Hadoop Yarn 资源调度器解析篇
Yarn资源调度器简介
资源调度器是Yarn中最核心的组件之一,他是ResourceManager中的一个可插拔的服务组件,负责整个集群的管理和分配;
目前Yarn中的作业类型:
1.批处理作业,这种作业比较耗时,对时间的完成没有严格要求,如数据挖掘和机器学习等;
2.交互式作业,这种作业一半希望能够及时的返回结果,例如:hive的sql查询;
3.生产性作业:这种作业要求有一定量的资源保证,如统计值计算,垃圾数据分析等;
为了满足多用户多队列的资源分配问题以及Yarn自带的FIFO(先进先出资源调度器)单队列的问题,又引入了Yahoo的Capacity Scheduler和FaceBook的Fair Scheduler;
Yarn的资源调度器的基本架构
资源调度器作为Yarn中的可插拔的资源调度器,它定义了一套接口规范以便用户可按照规范实现自己的调度器,本文主要从资源调度器的可插拔性和时间处理器两方面来说;
1.ResourceScheduler之插拔式组件
在ResourceManager初始化的时候会根据用户的配置来创建一个具体的资源调度对象,通过配置文件yarn.resourcemanager.scheduler.class指定,如下代码:
protected ResourceScheduler createScheduler() {
String schedulerClassName = conf.get(YarnConfiguration.RM_SCHEDULER,
YarnConfiguration.DEFAULT_RM_SCHEDULER);
LOG.info("Using Scheduler: " + schedulerClassName);
try {
Class schedulerClazz = Class.forName(schedulerClassName);
if (ResourceScheduler.class.isAssignableFrom(schedulerClazz)) {
return (ResourceScheduler) ReflectionUtils.newInstance(schedulerClazz,
this.conf);
} else {
throw new YarnRuntimeException("Class: " + schedulerClassName
+ " not instance of " + ResourceScheduler.class.getCanonicalName());
}
} catch (ClassNotFoundException e) {
throw new YarnRuntimeException("Could not instantiate Scheduler: "
+ schedulerClassName, e);
}
}
资源调度器的实现必须实现ResourceScheduler接口,代码如下:
@LimitedPrivate("yarn")
@Evolving
public interface ResourceScheduler extends YarnScheduler, Recoverable {
/**
* Set RMContext for ResourceScheduler.
* This method should be called immediately after instantiating
* a scheduler once.
* @param rmContext created by ResourceManager
*/
void setRMContext(RMContext rmContext);
/**
* Re-initialize the ResourceScheduler.
* @param conf configuration
* @throws IOException
*/
void reinitialize(Configuration conf, RMContext rmContext) throws IOException;
}
而ResourceScheduler实现了YarnScheduler接口,代码如下:
public interface YarnScheduler extends EventHandler {
/**
* Get queue information
* @param queueName queue name
* @param includeChildQueues include child queues?
* @param recursive get children queues?
* @return queue information
* @throws IOException
*/
//todo 获取一个队列信息
@Public
@Stable
public QueueInfo getQueueInfo(String queueName, boolean includeChildQueues,
boolean recursive) throws IOException;
/**
* Get acls for queues for current user.
* @return acls for queues for current user
*/
//todo 返回当前用户的队列Acl权限
@Public
@Stable
public List getQueueUserAclInfo();
.......
