hadoop集群搭建--完全分布式
目录
一、hadoop完全分布式
操作系统
软件要求
三、配置详情
1.安装虚拟机和配置网络
2. 上传jdk和hadoop
安装 VMware tools
设置共享文件夹
3. 安装jdk和hadoop
解压jdk和hadoop
创建软链接
4. 配置环境变量
配置hadoop配置文件
1.hadoop-env.sh
2.croe-site.xml
3.hdfs-site.xml
4.mapred-site.xml
5.yarn-site.xml
6.slaves
关闭防火墙
配置ssh无密登录
5.开始克隆虚拟机
6.初始化以及启动守护线程
7.结果验证
一、hadoop完全分布式
真正的分布式,由3个及以上的实体机或者虚拟机组成的机群。一个Hadoop集群环境中,NameNode,SecondaryName和DataNode是需要分配在不同的节点上,也就需要三台服务器。
前两种模式一般用在开发或测试环境下,生产环境下都是搭建完全分布式模式。
从分布式存储的角度来说,集群中的节点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。
从分布式应用的角度来说,集群中的节点由一个JobTracker和若干个TaskTracker组成。JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。
操作系统
- w10+vmware
软件要求
- jdk-8u172-linux-x64.tar 连接 https://pan.baidu.com/s/1yfkTu0p2y7sNee4qfq8e6A 密码:b9cr
- hadoop-2.7.3.tar 链接:https://pan.baidu.com/s/1FAmed6G_JfrOfWjckaHbXg 提取码:h9zh
- linux6.8
三、配置详情
1.安装虚拟机和配置网络
实际上单节点是不需要配置网络的。因为要从w10上将jdk和hadoop安装包上传至虚拟机。并且我这台机器需要继续配置伪分布以及完全分布。所以我需要配置网络环境。配置网络其实很简单。不需要的朋友也可以试着配置一下。linux还是很有意思的
我的虚拟机是由一个空白的安装了linux6.8桌面版复制而来。因此 我需要修改虚拟机的mac地址。如果你的虚拟机是创建而来,那么可以跳过修改mac地址的步骤。网络使用nat模式。
- sudo vim /etc/udev/rules.d/70-persistent-net.rules ----查看网卡信息以及记忆mac地址
# This file was automatically generated by the /lib/udev/write_net_rules
# program, run by the persistent-net-generator.rules rules file.
#
# You can modify it, as long as you keep each rule on a single
# line, and change only the value of the NAME= key.
# PCI device 0x8086:0x100f (e1000)
#SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:90:ab:e6", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
----------将此处配置注释或删除
# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:b2:e7:66", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
----------记住网卡mac地址 即00:0c:29:b2:e7:66 并将网卡名改为 eth0 2.sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0 -----修改网卡配置文件
DEVICE=eth0
HWADDR=00:0C:29:B2:E7:66 ------将mac地址修改为刚才的mac地址
TYPE=Ethernet
UUID=c74cd800-bd98-4b84-9b67-821f3f8c14a1
ONBOOT=yes -------将no改为yes 设置开机自动读取网络配置
NM_CONTROLLED=yes
BOOTPROTO=static -------将dhcp改为static 设置为nat模式
IPADDR=192.168.61.70 -------添加ipaddr ip为vm8网卡同网段 查看方式vmware 编辑-虚拟网络编辑
器-vm8网卡-nat设置。 或者直接在window下ipconfig 查看vm8的ip
NETMASK=255.255.255.0 ------- 添加netmask 子网掩码 默认为255.255.255.0
GATEWAY=192.168.61.2 -------添加gateway 默认网关 值为ip最后一位改为2
DNS1=192.168.61.2 -------添加 dns1 默认值何网关相同
3.修改主机名 和域名映射(因为我之后要搭建一个三个节点的完全分布集群 所以我的映射里面添加了三个从节点的ip)
sudo vim /etc/sysconfig/network -------修改主机名
NETWORKING=yes
HOSTNAME=Ms2 --------------将此处改为主机名
sudo vim /etc/hosts ---------修改主机映射
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.61.70 Ms2 --------------ip 主机名 可以忽略下面三条
192.168.61.71 sv1
192.168.61.72 sv2
192.168.61.73 sv3
注 以上配置生效最好重启
2. 上传jdk和hadoop
安装 VMware tools
虚拟机->安装 VMware tools工具->解压缩压缩包到桌面->开启终端->切换root用户->执行可执行文件
->一路回车
设置共享文件夹
点击虚拟主机->设置->选项->共享文件夹-->启动-->选择window系统上要共享的文件夹 (设置共享文件夹时需要重启)
3. 安装jdk和hadoop
首先验证网络配置 即
[ms@Ms2 桌面]$ ping baidu.com
PING baidu.com (123.125.114.144) 56(84) bytes of data.
