练实例一个接一个的enqueue到另一个queue,每次都运行enqueue_instance,这个操作依赖于key, value = reader.read(filename_queue)这条命令,所以运行这个enqueue_instance操作一次,就取出一对key/value,然后放入训练queue中。直到文件的最后一行。到了文件的最后一行之后,因为没有数据可以读取了,这个read操作会尝试读取文件queue中的下一个文件,因为这个文件queue已经关闭了,所以会抛出一个异常(OutOfRangeError),假如不关闭文件Queue的话,这个文件Queue会阻塞,直到我们让这个queue读取一个新的文件或者关闭它。最后我们关闭这个instance queue,让训练操作(向这个Queue取出mini-batch)不会被阻塞。所有过程如下图
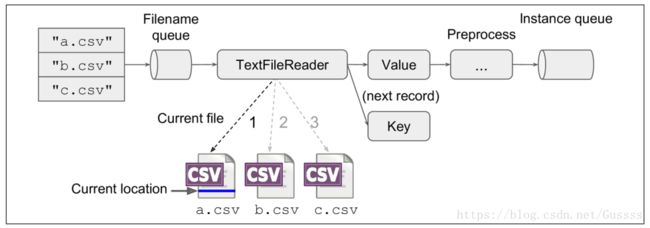
在训练过程中,需要创建一个和上面一样的instance queue,其实是共享了,用来pull mini-batch。
instance_queue = tf.RandomShuffleQueue([...], shared_name="shared_instance_q")
mini_batch_instances, mini_batch_targets = instance_queue.dequeue_up_to(2)
[...] # use the mini_batch instances and targets to build the training graph
training_op = [...]
with tf.Session([...]) as sess:
try:
for step in range(max_steps):
sess.run(training_op)
except tf.errors.OutOfRangeError as ex:
pass # no more training instances在这个例子中,第一个mini-batch中有两个训练例子,而第二个mini-batch只有一个训练例子,因为这个数据集里面只有3条数据。
tensorflow queue不能很好的处理稀疏矩阵,如果训练数据是稀疏矩阵,那么需要在instance queue之后进行解析。
上面的架构只用了一个thread来读取record.
Multithreaded readers using a Coordinator and a QueueRunner
为了使用多个threads来同时读取训练实例,可以使用python的threading 模块,然而tensorflow提供了一些工具,让创建threads变得简单,如Coordinator class 和 QueueRunner class。
coordinator用来协调停止多threads。
coord = tf.train.Coordinator()然后在循环中传入所有需要共同停止的threads,
while not coord.should_stop():
[...] # do something任意一个thread可以调用Coordinator’s request_stop()使得任意一个thread都停止,
coord.request_stop()每个thread只要已完成当前迭代就会停止。你可以通过调用Coordinator’s join()来等待所有的threads停止,只要传入一个thread的列表。
coord.join(list_of_threads)QueueRunner可以运行多个threads,每个thread重复运行一个enqueue操作以尽可能快的速度填充一个queue。一旦一个queue关闭了,那么下一个尝试push item到queue中的thread会产生一个异常(OutOfRangeError),当前thread迅速捕获异常,并且告诉其他的threads立即停止(使用Coordinator操作)。以下代码使用一个QueueRunner来管理5个同时读取训练实例的threads,并且把训练实例push到一个 instance queue中。
[...] # same construction phase as earlier
queue_runner = tf.train.QueueRunner(instance_queue, [enqueue_instance] * 5)
with tf.Session() as sess:
sess.run(enqueue_filename, feed_dict={filename: "my_test.csv"})
sess.run(close_filename_queue)
coord = tf.train.Coordinator()
enqueue_threads = queue_runner.create_threads(sess, coord=coord, start=True)第一行创建了一个QueueRunner实例,并且告诉这个实例运行5行相同的enqueue_instance操作。随后打开一个session,传入需要enqueue的csv文件名字,随后创建一个Coordinator,QueueRunner会使多个threads,重复运用Coordinator来停止threads.最后,我们让QueueRunner创建threads,并且使threads开始运行。接下来这些threads会读取所有的训练实例,并把训练实例push到instance queue中,之后所有的threads优雅的停止。
