Basic Crawler Part 1
Basic Crawler Part 1
Here is the fundamentals of writing a simple crawler based on python. The aim of this blog is to serve as a reference for similar beginners. The tips and possible mistakes are listed below.
Limited by programming ability of author, feel free to point out any mistakes if you found.
Be kind, please.
The part 1 includes:
- Requests module;
- How to save a file;
1. Requests Module
Requests is a module used to extract information from the website entered as input. Here is a simplest example to extract information from a known url.
import requests
url='https://news.sina.com.cn/c/2018-12-10/doc-ihprknvu0188659.shtml'
response=requests.get(url)
response.encoding='utf-8'
print(response.text)
Tips: 1. Be cautious on encoding scheme of the file. In the upper case, without setting encoding as utf-8 result will lose chinese characters since IDE choose ‘iso-8859-1’ as encoding scheme. (see as below)
import requests
url='https://news.sina.com.cn/c/2018-12-10/doc-ihprknvu0188659.shtml'
response=requests.get(url)
#response.encoding='utf-8'
print(response.text)
result:

if we add response.encoding=‘utf-8’
import requests
url='https://news.sina.com.cn/c/2018-12-10/doc-ihprknvu0188659.shtml'
response=requests.get(url)
response.encoding='utf-8'
print(response.text)
result:
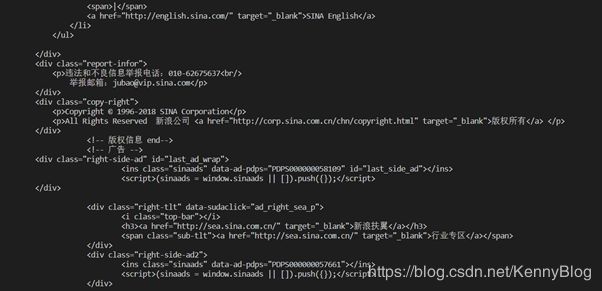

more about encoding scheme and charsets:
https://zhuanlan.zhihu.com/p/51828216
2 . How to save a file
2.1 With function
with open('sample.txt', 'w+') as f:
f.write(response.content)
is equivalent to:
f=open("sample.txt','w+)
f.write(response.content)
f.close()
2.2 About expressions
import requests
import re
url = 'https://news.sina.com.cn/c/2018-12-10/doc-ihprknvu0188659.shtml'
result=requests.get(url)
with open('example test','wb+') as f:
f.write(result.content)
title=re.findall(r'title>(.*?)<',result.content.decode('utf8'))
print(title)
2.2.A The attributes content and text
content: write into the file in the form of data stream,
text: write into the file in the form of string,
** so as for text, the platform would decode the data stream into text through specific decoding scheme, if default scheme used by platform is different from the scheme used by original website, the error is caused **
so the following codes can both write into file successfully:
A
import requests
import re
url = 'https://news.sina.com.cn/c/2018-12-10/doc-ihprknvu0188659.shtml'
result=requests.get(url)
with open('example test','wb+') as f:
f.write(result.content)
B
import requests
import re
url = 'https://news.sina.com.cn/c/2018-12-10/doc-ihprknvu0188659.shtml'
result=requests.get(url)
with open('example test','w+',encoding='utf8') as f:
response.encoding='utf8'
f.write(result.text)
2.2.B The mode for open function
1. w+ v.s r+
similarities: both write and read available
differences: w+ puts point at begin of text; r+ puts point at the end
** w v.s a**
similarities: both write available
differences: w puts point at begin of text; a puts point at the end
w v.s wb
similarities: both write available
difference: w puts text ,e.g '你好‘, response.text; wb puts binary data stream, eg. response.content, '你好’.encode(‘utf8’)