初识Solr搜索引擎
需求:首页的搜索功能,需要根据搜索条件进行分词,查询出需要的结果,然后将分词高亮显示
文章目录
- 下载并测试Solr
- 下载配置
- Java测试
- Solr在项目中的应用
- 分词器
- managed-schema
- 整合SSM
- Tomcat运行Solr
下载并测试Solr
下载配置
1.官网下载:地址
2.将压缩包解压到自定义目录,命令提示符窗口进入到 solr-7.3.1\bin 目录下,通过 solr start 命令,启动 Solr 服务;访问端口为8983,可以通过 127.0.0.1:8983 访问 Solr 网页
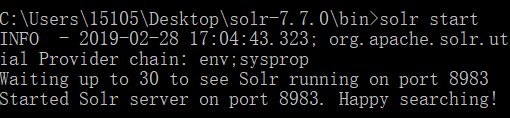
注:重启命令 :solr restart -p 8983
3.创建索引库:solr create -c firstcore,firstcore是索引库的名字;刷新网页,能看到我们创建的索引库

Java测试
Java 就是通过 Solrj 来操作 Solr 的。它提供了一些增、删、改、查的方法。
1.在 pom.xml 中引入依赖 solr-solrj
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.3.0</version>
</dependency>
2.spring配置文件applicationContext-solr.xml管理
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="httpSolrClient" class="org.apache.solr.client.solrj.impl.HttpSolrClient">
<constructor-arg name="builder" value="http://localhost:8983/solr/firstcore"/>
bean>
beans>
3.创建测试类:TestSolrJ.java
使用对象:SolrClient(HttpSolrClient)、SolrInputDocument
@ContextConfiguration(locations = {"classpath:applicationContext-solr.xml"})//加载spring配置文件
public class TestSolrJ extends AbstractJUnit4SpringContextTests {//继承测试基类
@Autowired
private SolrClient solrServer;//通过spring注入SolrClient对象
@Test
public void testSave() throws Exception {
//1.创建一个文档对象
SolrInputDocument inputDocument = new SolrInputDocument();
inputDocument.addField( "id", "10" );
inputDocument.addField( "item_title", "hello solr" );
inputDocument.addField( "item_image", "...." );
inputDocument.addField( "author", "moke" );
//2.将文档写入索引库中
solrServer.add( inputDocument );
//3.提交
solrServer.commit();
}
}
4.运作测试类,访问 Solr 网页,执行Execute Query,能够看到我们添加到索引库的数据
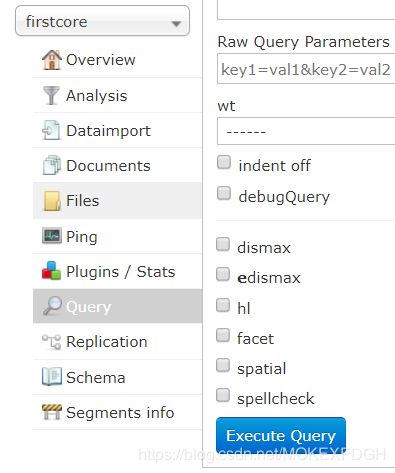
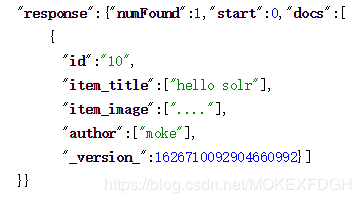
5.由上图可知查询出来的结果除了 id 都是 ArrayList 集合形式 [],如果取值的话转换起来会很麻烦,所以需要对solr-7.7.0\server\solr\firstcore\conf\目录下的managed-schema配置文件进行修改:

属性解释:
name:字段的名字
type:字段的数据类型
multiValued:是否有多值,有多值时设置为 true,否则设置为 false
indexed:是否创建索引
required:是否必须
stored:是否存储数据,如果设置为 false 则不存储,结合 docValues=“false” 使得查询不返回结果
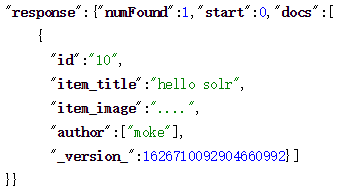
修改:将type类型由text_general改为String