当前所有的threads都是从同一个文件中读取数据,我们可以通过创建多个readers来使这些threads从不同的文件中读取数据(假设训练数据存在于多个CSV文件中),如图

首先创建一个函数用来把训练数据push到instance queue中
def read_and_push_instance(filename_queue, instance_queue):
reader = tf.TextLineReader(skip_header_lines=1)
key, value = reader.read(filename_queue)
x1, x2, target = tf.decode_csv(value, record_defaults=[[-1.], [-1.], [-1]])
features = tf.stack([x1, x2])
enqueue_instance = instance_queue.enqueue([features, target])
return enqueue_instance随后定义读取文件的queue和push训练实例的queue
filename_queue = tf.FIFOQueue(capacity=10, dtypes=[tf.string], shapes=[()])
filename = tf.placeholder(tf.string)
enqueue_filename = filename_queue.enqueue([filename])
close_filename_queue = filename_queue.close()
instance_queue = tf.RandomShuffleQueue(
capacity=10, min_after_dequeue=2,
dtypes=[tf.float32, tf.int32], shapes=[[2],[]],
name="instance_q", shared_name="shared_instance_q")以下定义QueueRunner,与上面不同的是,这一次给了QueueRunner一个带着不同equeue operations的列表,列表中每一个operation都会使用一个不同的reader,所以多个线程可以从多个CSV文件中同时读取数据。
read_and_enqueue_ops = [read_and_push_instance(filename_queue, instance_queue) for i in range(5)]
queue_runner = tf.train.QueueRunner(instance_queue, read_and_enqueue_ops)如上代码首先把文件的名字push给read,然后创建一个Coordinator,随后创建并启动QueueRunner threads。这一次所有的threads将从不同的文件中同时读取数据,直到所有文件读取完毕。然后QueueRunner会关闭instance queue,以至于在其他操作把数据pull出来的时候不会阻塞。
Other convenience functions
在阅读训练实例时,TensorFlow还提供了一些方便的函数来简化一些常见的task
string_input_producer()接受一个1D的tensor,这个tensor为一个文件名的列表,能够创建一个thread,这个thread能够向文件queue每次传送一个文件名,最后关闭queue.
如果指定epoch的数目,那么在每次epoch都会遍历一边文件名。每次epoch都会shuffle文件名。string_input_producer()会创建一个QueueRunner来管理thread,会把thread添加到GraphKeys.QUEUE_RUNNERS这个collection中,为了启动collection中的每一个QueueRunner,可以调用tf.train.start_queue_runners()函数。假如没有启动QueueRunner,那么文件queue处于打开状态,并且是空的,readers会被永久阻塞。
shuffle_batch()这个函数接受一个包含tensor的列表,并且创建
- A RandomShuffleQueue
- A QueueRunner to enqueue the tensors to the queue (added to the GraphKeys.QUEUE_RUNNERS collection)
- A dequeue_many operation to extract a mini-batch from the queue
使得管理一个 multithreaded的输入管道(用作queue的输入),以及一个训练管道(用作从queue取出mini-batch)变得容易。
Parallelizing Neural Networks on a TensorFlow Cluster
One Neural Network per Device
