基于深度学习的人脸识别系统(Caffe+OpenCV+Dlib)【三】VGG网络进行特征提取
前言
基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库)、Caffe(深度学习库)、Dlib(机器学习库)、libfacedetection(人脸检测库)、cudnn(gpu加速库)。
用到了一个开源的深度学习模型:VGG model。
最终的效果是很赞的,识别一张人脸的速度是0.039秒,而且最重要的是:精度高啊!!!
CPU:intel i5-4590
GPU:GTX 980
系统:Win 10
OpenCV版本:3.1(这个无所谓)
Caffe版本:Microsoft caffe (微软编译的Caffe,安装方便,在这里安利一波)
Dlib版本:19.0(也无所谓
CUDA版本:7.5
cudnn版本:4
libfacedetection:6月份之后的(这个有所谓,6月后出了64位版本的)
这个系列纯C++构成,有问题的各位朋同学可以直接在博客下留言,我们互相交流学习。
====================================================================
本篇是该系列的第三篇博客,介绍如何使用VGG网络模型与Caffe的 MemoryData层去提取一个OpenCV矩阵类型Mat的特征。
思路
VGG网络模型是牛津大学视觉几何组提出的一种深度模型,在LFW数据库上取得了97%的准确率。VGG网络由5个卷积层,两层fc图像特征,一层fc分类特征组成,具体我们可以去读它的prototxt文件。这里是模型与配置文件的下载地址。
http://www.robots.ox.ac.uk/~vgg/software/vgg_face/
话题回到Caffe。在Caffe中提取图片的特征是很容易的,其提供了extract_feature.exe让我们来实现,提取格式为lmdb与leveldb。关于这个的做法,可以看我的这篇博客:
http://blog.csdn.net/mr_curry/article/details/52097529
显然,我们在程序中肯定是希望能够灵活利用的,使用这种方法不太可行。Caffe的Data层提供了type:MemoryData,我们可以使用它来进行Mat类型特征的提取。
注:你需要先按照本系列第一篇博客的方法去配置好Caffe的属性表。
http://blog.csdn.net/mr_curry/article/details/52443126
实现
首先我们打开VGG_FACE_deploy.prototxt,观察VGG的网络结构。
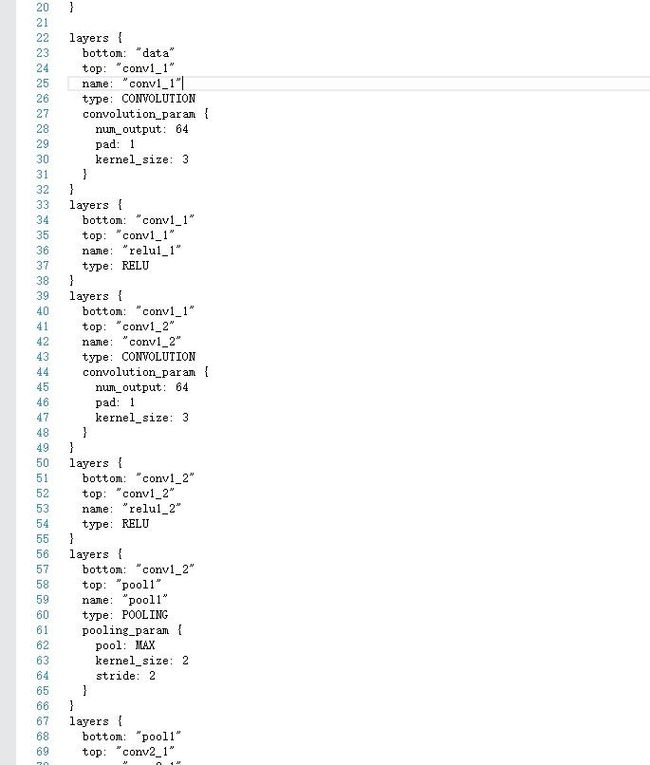
有意思的是,MemoryData层需要图像均值,但是官方网站上并没有给出mean文件。我们可以通过这种方式进行输入:
mean_value:129.1863
mean_value:104.7624
mean_value:93.5940我们还需要修改它的data层:(你可以用下面这部分的代码去替换下载下来的prototxt文件的data层)
layer {
name: "data"
type: "MemoryData"
top: "data"
top: "label"
transform_param {
mirror: false
crop_size: 224
mean_value:129.1863
mean_value:104.7624
mean_value:93.5940
}
memory_data_param {
batch_size: 1
channels:3
height:224
width:224
}
}
为了不破坏原来的文件,把它另存为vgg_extract_feature_memorydata.prototxt。
![]()
好的,然后我们开始编写。添加好这个属性表:
然后,新建caffe_net_memorylayer.h、ExtractFeature_.h、ExtractFeature_.cpp开始编写。
caffe_net_memorylayer.h:
#include "caffe/layers/input_layer.hpp"
#include "caffe/layers/inner_product_layer.hpp"
#include "caffe/layers/dropout_layer.hpp"
#include "caffe/layers/conv_layer.hpp"
#include "caffe/layers/relu_layer.hpp"
#include
#include "caffe/caffe.hpp"
#include ExtractFeature_.h
#include 容器
void Caffe_Predefine();ExtractFeature_.cpp:
#include * Net_Init_Load(std::string param_file, std::string pretrained_param_file, caffe::Phase phase)
{
caffe::Net* net(new caffe::Net("vgg_extract_feature_memorydata.prototxt", caffe::TEST));
net->CopyTrainedLayersFrom("VGG_FACE.caffemodel");
return net;
}
void Caffe_Predefine()//when our code begining run must add it
{
caffe::Caffe::set_mode(caffe::Caffe::GPU);
net = Net_Init_Load<float>("vgg_extract_feature_memorydata.prototxt", "VGG_FACE.caffemodel", caffe::TEST);
memory_layer = (caffe::MemoryDataLayer<float> *)net->layers()[0].get();
}
std::vector<float> ExtractFeature(Mat FaceROI)
{
caffe::Caffe::set_mode(caffe::Caffe::GPU);
std::vectorfloat >*> input_vec;
net->Forward(input_vec);
boost::shared_ptrfloat>> fc8 = net->blob_by_name("fc8");
int test_num = 0;
while (test_num < 2622)
{
