基于CNN的智能问答系统构建
摘要
之前小的不才,发表了一篇文章,有些道友希望有源代码,特此附上进阶篇,本次java代码在GitHub:https://github.com/2518881238/QA_NLP,仅供参考,语料啥的需要自己测试整理相应格式的就行,如有不足之处,望各位道友批评指正。
本论文主要是对于CNN实际应用,其中也可以看出CNN对于人工智能来说也不是全能的,这也是目前这个研究领域的瓶颈。
对了,该代码Word2vec部分是借用的,自己有些改动,但主要还是得力于大神,在此表示感谢。参考项目地址:https://github.com/NLPchina/Word2VEC_java。
在互联网席卷全球的时代背景下,智能化的自然语言问答是处理语言信息的重要手段。实现高效,全面,更具有实用性的智能问答也是自然语言智能化的重点研究方向之一。目前普遍的问答社区模块中主要存在回答信息有误,回答信息冗余和回答信息不精确等问题。由于这些问题的困扰,导致了用户体验感变差,问答系统也满足不了日益增长的用户问答需求。针对这一现状,本系统致力于解决一般问答社区信息冗余问题和提高问答效率,能从语义,语境和语言结构方面更加智能化的语句识别,致力于构建一个更加实用的问答系统。
本论文研究智能问答系统是基于问答社区积累的大量问答信息,采用Word2vec构建词向量问答相似矩阵,利用中文分词技术分词,然后利用卷积神经网络(CNN)构造分类器进行分类处理,再构建问答匹配算法,最终实现问答匹配。国内研究智能化问答系统主要有通过问题相似度实现问答匹配,通过构建知识库进行关键字匹配来实现问答匹配和利用关键字进行全文检索实现问答匹配三种方式。本系统构建主要采用问题相似度进行问答匹配,这样可以实现不限领域的开放式问答,同时也可以实现复杂问题的问答,并且利用基于统计的神经网络算法构建词向量,实用CNN神经网络来实现语义的识别和匹配,使系统问答更加注重语义之间的匹配而非表面上的关键字匹配。本系统利用问答信息来构建问答系统,实现了语义上的问答匹配,解决了普通问答社区的信息冗余和问答信息不精确等问题。
关键词:问答社区,智能问答系统,词向量,神经网络,问答匹配。
Intelligent Question Answering System Based on Software Knowledge
ABSTRACT
In the background of the Internet sweeping the world, intelligent natural language question and answer is an important means to deal with language information. It is also one of the key research directions of intelligent natural language to achieve efficient, comprehensive and practical intelligent question and answer. At present, the answer information is incorrect, the answer information is redundant and the answer information is not accurate. Due to these problems, the user experience has deteriorated, and the question and answer system can not meet the growing user question and answer needs. In view of this situation, this system is committed to solving the problem of general question and answer community information redundancy and improving the efficiency of question and answer. It can be more intelligent in terms of semantics, context and language structure, and is committed to building a more practical question and answer system.