64 bytes from 123.125.114.144: icmp_seq=1 ttl=128 time=26.2 ms
64 bytes from 123.125.114.144: icmp_seq=2 ttl=128 time=25.7 ms
64 bytes from 123.125.114.144: icmp_seq=3 ttl=128 time=26.7 ms
64 bytes from 123.125.114.144: icmp_seq=4 ttl=128 time=25.8 ms
如果有数据传输 即成功
解压jdk和hadoop
- mkdir ~/apps -------在用户主目录下创建apps目录
- cp /mnt/hgfs/1707/jdk-8u172-linux-x64.tar.gz ~/apps/ --------将共享文件夹中的jdk复制到 apps
- cp /mnt/hgfs/1707/hadoop-2.7.3.tar.gz ~/apps/ --------将共享文件夹中的hadoop复制到 apps
- tar -zvxf ~/apps/jdk-8u172-linux-x64.tar.gz ---------解压jdk
- tar -zvxf ~/apps/hadoop-2.7.3.tar.gz ---------解压hadoop
创建软链接
创建软链接 是为了更换软件时不需要修改环境变量
- [ms@Ms2 apps]$ ln -s ~/apps/hadoop-2.7.3 hadoop -------创建hadoop的链接
- [ms@Ms2 apps]$ ln -s ~/apps/jdk1.8.0_172 jdk -------创建jdk的软链接
4. 配置环境变量
- [ms@Ms2 apps]$ vim ~/.bash_profile -------打开环境配置文件
specific environment and startup programs
PATH=$PATH:$HOME/bin
JAVA_HOME=/home/ms/apps/jdk -------jdk主目录
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin -------配置执行文件指向jdk
HADOOP_HOME=/home/ms/apps/hadoop -------hadoop主目录
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -------------配置执行文件指向hadoop
export PATH JAVA_HOME HADOOP_HOME -------设置自动加载
source ~/.bash_profile --------------读取配置文件
java ----------------测试jdk
用法: java [-options] class [args...]
(执行类)
或 java [-options] -jar jarfile [args...]
(执行 jar 文件)
其中选项包括:
-d32 使用 32 位数据模型 (如果可用)
-d64 使用 64 位数据模型 (如果可用)
-server 选择 "server" VM
默认 VM 是 server.-cp <目录和 zip/jar 文件的类搜索路径>
-classpath <目录和 zip/jar 文件的类搜索路径>
用 : 分隔的目录, JAR 档案
和 ZIP 档案列表, 用于搜索类文件。
-D<名称>=<值>
设置系统属性
-verbose:[class|gc|jni]
启用详细输出
-version 输出产品版本并退出
-version:<值>
需要指定的版本才能运行
-showversion 输出产品版本并继续
-jre-restrict-search | -no-jre-restrict-search
在版本搜索中包括/排除用户专用 JRE
-? -help 输出此帮助消息
-X 输出非标准选项的帮助
-ea[:...|: ]
-enableassertions[:...|: ]
按指定的粒度启用断言
-da[:...|: ]
-disableassertions[:...|: ]
禁用具有指定粒度的断言
-esa | -enablesystemassertions
启用系统断言
-dsa | -disablesystemassertions
禁用系统断言
-agentlib:[=<选项>]
加载本机代理库, 例如 -agentlib:hprof
另请参阅 -agentlib:jdwp=help 和 -agentlib:hprof=help
-agentpath:[=<选项>]
按完整路径名加载本机代理库
-javaagent:[=<选项>]
加载 Java 编程语言代理, 请参阅 java.lang.instrument
-splash:
使用指定的图像显示启动屏幕
有关详细信息, 请参阅 http://www.oracle.com/technetwork/java/javase/documentation/index.html。
hadoop ------------------测试hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jarrun a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcpcopy file or directories recursively
archive -archiveName NAME -p* create a hadoop archive
classpath prints the class path needed to get the
credential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settingsMost commands print help when invoked w/o parameters
配置hadoop配置文件
1.hadoop-env.sh
- [ms@Ms2 ~]$ vim ~/apps/hadoop/etc/hadoop/hadoop-env.sh
- export JAVA_HOME=/home/ms/apps/jdk ----------将此处修改为jdk路径
2.croe-site.xml
- vim ~/apps/hadoop/etc/hadoop/core-site.xml
-----------------添加以下属性
fs.defaultFS -----------------指定文件系统名称 和post ,host
hdfs://Ms2:9000
hadoop.tmp.dir ------------------用于指定datenode文件存储路径 此目录需要手动创建
file:/home/ms/apps/hadoop/tmp
3.hdfs-site.xml
- vim ~/apps/hadoop/etc/hadoop/hdfs-site.xml
dfs.replication -------------------指定文件副本数
3