test_vector.push_back(fc8->data_at(0, test_num++, 1, 1));
}
return test_vector;
} =============注意上面这个地方可以这么改:==============
(直接可以知道这个向量的首地址、尾地址,我们直接用其来定义vector)
float* begin = nullptr;
float* end = nullptr;
begin = fc8->mutable_cpu_data();
end = begin + fc8->channels();
CHECK(begin != nullptr);
CHECK(end != nullptr);
std::vector<float> FaceVector{ begin,end };
return std::move(FaceVector);请特别注意这个地方:
namespace caffe
{
extern INSTANTIATE_CLASS(InputLayer);
extern INSTANTIATE_CLASS(InnerProductLayer);
extern INSTANTIATE_CLASS(DropoutLayer);
extern INSTANTIATE_CLASS(ConvolutionLayer);
REGISTER_LAYER_CLASS(Convolution);
extern INSTANTIATE_CLASS(ReLULayer);
REGISTER_LAYER_CLASS(ReLU);
extern INSTANTIATE_CLASS(PoolingLayer);
REGISTER_LAYER_CLASS(Pooling);
extern INSTANTIATE_CLASS(LRNLayer);
REGISTER_LAYER_CLASS(LRN);
extern INSTANTIATE_CLASS(SoftmaxLayer);
REGISTER_LAYER_CLASS(Softmax);
extern INSTANTIATE_CLASS(MemoryDataLayer);
}为什么要加这些?因为在提取过程中发现,如果不加,会导致有一些层没有注册的情况。我在Github的Microsoft/Caffe上帮一外国哥们解决了这个问题。我把问题展现一下:
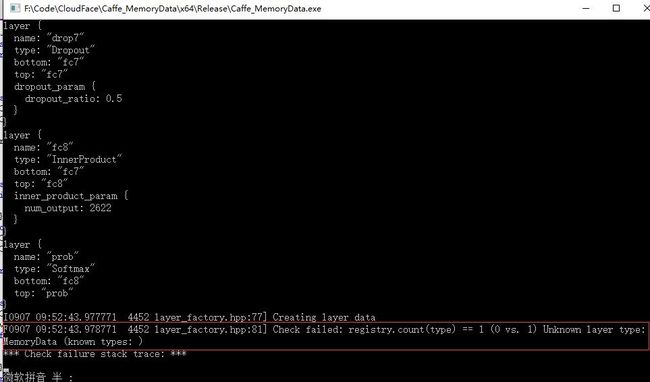
如果我们加了上述代码,就相当于注册了这些层,自然就不会有这样的问题。
在提取过程中,我提取的是fc8层的特征,2622维。当然,最后一层都已经是分类特征了,最好还是提取fc7层的4096维特征。
在这个地方:
void Caffe_Predefine()//when our code begining run must add it
{
caffe::Caffe::set_mode(caffe::Caffe::GPU);
net = Net_Init_Load<float>("vgg_extract_feature_memorydata.prototxt", "VGG_FACE.caffemodel", caffe::TEST);
memory_layer = (caffe::MemoryDataLayer<float> *)net->layers()[0].get();
}是一个初始化的函数,用于将VGG网络模型与提取特征的配置文件进行传入,所以很明显地,在提取特征之前,需要先:
Caffe_Predefine();进行了这个之后,这些全局量我们就能一直用了。
我们可以试试提取特征的这个接口。新建一个main.cpp,调用之:
#include 因为我们得到的是一个vector< float>类型,所以我们可以把它逐一输出出来看看。当然,在ExtractFeature()的函数中你就可以这么做了。我们还是在main()函数里这么做。
来看看:
#include cout << print[i++] << endl;
}
}
imshow("Extract feature",lena);
waitKey(0);
} 那么对于这张图片,提取出的特征,就是很多的这些数字:
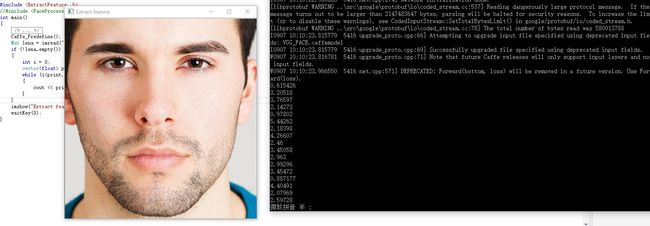
提取一张224*224图片特征的时间为:0.019s。我们可以看到,GPU加速的效果是非常明显的。而且我这块显卡也就是GTX980。不知道泰坦X的提取速度如何(泪)。
附:net结构 (prototxt),注意layer和layers的区别:
name: "VGG_FACE_16_layer"
layer {
name: "data"
type: "MemoryData"
top: "data"
top: "label"
transform_param {
mirror: false
crop_size: 224
mean_value:129.1863
mean_value:104.7624
mean_value:93.5940
}
memory_data_param {
batch_size: 1
channels:3
height:224
width:224
}
}
layer {
bottom: "data"
top: "conv1_1"
name: "conv1_1"
type: "Convolution"
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv1_1"
top: "conv1_1"
name: "relu1_1"
type: "ReLU"
}
layer {
bottom: "conv1_1"
top: "conv1_2"
name: "conv1_2"
type: "Convolution"
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv1_2"
top: "conv1_2"
name: "relu1_2"
type: "ReLU"
}
layer {
bottom: "conv1_2"
top: "pool1"
name: "pool1"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool1"
top: "conv2_1"
name: "conv2_1"
type: "Convolution"
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv2_1"
top: "conv2_1"
name: "relu2_1"
type: "ReLU"
}
layer {
bottom: "conv2_1"
top: "conv2_2"
name: "conv2_2"
type: "Convolution"