In this paper, the intelligent question and answer system is based on a large amount of question and answer information accumulated by the question and answer community. Word2vec is used to build a similar matrix of word vector question and answer, Chinese word segmentation technique is used, and then the convolution neural network(CNN) is used to construct a classifier for classification processing. Then build the question and answer matching algorithm, and finally achieve question and answer matching. The intelligent question and answer system in our country mainly includes question and answer matching through question similarity, question and answer matching by constructing a knowledge base for keyword matching, and question and answer matching by using keywords for full-text retrieval. This system mainly uses question and answer matching with problem similarity, which can achieve open-ended question and answer in the field, but also can achieve complex question and answer, and use statistical neural network algorithm to build word vectors. The application of CNN neural network to achieve semantic recognition and matching makes the system question and answer pay more attention to the matching between semantics rather than the surface keyword matching. This system uses Q&A information to construct Q&A system, realizes the semantic Q&A matching, solves the problems of information redundancy and inaccurate Q&A information in ordinary Q&A communities.
Key words: question and answer community, intelligent question and answer system, word vector, neural network, question and answer matching.
1 绪论
1.1论文研究背景
随着互联网的风暴席卷而来,人们每天的生活都在发生着翻天覆地的变化。面对信息爆炸而无力选择想要的信息的现状,人们往往会迷失在这茫茫信息的海洋之中而难以找到准确的答案。在信息的持续爆炸增长情况下,问题难以匹配到答案。各种传统问答模式面对海量的数据信息也越来越吃力,传统的关键词匹配问答方式存在信息检索不精确,问答信息冗余问答错误等问题。这也说明停留在语句上的问答匹配是不足以解决人们的问答需求。很多问答社区面对问答信息的冗余,虽然信息库变得越来越强大,但是相反问答效率会变得越来越低下。
目前,对于深度学习和语言智能化技术研究也是逐渐成熟,对于语言的智能识别程度也逐渐提高。随着单词向量化模型的诞生,神经网络算法的进一步发展,自然语言识别在深度学习的背景下提高了自我学习的力度。随着CNN,RNN等模型在文本中取得的优异成果,智能问答不仅仅停留在语句结构上的理解,更多的通过自我学习达到语义或者语境上的匹配,从而提高问答质量和精准度,尤其最近Google推出的Bert更是刷新了NLP界的新纪录。
从社会需求条件和问答技术的发展支持下,构建一个能满足当下乃至未来的问答需求,能更加准确,高效提供问答服务的系统是十分有必要的。研究前景好,未来发展潜力巨大。
1.2论文研究目的
在传统问答效果不满足于现有信息检索需求下,在自然语言智能识别技术高速发展的背景下,构建一个更高效,精确的问答系统显得非常有必要。
本论文致力于构建解决问答社区信息冗余问题和提高问答效率的智能问答系统。面对传统问答存在的问题,本论文通过研究语言数据结构化算法实现语句分词构建和词语的多维度描述构建来解决传统语句统计算法带来的问答不精确问题。通过深度学习和CNN等神经网络模型的构建来提高问答识别度,构建语句结构和语义方面相结合的智能问答识别系统。本论文通过构建自动检索和问答智能化匹配来解决问答信息冗余的问题,通过语义上的匹配和语句相似度的匹配来提高问答效率。利用深度学习模型构建的智能问答将会更全面,更适合普通问答社区。