重启solr,再次查询:
Solr在项目中的应用
分词器
Solr 可通过自带的分词器 smartcn 或者第三方分词器 IKAnalyzer 来实现,smartcn逐个字分词,而IK是按照词语分词
添加IK分词器步骤:
- 下载 IKAnalyzer 分词器 Jar 包
- 压缩包解压后,将其中的两个 Jar 包放入 solr-7.7.0\server\solr-webapp\webapp\WEB-INF\lib 下
- 配置 solr-7.7.0\server\solr\mycore\conf 下的 managed-schema 文件,添加分词器和需要分词的字段
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
fieldType>
managed-schema
- 对需要分词的字段修改其 type,例如标题需要分词:
<field name="title" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
- 配置其它字段名和类型,否则会查询出集合类型的数据:
<field name="comment_num" type="string"/>
<field name="category" type="string"/>
...
整合SSM
- 在 web.xml 中引入 applicationContext-solr.xml 配置文件
<context-param>
<param-name>contextConfigLocationparam-name>
<param-value>
...
classpath:applicationContext-solr.xml
param-value>
context-param>
- 在Service层的实现类SolrServiceImpl中添加查询方法:
使用对象:HttpSolrClient、SolrQuery、QueryResponse
@Autowired
HttpSolrClient solrClient;//注入HttpSolrClient
@Override
public Page<UserContent> findByKeyWords(String keyword, Integer pageNum, Integer pageSize) {
SolrQuery solrQuery = new SolrQuery( );//创建Solr查询条件对象
//设置查询条件
solrQuery.setQuery( "title:"+keyword );//keyword为jsp页面传递过来的查询条件
//设置高亮
solrQuery.setHighlight(true);
solrQuery.addHighlightField( "title" );
solrQuery.setHighlightSimplePre( "" );
solrQuery.setHighlightSimplePost( "" );
//分页
if (pageNum == null || pageNum < 1) {
pageNum = 1;
}
if (pageSize == null || pageSize < 1) {
pageSize = 7;
}
solrQuery.setStart( (pageNum-1)*pageSize );
solrQuery.setRows( pageSize );
//开始查询
try {
QueryResponse response = solrClient.query(solrQuery);//通过条件查询索引库
//通过查询结果获得高亮数据集合
Map<String,Map<String, List<String>>> highlighting = response.getHighlighting();
//通过查询结果获得结果集
SolrDocumentList resultList = response.getResults();
//通过结果集获得总数量
long totalNum = resultList.getNumFound();
List<UserContent> list = new ArrayList<UserContent>();
for(SolrDocument solrDocument:resultList){
//创建文章对象
UserContent content = new UserContent();
//通过结果集获取查询到的所有信息
String id = (String) solrDocument.get("id");
Object commentNum = solrDocument.get("comment_num");
Object category = solrDocument.get( "category" );
//取得高亮数据集合中的文章标题
Map<String, List<String>> map = highlighting.get(id);
//通过id获取相应文章的高亮部分的集合
String title = map.get("title").get(0);
//获取高亮部分的第一个即标题(还有文章内容等包含keyword的高亮部分)
//将获取到的信息都封装到对象中,并把对象添加进List集合
content.setId( Long.parseLong(id) );
content.setCommentNum( Integer.parseInt( commentNum.toString() ) );
content.setCategory( category.toString() );
content.setTitle( title );//将获得的高亮标题封装进对象,即带有span标签
list.add(content);
}
//将查询到的数据通过分页插件分页,返回分页对象page
PageHelper.startPage(pageNum, pageSize);//开始分页
PageHelper.Page page = PageHelper.endPage();//分页结束
page.setResult(list);
page.setTotal(totalNum);
return page;
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
注:
1.调用此查询方法前,需要通过SolrInputDocument和HttpSolrClient 将数据先添加进索引库(详见Java测试)
2.其它对相关对象的增删改操作的同时,需要对索引库也进行增删改,即controller中除了调用相关Service的增删改方法,还需要调用SolrService的增删改方法
Tomcat运行Solr
默认 Solr 是在 Jetty 服务器下运行的,改为tomcat上运行步骤:
- 将 solr-7.7.0\server\solr-webapp 下的 webapp 文件复制到 Tomcat 的 webapps 目录下,并重命名为 Solr
- 将 solr-7.7.0\server\lib\ext 目录下的所有 Jar 包复制到刚才重命名的 solr\WEB-INF\lib 下
- 将 solr-7.7.0\server\lib 下以 metrics 开头的5个 Jar 包也复制到刚才重命名的 solr\WEB-INF\lib 下
- 在刚才重命名的 solr\WEB-INF 下新建 classes 文件夹,并将 solr-7.7.0\server\resources 下的 log4j.properties 文件复制到刚刚新建的 classes 文件夹下
- 将 solr-7.7.0\server 目录下的 Solr 文件夹复制到自定义路径下,然后重命名为 solr_home
- 修改之前重命名的 solr\WEB-INF 下的 web.xml 文件:
(1)添加env-entry
(2)将 security-constraint 标签内的内容注释掉
<env-entry>
<env-entry-name>solr/homeenv-entry-name>
<env-entry-value>D:/solr_homeenv-entry-value>
<env-entry-type>java.lang.Stringenv-entry-type>
env-entry>
- 启动tomcat,通过:localhost:8080/solr 即可访问Solr