Spark RDD Lazy Evaluation的特性及作用
看一些博客都是轻描淡写的说一下这是spark的特性,延迟/惰性计算(lazy evaluation)就完事了,然后各个博客之间抄来抄去就是那么几句话,所以就想着把这些东西整理一下讲清楚,希望对有需要的朋友有所帮助。
主要为了解决3个疑问
- rdd的弹性表现在哪 ?
- 什么是spark lazy 特性 ?
- spark lazy evaluation 的好处都有什么 ?
rdd的弹性表现在哪
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。那么为什么叫弹性分布式?分布式好理解,这里不谈;那什么叫弹性?
RDD的弹性和RDD的容错机制(通过DAG重算节点失败导致的丢失数据)有着比较强的关联,可以说是RDD的几个特性中的重要一个;以下摘抄
RDD的弹性表现:
1、弹性之一:自动的进行内存和磁盘数据存储的切换;
2、弹性之二:基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错);
3、弹性之三:Task如果失败会自动进行特定次数的重试(默认4次);
4、弹性之四:Stage如果失败会自动进行特定次数的重试(可以只运行计算失败的阶段);只计算失败的数据分片;
5、checkpoint和persist
6、数据调度弹性:DAG TASK 和资源 管理无关
7、数据分片的高度弹性(人工自由设置分片函数),repartition
既然聊到弹性了,那就讲解一下最重要的容错特性
考虑到核心的容错机制,必然得县提到rdd之间的依赖关系!
什么是窄依赖和宽依赖?
RDD 的 Transformation 函数中又分为窄依赖(narrow dependency)和宽依赖(wide dependency)的操作:
- 窄依赖(narrow dependencies): 子RDD的每个分区依赖于常数个父分区(即与数据规模无关)
- 窄依赖的函数有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
- 宽依赖(wide dependencies):父RDD被多个子RDD所用。例如,map产生窄依赖,而join则是宽依赖(除非父RDD被哈希分区)
- 宽依赖的函数有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
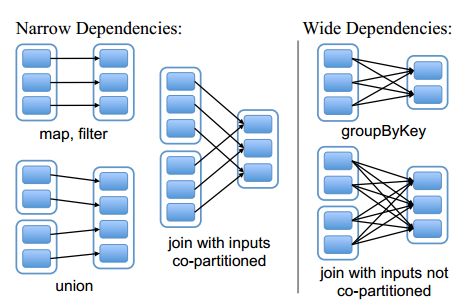
(方框表示RDD,实心矩形表示分区)
简单来说:如果父分区能够被一个以上子分区使用的,也就是说用到shuffle过程的,那就是宽依赖;如果没有shuffle过程,那就是窄分区
- 从容错角度考虑:如果说我是宽依赖的,然后一个子分区挂掉了,那怎么办,我的内容来自于好几个父分区啊,极端情况下,所有的父RDD分区都要进行重新计算。如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
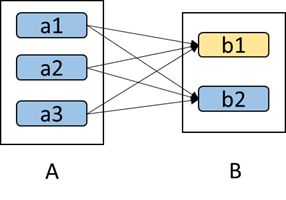
- 另一方面,如果说我是窄依赖,那么我一个子RDD中的其中一个分区挂掉了,那么我只需要计算该分区所对应的父分区即可,应该认识一点,对于容错来说,重新计算是必不可少的!只是怎么计算会使冗余计算最小才是我们优化要考虑的,比较上文的宽依赖,我一个子分区挂掉了,其全部父分区都得重算,那就很浪费了,因为可以看出,所有父分区供应着所有子分区,就因为你一个子分区挂掉,我特喵的父分区全部得重算,着买卖好亏啊!