1.3论文研究课题现状
从20世纪60年代起,智能问答相关技术研究开始萌芽。由于对于语言学的重视和传统搜索引型的需求增长,到80年代智能问答已有了长足的进步。基于中文的智能问答系统的研究于70年代才开始,相比英文的智能问答起步较晚,但是目前为止,中文智能问答相关的技术已经取得了很大进展。
国外智能问答的研究应用比较早。1961年,国外出现了第一个限定域智能问答系统,该系统是由Green构建并且是为棒球领域提供问答服务。目前国外的问答系统也是数不胜数。有像Siri,Google Now和Start等著名的问答系统。
国内智能问答的研究虽然起步比较晚,但是已经取得了很大的进步。国内也有着很多诸如百度,知乎和360问答等优秀的问答系统。随着深度学习的发展,自然语言智能识别智能化程度越来越高。目前很多学者在中文智能问答方面利用深度学习和相关神经网络模型取得了很好的效果。并且对医疗,专业等限定域的研究更为深入。
1.4论文研究主要内容
本论文致力于解决传统问答方式的局限性,利用深度学习和神经网络模型等相关自然语言智能识别技术解决传统问答社区的信息冗余和问答效率低下的问题。
本论文利用现有的,比较成熟的中文分词,词向量构建等基础的自然语言智能识别技术做语言数据结构话处理,利用目前应用效果比较好的的神经网络作为构建分类器的训练模型。利用深度学习的各种算法实现基于问答语料的智能问答匹配。针对目前传统问答社区出现的问题,采用问答语料匹配解决传统问答社区信息冗余的问题。利用词向量矩阵和神经网络模型解决问答正确性并且提高问答效率。
1.5论文结构简述
本论文分为五个部分介绍该问答系统。第一部分是绪论,主要是对智能问答背景,所面临的问题和发展现状以及本论文课题的主要研究内容以及论文论述结构做相关介绍和说明。第二部分是对于本论文所要实现的问答系统做相关的系统设计和模块设计。第三部分是本论文课题的实现流程,所用模型,具体实现过程,模型优化以及实现结果分析。第四部分是总结和展望,该部分主要介绍了对于本论文研究课题的总结,对于研究课题未来展望。第五部分是致谢,主要介绍对于本论文研究课题的相关人员的感谢。
2 基于软件知识的智能问答系统设计
2.1数据来源分析设计以及爬虫设计
本论文是基于问答社区积累的问答语料库构建的智能问答系统,构建的基础知识库是来源于问答社区。获取方式是采用爬虫的方式对于问答社区进行问答信息抓取。语料来源于问答社区积累的现有语料,语料具有如下形式的语料:
![]()
其中代表现有问题集合,Q代表问题,A代表回答。
爬虫设计一共有如下五个步骤:
- 网站的选择:国内有很多的问答社区,常见的百度问答和知乎问答等著名的问答社区都有很强大的反爬虫机制。如需爬取,需要构建浏览器机制,用户名密码等权限验证。比较麻烦,本论文的爬虫爬取的是红网问答社区的问答语料,该网站反爬虫机制不是很强,爬取信息较为容易。
- 网页构成分析:该网站采用一般的分页式布局,每页有10条内容,故采用分页式的网页爬取,找出分页规律,分别对其进行爬取。针对网页问题的超链接,采取问题和答案匹配爬取。
- 针对网页的爬虫设计:由于同时爬取多个网页,利用多线程实现分布式爬取,减少爬取时间和提高爬取效率。
- 将爬取到的文本进行文本预处理,转化成需要的文本格式。
- 将爬取好的问题和答案集合写入文件并保存。
2.2 数据中文分词的分析与设计
分词技术是指把语句按照一定的规则进行划分,通过划分的各个部分可以更加充分理解整个句子的各个元素。分词手段通常可以分为词表对照的分词方法,语义理解的分词方法和基于统计学的分词方法[]。中文分词相较于英文分词难度更大,英文分词通常可以按照空格来划分语句的各个模块,中文分词则比较复杂,中文存在很多的歧义词,组合词和新生词。通常中文分词需要检查筛选歧义词,新生词,最终得到的分词结果才会更加准确。
本论文针对爬虫爬取到的问答数据,将问题集合进行分词处理。本论文中的问答语料来自于问答社区,语料具有不固定性,所以采用基于词表的分词方式将会更加准确,通常基于词表的分词方式有标准分词,NLP分词和jieba分词。本论文采用使用最多的jieba分词。
2.3 构建中文词向量的分析以及模型设计
2.3.1 词向量构建算法设计
本论文采用的词向量实现方式为目前最受欢迎的Word2vec,Word2vec是利用神经网络训练得到,可以自行输入维度大小等参数控制,并且词向量的生成非常的高效。其核心神经网络的算法主要是CBOW和skip-gram算法,针对这两种算法Word2vec也是对其进行了不同方向的优化。目前最常用有两种优化算法,从层次结构优化和负面采样优化[]。
本论文采用的是层次结构优化(Hierarchical Softmax),相比传统DNN算法,主要进行了两个方面的改进:
- 从输入层到隐藏层采用取平均值的方式代替了传统复杂的交叉权值计算。
- 从隐藏层到输出层采用的是赫夫曼树来进行优化,其优化结构如下图所示。