2.ResourceScheduler之事件处理器
Yarn的资源管理器实际上是一个事件处理器,他需要处理来自外部不同的事件,如下图所示:
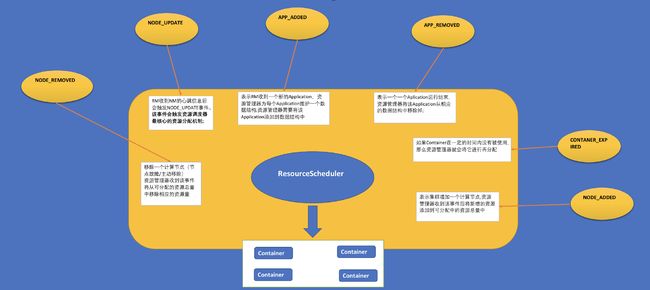
资源表示模型
当前Yarn支持内存和CPU两种资源类型的管理和分配,同MR1一样,Yarn采用了动态资源分配机制,NM会向RM注册,注册信息里包含了该节点可分配的CPU和内存总量;
这两个值是可以配置的:
yarn.nodemanager.resource.memory-mb : 可分配的物理内存总量,默认8G;
yarn.nodemanager.vmem-pmem-ratio : 使用单位物理内存可分配的虚拟内存量,默认2.1;
yarn.nodemanager.resource.cpu-vcores: 可分配虚拟CPU的个数,默认是8;
Yarn支持的调度语义:
- 请求某个特定节点上的特定资源量: 例如请求nodex节点上5个 2vcpu,2GB的Container;
- 请求某个特定机架上的特定资源量: 例如请求rackx上的3个 4vcpu,2GB的Container;
- 将某些节点加入或者移除黑名单,不再为自己分配这些节点上的资源;
- 请求归还某些资源,例如ApplicationMaster将闲置的Container归还给集群;
不支持的调度语义:
- 请求任意节点上的特定资源量: 例如请求任意节点上5个 2vcpu,2GB的Container;
- 请求任意机架上的特定资源量: 例如请求同一机架上的3个 4vcpu,2GB的Container;
- 请求一组或者几组符合某种特质的资源,例如请求两个机架上的4个2vcpu,2GB的Container和4vcpu,2GB的Container,如果集群中没有则需要从其他应用程序抢占资源;
- 超细粒度的资源: 例如CPU性能要求,绑定CPU;
- 动态调整Container资源,应允许根据需要冬天调整Container资源量;
资源调度模型
1.双层资源调度模型
在第一层中,ResourceManager中的资源调度器将资源分配给各个ApplicationMaster;
在第二层中,ApplicationMaster再进一步将资源分配给它内部的各个任务
第一层的调度模型如下图所示:
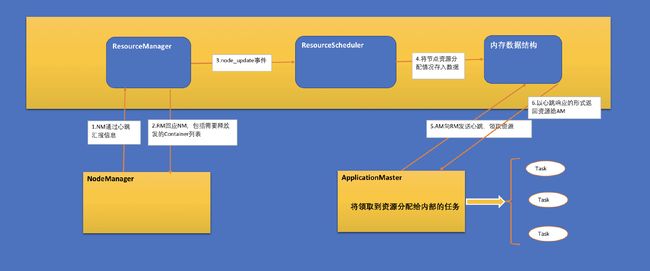
2.资源保证机制
在分布式计算中,资源调度器需要选择合适峰资源保证这样的机制,当应用程序申请的资源暂时无法保证时:
1.是优先为应用程序预留一个节点上的资源直到累计释放的空闲资源满足应用程序需求(称为“增量资源分配”)
2.还是暂时放弃当前资源直到出现一个节点剩余资源一次性满足应用程序需求(称为“一次性资源分配”)
这两种机制均存在优缺点,对于增量资源分配来说,资源预留会导致资源浪费,降低集群资源利用率;而一次性资源分配则会产生饿死现象,即应用程序可能永远等不到满足资源需求的节点出现,YARN采用了增量资源分配机制 ,尽管这种机制会造成浪费,但不会出现饿死现象;
3.资源分配算法
为了支持多维资源调度,YARN资源调度器采用了主资源公平调度算法(DRF),该算法扩展了最大最小公平算法,使其能够支持多维资源的使用在DRF算法中,将所需份额(资源比例)最大的资源称为主资源,而DRF的基本设计思想则是将最大最小公平算法应用于主资源上,进而将多维资源调度问题转化为单资源调度问题,即DRF总是最大化所有主资源中最小的;
资源抢占模型
在资源调度器中,每个队列可设置一个最小资源量和最大资源量,其中,最小资源量是资源紧缺情况下每个队列需保证的资源量,而最大资源量则是极端情况下队列也不能超过的资源使用量。资源抢占发生的原因则完全是由于“最小资源量”这一概念;