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv2_2"
top: "conv2_2"
name: "relu2_2"
type: "ReLU"
}
layer {
bottom: "conv2_2"
top: "pool2"
name: "pool2"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool2"
top: "conv3_1"
name: "conv3_1"
type: "Convolution"
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv3_1"
top: "conv3_1"
name: "relu3_1"
type: "ReLU"
}
layer {
bottom: "conv3_1"
top: "conv3_2"
name: "conv3_2"
type: "Convolution"
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv3_2"
top: "conv3_2"
name: "relu3_2"
type: "ReLU"
}
layer {
bottom: "conv3_2"
top: "conv3_3"
name: "conv3_3"
type: "Convolution"
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv3_3"
top: "conv3_3"
name: "relu3_3"
type: "ReLU"
}
layer {
bottom: "conv3_3"
top: "pool3"
name: "pool3"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool3"
top: "conv4_1"
name: "conv4_1"
type: "Convolution"
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv4_1"
top: "conv4_1"
name: "relu4_1"
type: "ReLU"
}
layer {
bottom: "conv4_1"
top: "conv4_2"
name: "conv4_2"
type: "Convolution"
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv4_2"
top: "conv4_2"
name: "relu4_2"
type: "ReLU"
}
layer {
bottom: "conv4_2"
top: "conv4_3"
name: "conv4_3"
type: "Convolution"
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv4_3"
top: "conv4_3"
name: "relu4_3"
type: "ReLU"
}
layer {
bottom: "conv4_3"
top: "pool4"
name: "pool4"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool4"
top: "conv5_1"
name: "conv5_1"
type: "Convolution"
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv5_1"
top: "conv5_1"
name: "relu5_1"
type: "ReLU"
}
layer {
bottom: "conv5_1"
top: "conv5_2"
name: "conv5_2"
type: "Convolution"
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv5_2"
top: "conv5_2"
name: "relu5_2"
type: "ReLU"
}
layer {
bottom: "conv5_2"
top: "conv5_3"
name: "conv5_3"
type: "Convolution"
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layer {
bottom: "conv5_3"
top: "conv5_3"
name: "relu5_3"
type: "ReLU"
}
layer {
bottom: "conv5_3"
top: "pool5"
name: "pool5"
type: "Pooling"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
bottom: "pool5"
top: "fc6"
name: "fc6"
type: "InnerProduct"
inner_product_param {
num_output: 4096
}
}
layer {
bottom: "fc6"
top: "fc6"
name: "relu6"
type: "ReLU"
}
layer {
bottom: "fc6"
top: "fc6"
name: "drop6"
type: "Dropout"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
bottom: "fc6"
top: "fc7"
name: "fc7"
type: "InnerProduct"
inner_product_param {
num_output: 4096
}
}
layer {
bottom: "fc7"
top: "fc7"
name: "relu7"
type: "ReLU"
}
layer {
bottom: "fc7"
top: "fc7"
name: "drop7"
type: "Dropout"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
bottom: "fc7"
top: "fc8"
name: "fc8"
type: "InnerProduct"
inner_product_param {
num_output: 2622
}
}
layer {
bottom: "fc8"
top: "prob"
name: "prob"
type: "Softmax"
}
=================================================================