最简单的在一个tensorflow cluster中来训练并运行多个神经网络方式的方法就是 取得在单device,单机器上运行的代码,当创建session的时候,指定master server的地址。你的代码会在server默认的device中运行。假如需要更改device,只需要在构建阶段把代码放在一个device块中(with块)
通过并行运行多个client sessions(在不同的threads或者processes中),使这些client sessions连接到不同的server中,配置client sessions以使用多个不同的devices,如下图。
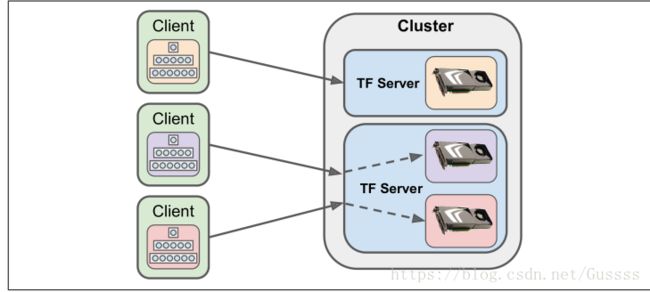
这样就可以轻易的并行训练和run神经网络,提升的速度基本是线性的,使用50个server,每个server带有两块GPU,训练100个神经网络的速度基本等于使用一块GPU训练一个神经网络。这种方式对寻找超参数尤其的有效,对于queries per second (QPS)(每秒查询)也很有效,假如你有一个网站服务器,每秒都接收查询,需要让你的神经网络对于每个query都进行预测,只需要简单的把你的神经网络复制到cluster中所有的devices中,并把所有的queries分配给所有的device,这样就基本可以无限量的qps了。另一种选择是使用tensorflow serving,使用机器学习的模型来处理大容量的queries。
In-Graph Versus Between-Graph Replication
你可以并行训练一个大型的神经网络集合(a large ensemble of neural networks),只需要把每个神经网络放在不同的device中,但是一旦你运行这个集合(ensemble),那么需要把每个神经网络的预测集中起来来完成整个的ensemble的预测,这需要一点协调能力。
有两种方法来处理一个神经网络的ensemble(或者是包含大量独立计算的图)。
in-graph replication:你可以创建一个大图,里面包含每一个神经网络,把每一个神经网络pin到不同device,还包含计算(从所有的神经网络中聚合单个预测所需的计算)。然后你只需要把session创建到cluster中的任意一个server中,让这个session处理所有的东西(包括等待让所有神经网络都输出预测值,在聚集它们之前waiting for all individual predictions to be available before aggregating them)。

between-graph replication:为每一个神经网络创建一个单独的图,并且自己处理图之间的同步性。一个典型的实现是使用queue来协调这些图的执行。一组客户端分别处理一个神经网络,从其专用的输入队列(input queue)读取数据,并将其写入其专用的预测队列(prediction queue)。另一个client负责读取输入并把所有的输入push到所有的input queues中(复制所有的输入到每个queue),最后一个client负责从每一个prediction queue中读取一个预测,然后把所有预测聚集起来,进行ensemble的预测。
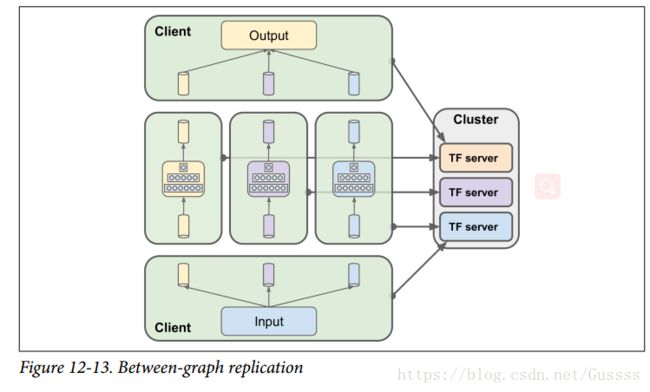
上面两种方法各有利弊。In-graph replication更容易实现,因为不需要管理多个clients和queues。between-graph replication
有利于组织成有良好限制且易于测试的模块(between-graph replication is a bit easier to organize into well-bounded and
easy-to-test modules),而且给了你一定的灵活性,例如在aggregator client中(上图下面哪个)可以添加一个出列超时(dequeue timeout)操作,这样ensemble就不会失败,即使其中一个神经网络崩溃了或者使用了很长的时间来预测。
tensorflow允许超时,通过引用run()函数的时候传入一个带着 timeout_in_ms的RunOptions ,如下代码
with tf.Session([...]) as sess:
[...]
run_options = tf.RunOptions()
run_options.timeout_in_ms = 1000 # 1s timeout
try:
pred = sess.run(dequeue_prediction, options=run_options)
except tf.errors.DeadlineExceededError as ex:
[...] # the dequeue operation timed out after 1s另一种设置超时的方法为:设置session的operation_timeout_in_ms配置选项,但是假如任意一个操作的用时比刚刚设置的timeou时间长,run()函数会超时。
config = tf.ConfigProto()
config.operation_timeout_in_ms = 1000 # 1s timeout for every operation
with tf.Session([...], config=config) as sess:
[...]
