机器学习:模型评估指标
一、错误率和准确率
from sklearn.metrics import accuracy_score
print('准确率',accuracy_score(y_true,y_pred,normalize=True))
print('正确分类的数量',accuracy_score(y_true,y_pred,normalize=False))
二、精度和召回率
1.混淆矩阵


from sklearn.metrics import confusion_matrix
confusion_matrix(y_true,y_pred)
2.精度(查准率)和召回率(查全率)
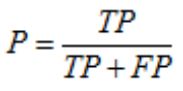

from sklearn.metrics import precision_score
precision_score(y_true,y_pred)
from sklearn.metrics import recall_score
recall_score(y_true,y_pred)
3.F1和Fβ
β越大,召回率比重越大
![]()
![]()
from sklearn.metrics import f1_score
f1_score(y_true,y_pred)
from sklearn.metrics import fbeta_score
fbeta_score(y_true,y_pred,beta=0.001)
4.对数损失(Log-loss)
分类输出不是类别,而是类别的概率,使用对数损失函数进行评价
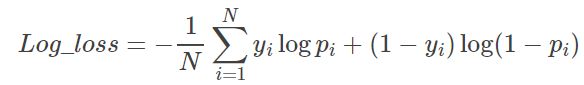
from sklearn.metrics import log_loss
model.predict_proba()
log_loss(y_true,y_pred)
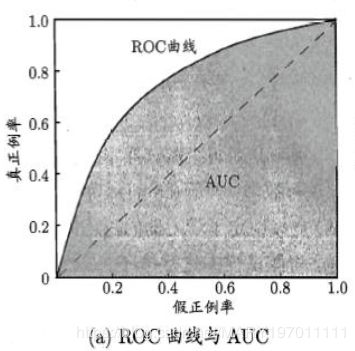
三、二分类指标:ROC和AUC
- 1.AUC表示当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率,越大越好。
- 2.优点:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。
![]()
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc,roc_auc_score
fpr, tpr, thresholds = roc_curve(test, pred)
roc_auc = auc(fpr, tpr)
roc_auc_score(test, pred)
#画图,只需要plt.plot(fpr,tpr),变量roc_auc只是记录auc的值,通过auc()函数能计算出来
plt.plot(fpr, tpr, lw=1, label='ROC(area = %0.2f)' % (roc_auc))
plt.show()
#分类报告,包含precision、recall、f1-score、support
from sklearn.metrics import classification_report
classification_report(y_true,y_pred,target_names=["class_0","class_1"])
四、回归问题指标
1.平均绝对误差MAE
- L1损失范数
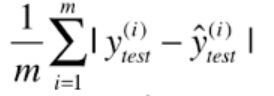
2.均方误差MSE—对应于欧式距离
-
L2损失范数
-
RMSE和MAE有局限性:同一个算法模型,解决不同的问题,不能体现此模型针对不同问题所表现的优劣。因为不同实际应用中,数据的量纲不同,无法直接比较预测值,因此无法判断模型更适合预测哪个问题。
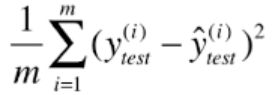
3.均方根误差RMSE -
在MSE基础上,保证量纲一致
-
对异常值敏感
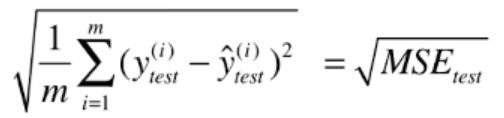
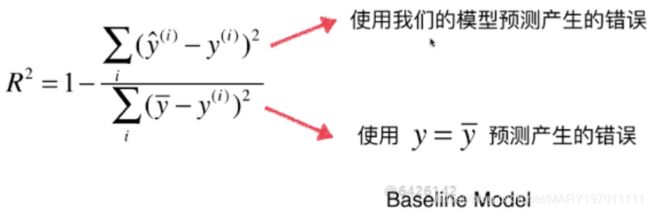
4.决定系数R^2
-
R^2值越大越好,但不超过1。针对不同问题的预测准确度,可以比较并来判断此模型更适合预测哪个问题。
-
对异常值敏感
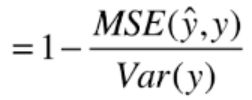
-
baseline model与X无关,所有值都是y的均值
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
MAE = mean_absolute_error(y_true, y_predict)
MSE = mean_squared_error(y_true, y_predict)
RMSE = np.sqrt(MSE)
from sklearn.metrics import r2_score
r2_score = 1 - mean_squared_error(y_true, y_predict) / np.var(y_true)
五、交叉验证的综合指标
from sklearn.model_selection import cross_val_score
'''
(1)scoring: 打分参数
分类:‘accuracy’、‘f1’、‘precision’、‘recall’ 、‘roc_auc’、'neg_log_loss'
回归:‘neg_mean_squared_error’、‘r2’
聚类:'adjusted_rand_score'、'completeness_score'
'''
scores = cross_val_score(model, X, y=None, scoring=None, cv=None, n_jobs=1)
scores.mean()