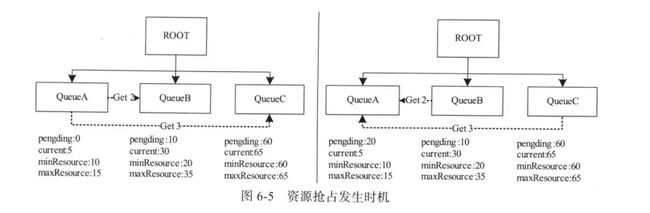
资源调度器之Capacity Scheduler
Capacity Scheduler是Yahoo开发的多用户调度器,它以队列为单位,每个队列可设定一定比例的资源最低保证和使用上限,同时每个用户也可以设定一定的资源使用上限以防止资源滥用。当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列;
Capacity Scheduler特点:
- 容量保证:管理员可以为每个队列设置资源的最低保证和使用上限,而所有提交到该队列的应用程序共享这些资源;
- 灵活性: 当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列,一旦该队列有闲的应用程序提交,则其他队列释放的资源会归还该队列;
- 多重租赁: 支持多用户共享集群和多应用程序同时运行;
- 安全性保证: 每个队列都有严格的ACL列表规定他的访问用户;
- 动态更新配置文件: 管理员可根据需要动态修改各种配置参数,以实现集群的在线管理;
Capacity Scheduler配置参数
1.资源分配相关参数
capacity: 队列的容量(百分比)
maximum-capacity: 队列资源的使用上限(百分比)
minimum-user-limit-percent:每个用户最低资源保障(百分比)
user-limit-factor: 每个用户最多可使用的资源量(百分比)
2.限制应用程序数目的配置参数
maximum-applications: 集群或者队列总同时处于等待和运行状态的应用程序数目上限,默认10000
maximum-am-resource-percent: 集群中用于运行应用程序ApplicationMaster的资源比例上限,
该参数通常用于限制处于活动状态的应用程序的数目,默认0.1(10%)
3.队列访问和权限控制参数
state: 队列状态stopped/running,可以实现队列的优雅退出
acl_submit_application: 限定哪些用户或者用户组可向给定的队列中提交应用程序,具有继承性
acl_administer_queue: 为队列指定一个管理员
其他的配置参数点击配置文件来查看;
从以上参数可见,Capacity Scheduler将整个系统资源划分为若干个队列,并且每个队列有较为严格的资源控制,通过这些控制Capacity Scheduler将hadoop集群在逻辑上划分为多个拥有相对独立资源的子集群,而这些子集群可以共享大集群的资源;
Capacity Scheduler的实现
1.应用程序的初始化:
应用程序提交到RM上后,RM会向Capacity Scheduler发送一个APP_ADDED事件,Capacity Scheduler收到之后会创建一个FiCaschedulerApp对象用于跟踪和维护该应用程序的运行时信息,同时将该应用程序提交给对应的叶子队列;
2.资源调度
当RM收到来自NM的心跳信息后,会想Capacity Scheduler发送NODE_UPDATE事件,而Capacity Scheduler接收到该事件之后会完成以下操作:
(1)处理心跳信息
NM发送的心跳信息中有两类信息需要资源资源调度器处理,一类是新启动Container,另一类是运行完成的Container,具体如下:
新启动的Container: 资源调度器需要向RM发送一个RMContainerEventType.LAUNCHED事件,进而将该Container从超时队列中移除;
运行完成的Container: 资源调度器将回收它的资源,然后资源再分配;
(2)资源分配
用户提交应用程序后,应用程序会为对应的ApplicationMaster申请资源,而资源的表示方式是Container,Container表示信息如下图所示:

Yarn采用了三级资源分配策略,当一个节点上有空闲资源的时候,它会依次选择队列,应用程序,Container使用该资源,如下图所示:
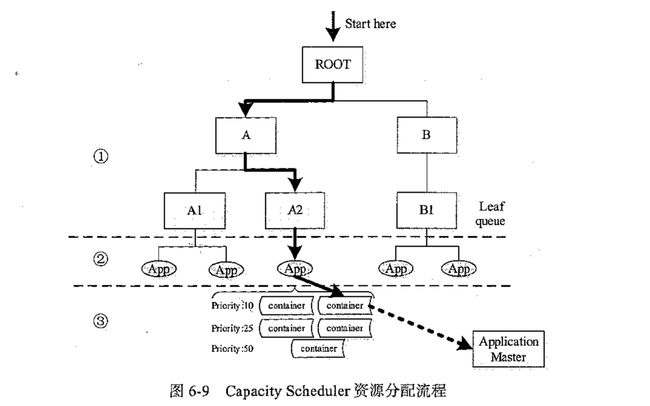
步骤一: Yarn采用层次结构组织队列,将队列转换成树形结构,从根节点开始按照子队列的资源使用率从小到大遍历各个子队列,如果子队列是叶子节点,则进行步骤二寻找合适的Container,否则以该子队列为根节点重复以上过程;
步骤二: 步骤一选中一个叶子节点后Capacity Scheduler会按照应用程序的提交顺序进行排序,并遍历排序后的应用程序找到一个或者多个最合适的Container;
步骤三: 当步骤二选中给一个应用程序后,Capacity Scheduler将先满足优先级较高的Container,对于同一优先级的Container根据本地性来选择,它会一次选择node local,rack local和no local的Container;
资源调度器之Fair Scheduler
Fair Scheduler简介
Fair Scheduler是FaceBook开发的多用户调度器,同Capacity Scheduler类似,它以队列为单位划分资源,每个队列可以设置一定比例的资源最低保证和使用上限,同时每个用户也可设定一定的资源使用上限以防止资源滥用,当一个队列有资源剩余的时候可以共享给其他队列,Fair Scheduler和Capacity Scheduler的不同之处如下:
资源公平共享: 在每个队列中,Fair Scheduler可根据选择按照FiFO,Fair和DRF策略为应用程序分配资源,其中Fair策略是根据一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列都按照该方式分配资源,如果一个队列中有两个应用程序,则每个应用程序可得到1/2的资源;
支持资源抢占: 当某个队列中有剩余资源时,调度器会将这些资源共享给其他队列,而当该队列中有新的应用程序提交时,调度器要为它回收资源,为了降低不必要的计算浪费,调度器会采用先等待再回收的策略,如果等待一段时间后未归还,则从哪些超额使用资源的队列中杀死一部分任务,进而释放资源;
负载均衡: Fair Scheduler提供了一个基于任务数目的负载均衡机制,该机制尽可能的将系统总的任务均匀分配到各个节点;
提高小应用的相应时间: 由于采用最大最小公平算法,小应用可以快速获取资源并运行完成;
Fair Scheduler中添加了新特性,点击配置文件来查看;
Fair Scheduler的实现
Fair Scheduler的实现和Capacity Scheduler基本一致,同Capacity Scheduler不同的是Fair Scheduler提供了更多样化的调度策略,它允许每个队列单独配置调度策略,分别有:FIFO,Fair和DRF;
调度策略在队列间和队列内部可以单独设置,对于叶子队列,他设置的调度策略决定了内部的应用程序的调度策略,对于非叶子节点,他设置的调度策略决定了各个子队列间的调度策略;
同Capacity Scheduler一样,Fair Scheduler也采用了三级资源分配策略,即当一个节点有空闲资源时,它会依次选择队列,应用程序,Container,这里就不再重复叙述;
其实Yarn采用的层次结构组织队列,实际存放应用程序的只有叶子队列,其他队列只是一个逻辑概念,用以辅助计算叶子队列的资源量;
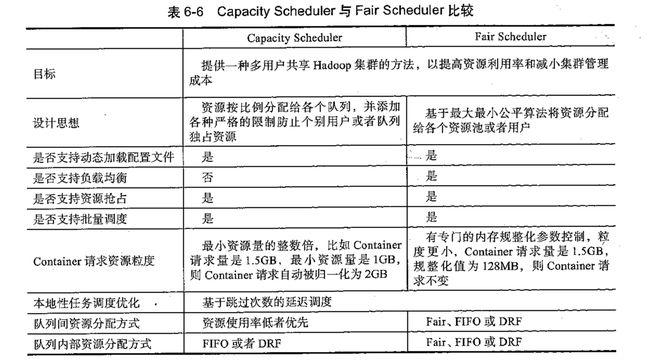
Capacity Scheduler和Fair Scheduler的比较
参考:
《Hadoop技术内幕 : 深入解析YARN架构设计与实现原理》