总结:窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;
一个日志挖掘交互的例子
日志错误处理,我很少涉及到,基本上都是直接从日志解析数据重构等,所以这里例子摘自,交互式的控制台处理排查错误日志
本部分我们通过一个具体示例来阐述RDD。假定有一个大型网站出错,操作员想要检查Hadoop文件系统(HDFS)中的日志文件(TB级大小)来找出原因。通过使用Spark,操作员只需将日志中的错误信息装载到一组节点的内存中,然后执行交互式查询。首先,需要在Spark解释器中输入如下Scala命令:
lines = spark.textFile("hdfs://...") //第1行从HDFS文件定义了一个RDD(即一个文本行集合)
errors = lines.filter(_.startsWith("ERROR")) //第2行获得一个过滤后的RDD
errors.cache() //第3行请求将errors缓存起来
# 注意在Scala语法中filter的参数是一个闭包
这时集群还没有开始执行任何任务。但是,用户已经可以在这个RDD上执行对应的动作,例如统计错误消息的数目:
errors.count()
用户还可以在RDD上执行更多的转换操作,并使用转换结果,如:
// Count errors mentioning MySQL:
errors.filter(_.contains("MySQL")).count()
// Return the time fields of errors mentioning
// HDFS as an array (assuming time is field
// number 3 in a tab-separated format):
errors.filter(_.contains("HDFS")).map(_.split('\t')(3)).collect()
使用errors的第一个action运行以后,Spark会把errors的分区缓存在内存中,极大地加快了后续计算速度。注意,最初的RDD lines不会被缓存。因为错误信息可能只占原数据集的很小一部分(小到足以放入内存)。
最后,为了说明模型的容错性,图1给出了第3个查询的Lineage图。在lines RDD上执行filter操作,得到errors,然后再filter、map后得到新的RDD,在这个RDD上执行collect操作。Spark调度器以流水线的方式执行后两个转换,向拥有errors分区缓存的节点发送一组任务。此外,如果某个errors分区丢失,Spark只在相应的lines分区上执行filter操作来重建该errors分区。
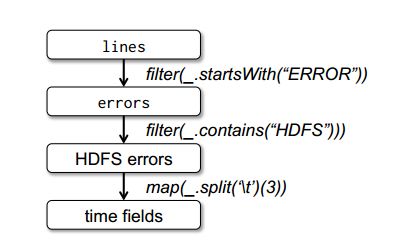
图1 示例中第三个查询的Lineage图。(方框表示RDD,箭头表示转换)
什么是spark lazy 特性
简单字面理解下含义就是:spark直到action 动作之前,数据不会先被计算;(什么是action?这里不做过多介绍,一句话概括就是,spark的算子中存在action和transform两种,transform就是常见的map,union,flatmap,groupByKey, join等不需要系统返回啥的算子。而collect,count,reduce等需要拉回产生结果的算子就是action算子,可以简单的说,action算的的个数是job提交的个数; 详见:Spark的Transform算子和Action算子列举和示例
spark的transform处理的数据,都不会立刻执行,它会根据rdd之间的链式进行传递,比如这个最简单的wordcount例子
>>> rdd_ = sc.parallelize([1,2,3,4,33,2,44,1,44,3,2,2,2,1,33,6],4)
>>> rdd_.getNumPartitions()
4
>>> rdd_transform = rdd_.filter(lambda x:x > 2).map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)
>>> rdd_transform
PythonRDD[104] at RDD at PythonRDD.scala:48
这时候spark UI上不会有任何job被提交,因为这个计算没有任何action算子,实际上根本没有被计算,这就是lazy特性。
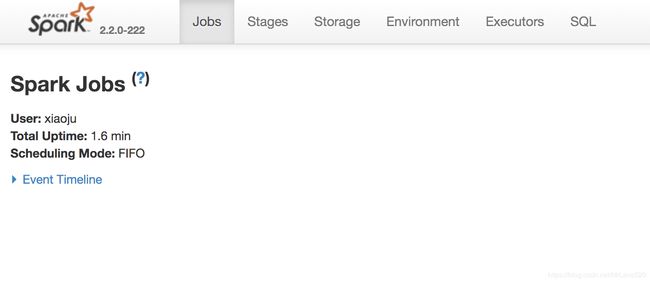
而当collect()开始执行的时候,driver端需要拉回所有数据吐出,所以需要开始提交job开始计算值;
>>> rdd_transform.collect()
[(4, 1), (44, 2), (33, 2), (6, 1), (3, 2)]
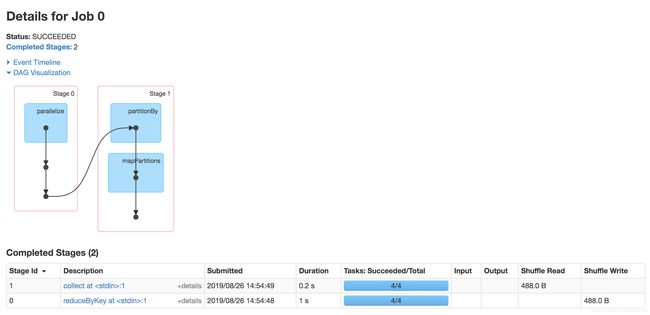
- 可以看到提交了一个job,job内存在两个stage,stage的划分主要靠shuffle过程作为边界,从尾开始往前倒,看到有shuffle算子,就会划分开一个stage,这里是collect这个算子进行划分;具体的可以参考这个用实例说明Spark stage划分原理
- 里面有4个task,这是因为我在生成rdd的时候,人为的给他重分区了,相当于coalesce(不产生shuffle),对应生成了4个partition,所以开始执行任务的时候会分配四个task,这个和MR中的inputSplit有着异曲同工之妙,一个split文件对应一个map,(感兴趣可以看下这个总结:详细讲解MapReduce过程(整理补充));
上述的整个流程可以看这个我盗的图

那这样Lazy的好处有什么呢?