4.mapred-site.xml
此目录下没有该文件,我们需要将mapred-site.xml.template 复制一份,改成此名,然后再修改。
- cp ~/apps/hadoop/etc/hadoop/mapred-site.xml.template ~/apps/hadoop/etc/hadoop/mapred-site.xml
mapreduce.framework.name -----------使用yarn运行框架
yarn
5.yarn-site.xml
- vim ~/apps/hadoop/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services -------选择混洗技术
mapreduce_shuffle
yarn.resourcemanager.hostname
Ms2 --------选择主机
6.slaves
- vim ~/apps/hadoop/etc/hadoop/slaves
- sv1 --------------选择数据节点。我要搭设三个从节点 所以域名映射添加三台主机
sv2
sv3
关闭防火墙
- [ms@Ms2桌面]$sudo chkconfig iptables off ------------永久关闭防火墙
- [ms@Ms2 桌面]$ chkconfig iptables --list ------------查看防火墙状态
- iptables 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭 ------防火墙已关闭
配置ssh无密登录
- ssh-keygen -t rsa ------------------一直回车
- cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys --------------------将公钥发出
- chmod 600 ~/.ssh/authorized_keys ---------------修改权限为600
- ssh localhost ----测试ssh无密登录结果
- Last login: Fri Mar 29 02:34:28 2019 from localhost
5.开始克隆虚拟机
因为我是准备搭建三个数据节点的集群 主节点不设置为数据节点 所以需要完全克隆三台虚拟机 主机映射为
192.168.61.71 sv1
192.168.61.72 sv2
192.168.61.73 sv3我们需要修改三台虚拟机 此处只拿一天作为示范 其他全部相同。读者自行配置。
- [ms@Ms2 桌面]$ sudo /etc/udev/rules.d/70-persistent-net.rules 修改网卡设置
# PCI device 0x8086:0x100f (e1000)
#SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:b2:e7:66", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0" ------------------将此行注释或删除# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:01:df:ba", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0" ----------------将网卡mac地址记忆 将eth1改为eth0[ms@Ms2 桌面]$ sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:0C:29:01:DF:BA ----------------修改mac地址
TYPE=Ethernet
UUID=c74cd800-bd98-4b84-9b67-821f3f8c14a1
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.61.71 --------------修改ip
NETMASK=255.255.255.0
GATEWAY=192.168.61.2
DNS1=192.168.61.2[ms@Ms2 桌面]$ sudo vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=sv1 ------------------修改主机名
其他两台机器相同操作
6.初始化以及启动守护线程
初始化之前确保tmp目录下没有dfs 并且不是第一次ssh同从节点 因为第一次ssh需要yes验证可能会连接不上
- [ms@Ms2 桌面]$ ssh sv1 -------使用ssh向从节点发送请求 第一次需要yes验证 当主机名显示从节点即成功可以使用exit退出
- [ms@sv1 ~]$ rm -rf ~/apps/hadoop/tmp/* ~/apps/hadoop/logs ---删除datenode节点数据 否则初始化启动不了datenode守护进程
- 使用exit退出到主节点
初始化namenode进程(建议重启后)
- [ms@Ms2 桌面]$ hdfs namenode -format
启动守护线程
- [ms@Ms2 桌面]$ start-dfs.sh
Starting namenodes on [Ms1]
Ms1: starting namenode, logging to /home/ms/apps/hadoop-2.7.3/logs/hadoop-ms-namenode-Ms1.out
sv1: starting datanode, logging to /home/ms/apps/hadoop-2.7.3/logs/hadoop-ms-datanode-sv1.out
sv2: starting datanode, logging to /home/ms/apps/hadoop-2.7.3/logs/hadoop-ms-datanode-sv2.out
sv3: starting datanode, logging to /home/ms/apps/hadoop-2.7.3/logs/hadoop-ms-datanode-sv3.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/ms/apps/hadoop-2.7.3/logs/hadoop-ms-secondarynamenode-Ms1.out
查看主/从节点守护线程
- [ms@Ms2 桌面]$ jps
3701 Jps
3368 NameNode
3544 SecondaryNameNode- [ms@sv1 桌面]$ jps
3380 Jps
2829 DataNode
7.结果验证
可以使用虚拟机自带火狐浏览器输入Ms2:50070进入hadoopweb界面。或者使用ip从window也可以即192.168.61.70
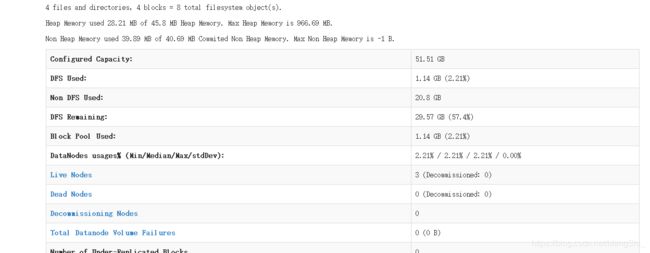
可以看到 三个数据节点都已启动成功。下面就可以操作hdfs分布式文件系统。具体操作和启动流程原理我们下篇会说到