Sampled Softmax 论文笔记:On Using Very Large Target Vocabulary for Neural Machine Translation
前言
记录下Sampled Softmax的一些原理,相当于论文
《 On Using Very Large Target Vocabulary for Neural Machine Translation 》的个人读书笔记,语句很不通顺,仅用作个人记录,若是有人有问题 再讨论吧
1 问题
NMT(神经网络系统现在已经得到了极大的发展,但是NMT系统一直存在一个问题,就是如何去应对词表过大的问题。词表过大导致了训练复杂度的提升,以及解码的效率。
为了解决这个问题,这篇文章提出了一种方法去允许NMT系统能够使用超大的词表。
2 介绍
首先介绍了NMT的历史和优点。
在NMT或者相关的系统当中,一般情况下,他的词典构造方法是选择排序最靠前的K个词(Bahdanau K=3000,80000 Sutskever),超过这个数额的词,就通过UNK的形式去表现。同时根据文献,发现如果一个句子当中的UNK数量过多,会造成性能的极具下降.
在本文中,为了解决这个问题,提出了一种近似求解的算法,使得NMT系统可以使用一个较大的词表。并且在WMT14评测上进行了对比试验。
3 .1 NMT模型 经典模型
接下来,就首先简单的介绍下NMT系统的一些基本构架,然后再指出其存在的问题。现在比较流行的NMT系统都是基于Encoder-Decoder架构的,简单来说,就是输入一个源语言的句子,然后Encoder将其编码到一个中间的隐状态h,然后Decoder根据再生成最终的翻译。整个Encoder-Decoder模型在训练时,是根据其机器生成的句子和对照句子最大化其条件对数概率。
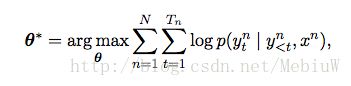
具体来说,在这个框架中,Encoder部分可以采用一个双向的RNN网络来实现,分别从正向和反向将句子输入到RNN网络,每输入一个词,就可以得到两个隐状态h,将他们拼合到一起表示。每一个时间点都会输出一个ht
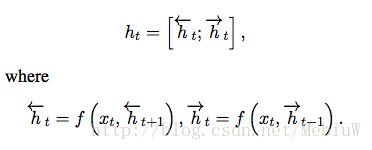
在这里,RNN的Cell类型选择的是GRU(也就是上文中的f函数)
而在Decoder部分呢,也同样是一个RNN网络(在这里Cell也是GRU),并且采用了Attention机制。也就是说,Decoder部分每一步,将会计算一个当前的上下文向量Ct,并根据Ct和Decoder上一步的输出来共同计算下一步的输出。而这个Ct就是整个Attention机制里面的亮点了,他的计算方式是,在Decoder的每一个时间点t时,根据Encoder输出的所有h{h0,h1,h2…hT},Decoder上一步输出的隐状态,去为每个h计算一个权重a,然后将这些权重乘以h,得到当前的上下文Ct。

其中,a的具体实现方式是一个简单的前馈神经网络。
而Decoder在当前时间t,计算这个点所有词输出的概率,则是按照如下的方式进行:

我们可以这么理解上面的6、7:针对每一个词,根据当前的上下文向量Ct,当前Decoder输出的隐状态Zt,上一个输出的词Yt,以及一个非线性的激活函数计算出一个值。当我们计算了词表V中所有词的输出后,使用Softmax将它转变为每个词的概率。
这个Softmax的关键之处就在于,Z的计算,也就是说为了计算每个词的概率,我们需要遍历整个词表V。
3.2 问题
上文上说到了,Decoder每一步需要使用Softmax计算每个词输出的概率是多少,Softmax需要有Z这个值,而Z则需要遍历整个词表。到了这里,相信你也看出来了,问题就是遍历词表V来计算Z这个操作开销太大(计算复杂度和空间复杂度都很高)。
回顾整个模型的训练过程,在训练时,我们明确知道当前时间t应该输出的词是哪一个(6式),我们的目标是需要将它最大化就可以了。但是为了计算这个词的概率,我们必须遍历整个词表,计算得到Z(7式),最终通过softmax来获得他的概率。这样随着词表增大,这个7的计算开销会非常的大,也就是当前的问题所在。
我们有没有办法来解决这个问题呢?
在14年的工作中,一般情况下词表的大小都是在30000到80000之间的,这个词表的大小可以让整个模型训练的开销能够让人接受,但这存在很多问题。首先,如果在训练中的预料中,出现了太多的未登录词UNK,那么模型的性能下降的会很严重,并且在基于BLEU的评测中,也会受到影响。其次,如果是翻译任务是基于某种特别复杂的语言的话,词语特别多的情况下,那么上面的那个问题就会更明显。
为了解决这个问题,有两种思路:基于模型的和基于翻译任务的。
基于模型的方法,其主要的思路是去解决词表过大这个问题。比如说,近似的去猜测应该生成的词的概率,或者说是将将词表里面的词进行聚类。这些方法,都是降低了训练时的复杂度,但是不能降低实际应用解码的速度(因为解码的时候,你一般还是要完整的计算这个概率啊)。
基于翻译任务的方法,主要是根据翻译任务的特殊性,去解决他的稀疏词的问题来降低词表大小。比如说,将稀疏词用对其模型去表示等,这里不做详述。
其实,这两种思路通常也是交融互补的。
4 本文提出的方法
在这篇文章中,作者所提出的是一个基于模型的改进方法,使得我们在NMT应用时可以使用较大的词表。同时,本文提出的方法能够将训练时的计算复杂度降到一个常数上(而不是随着词表增大而增大),同时降低空间开销(这样在GPU上等地方跑就容易多了)。
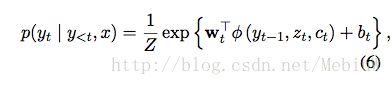
我们前面已经说到了,训练时的开销,主要是集中在式子6之上,式6需要遍历整个词表V,才能获得其用来normalization的项Z。那么本文的解决思想,也就就是让Z的计算不需要遍历整个词表Z,而是遍历一个更小的子集V’。
对于式6取对数后,其梯度计算的结果如下:
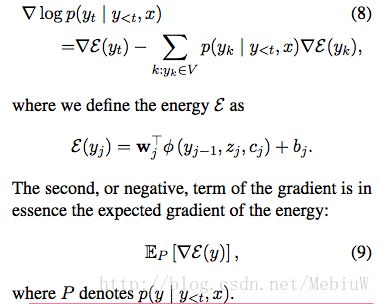
对于式8当中的第二项,其本质上,可以看做是如9那样的能量函数的一个期望(词表中所有词的概率*其梯度)。
第二项的计算需要遍历整个词表,那么本文提出的方法,就是如何去近似的求解式子9,替换式子8当中的第二项。 具体的解决方法,就是根据预先给定的分布Q,和一个抽样的子集V’,使用这个V’去近似的表示式9:
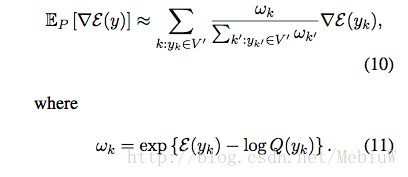
于是,在计算时,我们仅仅使用这个V’大小的词去近似的得到Z,然后更新Wt(当前应该预测出来的词)的参数。
在实际的使用中,这个V’当然不会是随便取得,不然这样会让一个句子中所有词对应的参数无法完全更新。为了解决这个问题,本文的做法是根据训练数据划分出很多的V’。简单来说,就是在训练之前,设定一个Sample-Nums来表示V’的大小,然后我们从语料的头开始,每一句所出现的词加入到当前的集合V’当中,直到V’达到了Sample-Nums的大小,那我们从下一句开始,就按照这个方式重新建立一个V’,知道所有预料都遍历完成了。这样就保证了一个句子对应的那个V’,V’中的词能够完整覆盖句子的所有词。
其中Q指定的概率分布如下,如果当前的词yt,在v’,在V’中的所有词的概率一样,不然全部是0:

这种Q就能够抵消了(10-11)中的-log的项目,这样我们就能近似的表示出(6)了:
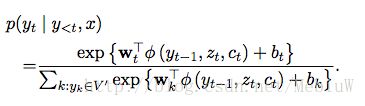
4.1 解码
在完成了训练之后,在实际解码中,是可以按照传统方法完全利用整个词表的,不过这样同样也是开销很大的。其实在解码过程中,也可以利用整个Sample的机制,只不过是选择V’就成了一个技术活了,因为他不像训练的时候,该有的数据都是有的。
具体来说,可以简单的选择频率前K个词,或者使用一些对齐模型 根据源语句 找出最可能的前K个词等,这里作者没有多说。
实验
这里我对NMT不感兴趣,所以就不说了,毕竟我的主要点在于Sampled-Softmax