try:
pred = sess.run(dequeue_prediction)
except tf.errors.DeadlineExceededError as ex:
[...] # the dequeue operation timed out after 1sModel Parallelism
model parallelism:在多个devices中运行一个神经网络,需要你把单个神经网络分成不同 的部分,并且在不同的device上运行不同的部分。model parallelism的使用很由技巧,取决于你的神经网络的结构。对于fully connected net‐works,把这个网络拆分到不同的设备中可能不会带来多大的帮助。如图(虚线代表cross-device communication,这种通信是很慢的,)

对于卷积神经网络来说,卷积神经网络中的层只部分的连接到它前面的层,所以把网络分成多个块到devices中是非常效率的,如图
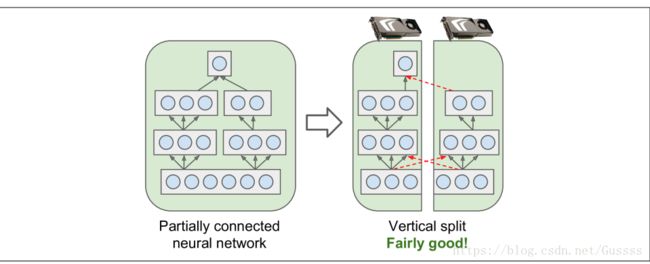
对于循环神经网络来说,因为每个细胞相当的复杂,使用分布式训练的效果可能能够弥补跨设备通信的惩罚。
最后一点:确保需要进行最多通信的设备在同一台机器上运行。
Data Parallelism
data parallelism: 另一种并行训练神经网络的方法就是把这个神经网络复制一下,放到每一个device中去,每次训练的过程是:使用不同的mini-batch对这些复制的神经网络进行同时训练,然后把梯度整合起来,用来更新模型的参数。

这种实现方式有两种,synchronous updates and asynchronous updates
Synchronous updates
使用这种方式进行更新的话,那么aggregator在计算梯度的平均值之前,会等待所有的梯度都变成available状态。在进行下一次的mini-batch之前,虽然已经进行了梯度的计算,但是必须等待aggregator,来进行参数的更新,缺点就是某些device可能运行的比其他的device慢,所以其他的device在训练的每一步都必须等待它们。另外,参数会同时复制进每一个device中,可能会使得参数Server的带宽饱和。
为了减少在每一次训练过程中的等待时间,可以忽略10%神经网络的梯度,例如你复制20个神经网络,但是在每次训练过程中,只整合其中最快的18个网络,忽略另外2个神经网络的梯度,这样一旦参数更新了,那么就可以让这18个网络继续运行了。
Asynchronous updates
当使用异步更新的时候,当一个replica(复制到一个device中的神经网络)计算完了梯度的时候,会立即使用梯度来进行参数的更新。把整合操作去除,也就是上图中的mean操作被去除了。每一个replica的运行都是独立的。因为不需要等待,所以这种方法的运行速度更快。虽然在训练的每一步都需要把参数复制到每一个device中去,但是不是同时发生的,减少了带宽饱和的风险。因为异步更新的简单性,没有同步延迟,能够有效的使用带宽,所以在实际中应用的也很多, 但是不能保证计算得到的梯度能够指向正确的方向。

当梯度严重超时,我们把这种stale gradients:会导致收敛变慢,因为参数服务器中只有一组参数,但是有很多个神经网络一起更新。解决stale gradients的方法有如下几种:
- 减少学习速率
- 把stale gradients丢弃或者scale它们
- 调整mini-batch的尺寸
- 使用几个epochs来只训练一个replica(warmup phase),在训练的初期阶段的梯度比较大并且参数没有呆在谷底,所以Stale gradients会破坏的比较严重。
Bandwidth saturation
无论您是使用同步更新还是异步更新,数据并行仍然需要在每个训练步骤开始时将模型参数从参数服务器传递到每个副本神经网络,在每个训练步骤结束时将梯度转移到另一个方向。不幸的是,这意味着添加额外的GPU根本不能提高性能,因为把数据移入移出GPU的RAM使用的时间超过了分解计算负载得到的加速率。
对于一些模型,特别是比较小并且训练于一个大型训练集的神经网络,最好使用一台单GPU的机器。
对于大密度模型来说,饱和更为严重,因为它们有很多参数和梯度要传递。对于小模型(并行增益很小)和大的稀疏模型来说,饱和现象没有那么严重,因为梯度通常是0,所以它们可以有效地进行通信。下面是一些加速的例子

超过一定数量的GPU,那么会出现饱和,性能会下降。 下面又几个方法来减少饱和现象
16位是训练神经网络的最低要求,但是可以在训练完之后把参数压缩到8位,这样有利于在移动端运行。
TensorFlow implementation
使用in-graph replication + 同步updates,您将构建一个包含所有模型副本(放在不同的设备上)的大图,以及一些节点来聚合它们的所有梯度并将它们提供给优化器。您的代码创建一个session指向cluster,并简单地重复地运行训练操作
使用n-graph replication + 异步 updates,你还是会创建一个大图,但是对于每一个神经网络的副本都用一个优化器,并为每一个神经网络的副本分配一个thread,重复的为每个神经网络的副本run优化器。
对于between-graph replication + 异步 updates,你运行多个独立的client,每一个client都训练一个神经网络的副本,但是参数是和其他神经网络共享的(使用resource container)。
对于With between-graph replication + 同步updates,您又一次运行多个客户机,每个客户机都基于共享的参数来训练一个模型副本,但是这次您将优化器(例如,一个MomentumOptimizer)封装在一个SyncReplicasOptimizer中。每个副本都使用这个优化器,这个优化器将梯度发送给一组queue(每个变量一个),由一个副本的 syncreasoptimizer读取,称为chief(指代的是Queue)。chief整合梯度并应用梯度,对每一个神经网络的副本的token queue写入一个token,表示它可以继续计算下一个梯度。这种方法支持拥有备用副本
Exercises
- 将gpu分组到几个服务器上,而不是分散到多个服务器上。这将避免不必要的网络跳跃。
- Shard the parameters across multiple parameter server
- 将模型参数从32位(tf.float32)降低到16位(tf.bfloat16)。
1.当出现CUDA_ERROR_OUT_OF_MEMORY的时候,是发生了什么?我们应该怎么作?