- 可以将代码的程序变成一块块的操作链,这样就能够很好的兼顾代码的可读性和减少耦合
- 能够极大的减少中间计算过程提高计算效率;除非是真正需要用到的数据,才会计算;在普通的程序中,如果对每一步都进行计算,那效率将会是很低的,特别是如果最终的结果并不强依赖之前的中间结果,那么计算资源将会被浪费
- 降低时间复杂度和空间复杂度;因为spark程序并不执行所有中间操作,降低空间(中间结果落盘)和时间的开销(和第二点所表达的一样)
举个
in high school, and your mom came in to ask you to do a chore (“fetch me some milk for tonight’s dinner”). Your response: say that you were going to do it, then keep right on doing what you were already doing. Sometimes your mom would come back in and say she didn’t need the chore done after all (“I substituted water instead”). Magic, work saved! Sometimes the laziest finish first.
Spark is the same. It waits until you’re done giving it operators, and only when you ask it to give you the final answer does it evaluate, and it always looks to limit how much work it has to do. Suppose you first ask Spark to filter a petabyte of data for something—say, find you all the point of sale records for the Chicago store—then next you ask for it to give you just the first result that comes back. This is a really common thing to do. Sometimes a data analyst just wants to see a typical record for the Chicago store. If Spark were to run things explicitly as you gave it instructions, it would load the entire file, then filter for all the Chicago records, then once it had all those, pick out just the first line for you. That’s a huge waste of time and resources. Spark will instead wait to see the full list of instructions, and understand the entire chain as a whole. If you only wanted the first line that matches the filter, then Spark will just find the first Chicago POS record, then it will emit that as the answer, and stop. It’s much easier than first filtering everything, then picking out only the first line.
Now, you could write your MapReduce jobs more intelligently to similarly avoid over-using resource, but it’s much more difficult to do that. Spark makes this happen automatically for you. Normally, software like Hive goes into contortions to avoid running too many MapReduce jobs, and programmers write very complex and hard-to-read code to force as much as possible into each Map and Reduce job. This makes development hard, and makes the code hard to maintain over time. By using Spark instead, you can write code that describes how you want to process data, not how you want the execution to run, and then Spark “does the right thing” on your behalf to run it as efficiently as possible. This is the same thing a good high-level programming language does: it raises the abstraction layer, letting the developer talk more powerfully and expressively, and does the work behind the scenes to ensure it runs as fast as possible.
其中一个case翻译一下就是,假设有一个需求是需要先加载一下一天的订单信息,如果不是lazy的特性,spark会先根据你的需求把这一天的订单信息加载到内存中(太大就溢写),然后你需求又变更了,只想看一下这一天的订单的基本样式,取个一条就可以了,然后spark对内存中的数据取一条吐出来;其实这样是很低效的,最终诉求其实可以理解为,取出订单的第一条数据看看;我们把第一个需求(取出所有订单),第二个需求(订单中的一条)当做两个transform算子,那么他们会最终成为一个链chain;如果操作再多一些,就会形成DAG,这样spark会理解整个链路以及最后的需求后,优化整个DAG,以消耗最少资源的情况下满足需求,这就是lazy特性带来的好处,并不是立刻执行,而是see the big picture,概览全局后,在最后一顿骚操作优化,然后再执行计算;虽然mapreduce也可以实现,但是对开发人员成本比较高,需要写代码去规避这些资源浪费;而spark自己自动进行优化
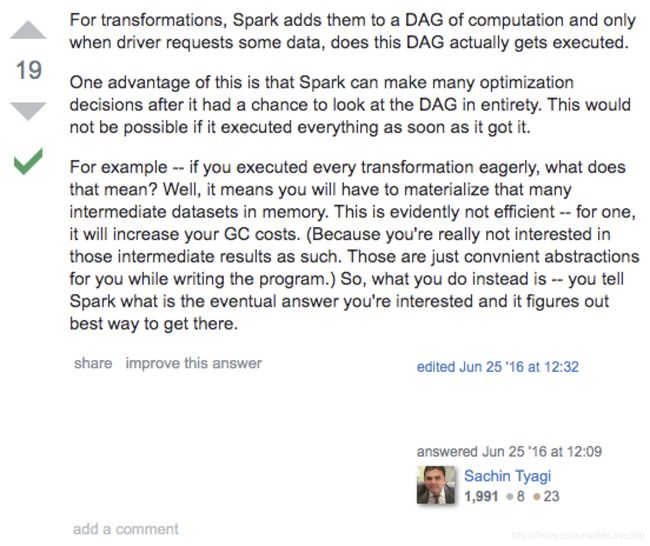
再给个stackoverflow上的高赞回答
致谢
1.Lazy Evaluation in Apache Spark – A Quick guide
2.Spark RDD的依赖解读
3.每次进步一点点——Spark 中的宽依赖和窄依赖
4.Spark分布式计算和RDD模型研究
5.SPARK 阔依赖 和窄依赖 transfer action lazy策略之间的关系
6.RDD:基于内存的集群计算容错抽象
7. What are the key differences between Spark and MapReduce?
8. Spark Transformation - Why its lazy and what is the advantage?