因为tensorflow程序一旦运行,会抓取所有可见GPU上的所有可用内存,当出现CUDA_ERROR_OUT_OF_MEMORY这个问题的时候很可能一个程序正在运行,并至少抓取了一个GPU上的所有内存,很有可能是因为另一个tensorflow程序。
- 最简单的解决方法为:把这个程序关了。
- 假如你需要所有的程序并行运行,那么你可以把不同的devices分配给每一个进程,通过设置每个device的环境变量CUDA_VISIBLE_DEVICES。
- 配置tensorflow,只让tensorflow调用一部分的GPU资源而不是全部GPU资源,创建一个ConfigProto,然后设置它的gpu_options.per_process_gpu_memory_fraction(例如0.4),最后打开session的时候使用ConfigProto
- 最后一种方法为只在tensorflow需要内存的时候才让tensorflow抓取内存,通过设置gpu_options.allow_growth为真。这种方法一般不推荐,因为tensorflow抓取的内存是不会归还的,很难保证一个重复的行为,因为存在竞争条件,比如哪一个进程先开始,训练时需要的内存数量。
2.把operation pin 在device上和把operation place在device上有什么区别。
把一个operation pin在一个device上,意味着告诉tensorflow这个operation将要place的地方,但是某些限制可能会阻止tensorflow不把operation放在对应地方,例如operation可能会没有对应device的implementation(kernel),一般情况会产生一个exception,可以配置tensorflow让这个操作会到cpu中(soft placement)。另一个例子是可以修改变量的操作(pin这个操作没有修改变量,而place修改了),这个操作和变量需要被collection。pinning an operation and placing an operation的区别在于pin只是告诉tensorflow需要这么干,而place让tensorflow实际干了这个.
3.If you are running on a GPU-enabled TensorFlow installation, and you just use the default placement, will all operations be placed on the first GPU?
假如每一个操作都有一个GPU对应的implementation(GPU kernel),那么确实会放在第一个GPU上,但是假如没有GPU对应的kernel,那么就会放到CPU中。
4.If you pin a variable to "/gpu:0", can it be used by operations placed on /gpu:1?Or by operations placed on "/cpu:0"? Or by operations pinned to devices loca‐ted on other servers?
都可以,tensorflow会自动添加合适的操作来把变量的值转移到不同的devices中。
5.Can two operations placed on the same device run in parallel?
tensorflow可以并行的运行操作(放在不同的CPU cores中或者不同的GPUthreads中),只要不是某一个操作依赖另一个操作的输出。更一般的,你可以在并行的threads中开启多个session,并在每个thread中评估操作。因为每一个session都是独立的,TensorFlow will be able to evaluate any operation from one session in parallel with any operation from another session
6.What is a control dependency and when would you want to use one?
control dependency被用在:你想延缓操作X的评估,直到某些操作运行了才评估X,即使操作X不需要这些操作来计算。实际中很有用,因为假如X会用很多的内存,而你只想要在计算图的后面才用到的话。或者X会用到很多的I/O(比如从另一个device或者service中调用值),你不想X于其他I/0操作冲突,使得带宽饱和。
7.suppose you train a DNN for days on a TensorFlow cluster, and immediately after your training program ends you realize that you forgot to save the model using a Saver. Is your trained model lost?
在分布式的tensorflow中,变量的值存在于由cluster管理的容器(container)中,如果你关闭了session,并且退出了client程序,模型的参数还是会存在于cluster中,这时候需要在cluster中打开一个session,并存储模型(确保不能初始化以及恢复,这讲会破坏模型),