图 1 赫夫曼树优化模型
在核心算法上本论文采用CBOW算法。CBOW是基于统计和神经网络训练模型的算法。CBOW算法输入为上语句附近一定步长的单词词向量,输出为目标词的词向量。目标词输出的最佳词向量的值为预测上下文相关词出现平均概率最大的一次。这也是利用神经网络训练而得。其公式为:
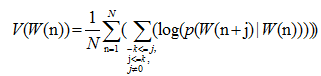
其中V是描述词向量W(n)的值,n为词向量位置,N为上下文相关词计数,j为概率词的相对位置描述,p为先验概率,利用Softmax函数刻画。log()为对于先验概率取对数的函数。
CBOW算法为词袋模型,不在乎上下文词语的距离,在CBOW算法看来,上下文相关词开始时都是同样的权重。神经网络算法图示:

图 2 CBOW神经网络结构图示
2.3.2 词向量构建模型设计
本论文利用Word2vec实现词向量矩阵的构建,Word2vec文件包是Google推出的开源工具包[],该工具包不具有实际编码性,因此本论文采用其他语言实现的开源代码。目前有python和java两个实现的版本,python直接导入gensim包即可使用,非常的简便。Java目前没有开源的jar包,幸运的是,java也有Word2vec的实现版本,使用也是非常的方便,需要根据代码和项目的实际应用进行一定程度的修改和调试,调试过程需要一定程度的了解其代码实现原理。
有了实际的编码环境,利用分词文本可是实现词向量的构建。但是完成单词的词向量的构建还不够,需要完成单词词向量的相似度计算,也就是需要输出两个单词之间的词向量相似度值输出,并且最好是利用softmax实现归一化。这一切在python里面非常的简便,所有的工具和函数也是非常的齐全,所以上述功能需求在python里可以直接调用函数直接实现。而相对于java来说就比价麻烦,java在前辈学者的基础上需要自行实现相似度的自行计算。
本论文研究课题是利用Word2vec的java版本的实现算法来构建模型。把目标问题和语料问题进行对比,通过模型训练出词向量矩阵。词向量构建形式为Wn(n1,n2,...,ni),其中W为词语,ni为W在某个维度的向量值。接着利用词向量构架相似度,得到相似度矩阵。最后达到如下图所示的词向量结构:
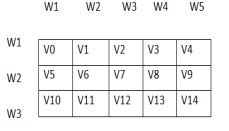
图 3 构建词向量矩阵示意图
2.5 CNN神经网络分类器的分析以及模型设计
2.5.1 卷积神经网络模型设计
CNN采用局部感知的策略,局部感知可以大幅度的简化传统神经网络的复杂度[]。CNN是一种前馈神经网络并且擅长局部提取特征作为识别依据,所以本论文采用用CNN来实现自然语言语句特征提取。
本论文首先构建好基础的四层CNN。依次为数据输入层,卷积层,池化层,全连接层。
本论文中的自然语言智能识别是通过词向量来构建数据矩阵。卷积层是对输入数据做模型训练,权值集合为卷积核,通过卷积核的局部感知实现特征提取。矩阵公式计算如下:
![]()
池化层是为了防止过拟合和去除不必要的数据,采用max-polling或者avg-pooling两种方式。max-polling池化方式是取局部矩阵词向量特征值中的最大值,avg-pooling是取局部向量值的平均值。全连接层则是采用Softmax函数实现归一化输出。
2.5.2 卷积神经网络的算法设计
针对基础的CNN模型设计出适合本论文智能问答处理CNN模型架构,采用矩阵算法实现常规的卷积核池化操作,最后达到分类效果,其模型如下图所示:

图 4 构建的CNN基础架构模型
在本模型中,输入矩阵数据来源于Word2vec构建的词向量,利用卷积公式对该矩阵循坏进行卷积操作,池化操作。本论文CNN模型图中,卷积操作的计算过程为:
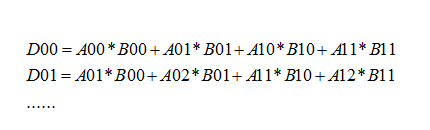
上述公式D表示进行一次卷积的下一次输出矩阵的值,D00到D01之间的距离就是卷积的移动步长。其中卷积操作为主要局部特征提取,池化操作中使用max-pooling方法来提升局部特征的明显性,也可以使用avg-pooling来实现一定程度上防止过拟合化。计算过程为:

上述公式同样表示进行一次卷积的下一次输出矩阵的值,D00到D01之间的距离就是卷积的移动步长,每卷积一次或者池化一次矩阵维度下降步长值个单位并得到相应结果。
2.5.3 卷积神经网络的模型优化
在本论文的CNN基础模型的基础上,需要针对智能问答对模型进行优化,优化好的模型如下图所示:

图 5 构建的CNN优化模型
如上图优化后的模型所示,主要进行以下三点的优化:
- 防止过拟合。从输入层到卷积核池化的中间层,会出过拟合的现象,所以本论文采用L1,L2或者标准差的方式监督算法的整个过程,拟合程度达到一定的范围便不再对矩阵值进行计算,直接进入全连接层。
- 采用RELU算法对于不必要的特征进行剔除。在前馈神经网络执行时使用RELU激活函数实现去除与模型无关的特征,该函数公式为:

- 利用问题测试集进行反馈,调参。通过调参,可以实现模型的最优值。
2.6 基于知识图谱的问答系统设计
在简单的开放域问答系统的构建中一般都是基于构建知识库来构建问答系统[]。知识库的搭建依赖于大量而且充分的问答语料,构建的知识库一般依赖于JSON或者XML文档格式来构建。本论文在基于知识图谱的问答系统构建中,为了完善本系统并且提高用户的实用性,设计实现基于知识图谱的API来实现简单问答机器人。其设计思路有如下3点:
1.调用API途经:本论文选用知识库比较强大的图灵问答机器人API,其优点在于知识库强大,问答准确性高。
2.调用方式:获取问答API的地址和密匙,通过HTTP协议访问API,使用JSON解析问答API的信息。
3.实现方式:采用java语言中的HTTP协议和JSONObject对象完成对问答API的调用。
2.7 系统软件模块设计
2.7.1系统语料预处理算法设计
基于现有问答文本语料的基础上构建问答系统,由于语料数量很大,所以对于体统算法的复杂度和空间复杂度要求也是有限制。本系统构建的算法复杂度为:
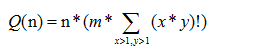
其中n表示现有语料库语句条数,m表示CNN算法复杂度,需要根据实际CNN执行次数确定,x和y分别表示构建词向量矩阵的长度大小和宽度大小。由此可见,主要影响该算法复杂度的主要因素是n。也就是需要控制语料的条数,针对智能问答的非开放域问答实现效果较好,所以设计该算法首要考虑文本预分类算法或者要求数据预分类格式。本论文所抓取的语料就是分类语料,采用朴素贝叶斯进行分类,这样可以减小对资源的占用,同时也可以提高词向量矩阵构建精准度和CNN模型的精准度。
预分类算法实现采用性能比较好的朴素贝叶斯分类算法,本论文设计使用的是多项式模型,该算法实现思路如下:
1.实现文本分词处理,并预先以一定相对广泛的定义分类。
2.统计词的出现占比。记p为目标词出现占比概率值,记n1,n2...ni为输入词,m1,m2...mi为预分类里出现的词各个分类。故构成输入词集合x=(n1,n2...ni),分类集合y=(m1,m2...mi)。
3.计算先验概率:p(w|t)=(w在样本中出现次数/总文档数)
4.计算类条件概率:
p(x|w)=p(x类下w出现次数+本身出现一次|总文档计数次数)
由于前期的分类处理,智能问答的响应时间大大较少,增加了系统的可用性。
2.7.2 系统界面模块设计
本系统实现了基于CNN的复杂问答和基于知识图谱的简单问答。系统实现采用java web实现软件的前后端搭建,所采用框架为springMvc,由于没有数据库端的实现,所以只采用一个转发框架springMvc即可。
前端采用jsp网页或者html以及一些常用的js,jq和css3技术。设计模块如 下:

图 6 问答系统模块设计
3.基于软件知识的智能问答系统实现
3.1 基于CNN神经网络分类器的问答系统
3.1.1语料库及其预处理
本论文爬取红网问答语料库,需要根据超链接去访问问题和答案的匹配集合,红网网页需要对个分类大约600多个网页进行分页爬取,并对每个网页进行回答的超链接进行大约10个超链接网页的爬取,完成一个分类文本大约需要对6600多个网页进行爬取,爬取量非常的大,所以采用多线程的方式效率会有提高[]。Python里面试下多线程使用的是import threading,其实现方式也比较简单。爬取核心代码模块如下:
#获取网页代码
def getHttpText(url):
#获取红网问答标题
def getTitle(HttpText):
#获取单页问题集
def getQuestion(HttpText):
#获取所有问题集
def getAllPage(HttpText):
#得到问题集
def mainMethod(url):
#循环遍历问题集
def allPage():
#遍历问答集
n = getHttpText("http://ask.rednet.cn/question/178535")
#d多线程爬取
def QAThread():
爬虫爬取20个网页,一共200条问答信息示例运行如图示:

图 7 爬虫爬取20个网页示例
由于本论文CNN模块研究的是复杂问答,故采用限定域问答方式。其分类文本问题集效果图如下图所示:

图 8 爬取文本集图示
上图展示的是限定为法律范围的限定域问答,其问题作为问答库。由于文本回答过长,所以采用标号的方式储存回答文本,先匹配出相似问题,再去寻找答案并展示。
3.1.2 分词构建
得到问答语料并且通过预处理得到目标问答语料集,接下来就是对于问题集合进行分词处理。本论文采用最常用的jieba分词。所采用的java实现需要导入的jar包为:
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;
import com.hankcs.hanlp.tokenizer.NLPTokenizer;
import com.huaban.analysis.jieba.JiebaSegmenter;
实现核心代码为:
JiebaSegmenter jiebaSegmenter = new JiebaSegmenter();
List
其中jiebaSegmenter.sentenceProcess(str)为结巴分词。
详细分词结果如下图所示:

图 9 三种分词结果图示
上图所示是利用java实现的三种分词形式,从结果可以看出基于词表的分词方式效果都基本相同。
3.1.3 利用Word2vec构建词向量
利用Word2vec的java实现版本实现词向量矩阵的构建,得到两个词之间的相似度,这部分在java的Word2vec的实现版本中需要自行实现,具体核心实现代码如下:
public float wordDis(String queryword1, String queryword2) {
//获取现有wordMap词表映射关系,wordMap为已经训练好的词表
float[] vector1 = wordMap.get(queryword1);
float[] vector2 = wordMap.get(queryword2);
float dist = 0;
if (vector1 == null || vector2 ==null) {
return 0;
}
for (int i = 0; i < vector1.length; i++) {
dist += vector1[i] * vector2[i];//根据各个词向量维度计算相似度
}
return dist;
}
接下来就是根据相似度分词和java中的jieba分词构建词向量矩阵,本论文构建的词向量矩阵如下图所示:

图 10 词向量分词矩阵构建图示
3.1.4 利用CNN神经网络构建分类器
本论文选取CNN作为文本分类器,利用3.1.3中的词向量矩阵作为输入,利用CNN神经网络作为分类器来训练词向量矩阵。首先对该输入矩阵进行卷积核池化,根据卷积算法,核心算法的java实现版本代码如下图所示:
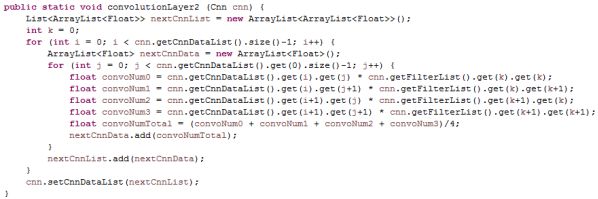
图 11 CNN卷积层实现卷积算法
如上图所示,该示例算法为二维的卷积核的卷积算法实现,其核心为对输入举证的局部特征进行一次的提取。池化层相对实现算法比较容易,下图为卷积一次和池化一次的数据值对比:

图 12 CNN卷积和池化输出结果图
另外,为了防止过拟合化或者特征提取不充分,该模型使用标准差来实现模型精度监测和防止过拟合化,下图为防止过拟合效果展示:
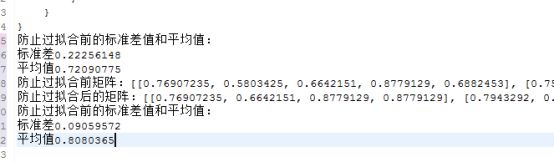
图 13 CNN防止过拟合效果图示
由上图可知防止过拟合化后提高的效果明显。标准差减小,得到数据平均值增大。另外前馈神经网络执行时使用RELU激活函数实现去除与模型无关的特征,该函数公式为:

例子1:
如下两个字符串:
String str0 = "哪些交通违规行为可以不被处罚";
String str1 = "不被处罚的交通行为有哪些";
相似度结果如下图:

图 14 CNN模型输出示例1
例子2:
如下两个字符串:
String str0 = "哪些交通违规行为可以不被处罚";
String str1 = "机动车驾驶人的哪些驾驶行为会被扣分";
相似度结果为:
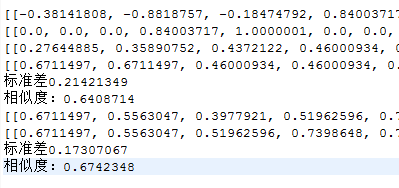
图 15 CNN模型输出示例2
由例1和例2可知,都是相同领域的问句,句意相同的标准差收敛的很快,效果较好。而句意相反,表达相似的句意标准差收敛比较慢,最后相似度效果较差。
3.1.6 模型评估与结果分析
本系统利用人工选取一定的测试集合对模型进行评估,分别实现了初始化模型的结果和优化后的模型结果。本模型评估测试集是基于语义上的匹配,也就是这个测试集语言表达方式会有大幅度的不同,而语义层面上却是相同的测试集。相对而言结果也会存在误差。在预料结果之内。评估结果入下表所示:

图 16 CNN模型评估
目前实现本论文智能问答实现模型为CNN模型,CNN模型非常适合图像识别领域。构建多通道和不同的卷积权值。相比CNN在图像领域的模型构建,CNN在文本特征提取方面显得更简单而且直接。为了保留文本的原有特征,卷积权值一般初始化为单位值1。相比变化的卷积权值效果更好。而且通常CNN在文本领域都是以单通道作为入口进行计算,模型简单而且取得了不错的效果。
3.2 基于知识图谱构建问答系统
基于语言结构关系构建知识库来实现问答匹配是目前处理简单问答的主要应用技术[]。构建知识库主要需要两个步骤,建立实体关系和实体关系链接[]。建立实体关系就是抽取出问答信息库中的实体,建立起实体之间的关系描述,通过实体关系链接来确定实体关系并作出回应[]。主要的实现方式有语义判断,实体信息抽取和词向量描述。本论文为了完善该问答系统,调用现有比较强大的图灵知识库api来实现简单的聊天问答,实现步骤为:
- 获取知识库API并解析。通过用户注册得到应用图灵知识库api的权限。获取到使用密匙和调用URL。
![]()
图 17 图灵API调用key和访问地址
- 利用java中的JSONObject对象解析图灵api的json数据格式。
输入json格式:

图 18 调用图灵API输入JSON格式
输出json格式:

图 19 图灵API调用输出格式
调用java的JSONObject对象解析即可实现api的调用。
- 调用该api实现简单提问并获取回答,实现效果如下图:

图 20 调用图灵API问答效果图
3.3 问答匹配算法和系统可视化的构建
由于系统设计是实现开放域问答,目前使用的CNN分类器在限定域分类想过较好,所以系统采用朴素贝叶斯算法来实现预分类处理,其实现java代码模块如下:
//获取关键词
getKeyWord();
//从文件中读取出分类的数据
readData();
//统计关键词出现在分类文本中的次数
getCountKeyWordClass();
//计算关键词出现在分类文本中的概率
getChanceKeyWord();
//统计关键词出现在总文本中的次数
getCountKeyWordAllText();
//统计关键词同时出现在所有文本中的概率
getChanceKeyWordSameTime();
//使用朴素贝叶斯算法求出分类的概率
classByBayes();
其分类测试效果如下:

图 21朴素贝叶斯分类效果图
系统构建目的提高用户体验系数,所以适合采用简洁,美观,大方的模块设计。系统可视化构建模块如下:
问答模块:

图 22 问答系统问答模块界面设计
用户登录注册模块:

图 23问答系统登录注册模块设计
用户管理模块:该模块直接后台操作即可。
4 结论
由分类模型结果来看,CNN模型在文本分类领域同样也有非常好的效果。利用局部感知同样也可以延伸到全局。本论文实现的CNN模型针对文本特征进行了模型改造和优化,开始使用贝叶斯公式进行预分类,提升了CNN词向量矩阵的准确率,从开放域问答缩小到非开放域问答,其实现效果得到了提升。其次对于CNN模型进行了拟合化监测和反馈神经网络的调参。这在一定程度上完善了CNN模型,提升了CNN的模型分类准确率。
本系统还实现了对于CNN不同维度的卷积核调试,得到最佳结果维度选择。本系统同时也对于CNN卷积层的通道,卷积核的参数值进行了相应的调整,达到最符合文本相似度的模型预期。
其次,本系统还构建了简单问答系统,通过调用问答API实现简单问答,提升了系统的可使用性。本系统通过构造简洁,美观的系统构建了智能问答系统。本系统具有 很高的可使用性。
最后,本系统也存在一定需要改进的地方,在文本匹配准确度当然越高越好。本系统的语料库构建还比较小,导致了后续词向量和分类构建的不准确性,在一定程度上限制了模型的实现能力。期望后续能构建充足的语料库和更高效的算法来提升该系统的问答效率。
参考文献
[]本刊讯.Google开源BERT模型源代码[J].数据分析与知识发现,2018,2(11):18.
[] 张华,李超.Java课程智能问答系统设计与实现[J].计算机时代,2018(12):12-15.
[]张素荣. 智能客服问答系统关键算法研究及应用[D].南京邮电大学,2018.
[]李翠霞.现代计算机智能识别技术处理自然语言研究的应用与进展[A].中国知网.2012.
[] 曹艳蓉. 基于中文社区的智能问答系统的设计与研究[D].南京邮电大学,2018.
[] 何冠辰.人工智能与中文分词的研究[J].中国新通信,2019,21(04):66-68.
[]周练.Word2vec的工作原理及应用探究[A].中国知网.2015.吴军.数学之美[M].北京:人民邮电出版社.2012.
[]宋添树,李江宇,张沁哲.基于CBOW模型的个人微博聚类研究[J].电脑与电信,2018(04):69-72.
[] Tomas Mikolov.Word2vec project [EB/OL].[2014-09-18].https://code.google.com/p/word2vec/.
[]Huang Xian-ying, Chen Hong-yang, Liu Ying-tao, et al.A novel feature word selecting method of micro-blog short text[J].Computer Engineering&Science, 2015, 37 (9) :1761-1767. (in Chinese).
[]胡美玉,张云洲,秦操,刘桐伯.基于深度卷积神经网络的语义地图构建[J/OL].机器人:1-12[2019-05-16].https://doi.org/10.13973/j.cnki.robot.180406.
[]Yoon Kim.Convolutional Neural Networks for Sentence Classification.Wed, 3 Sep 2014 03:09:02 GMT (41kb,D).Cornell University Library.
[]刘建平.卷积神经网络(CNN)模型结构[J].博客园,[2017.03.01].https://www.cnblogs.com/pinard/p/6483207.html
[]]Huang Xian-ying, Chen Hong-yang, Liu Ying-tao,et al.A novel feature word selecting method of micro-blog short text[J].Computer Engineering&Science, 2015, 37 (9) :1761-1767. (in Chinese).
[]Dinghan Shen1.Martin Renqiang Min2.Yitong Li1.Lawrence Carin1.Learning Context-Sensitive Convolutional Filters for Text Processing[J]. Duke University1.NEC Laboratories America2.2018.
[]陈优敏.知识图谱构建方法探究[J].中国新通信,2019,21(05):215.
[]李文宽,刘培玉,朱振方,刘文锋.基于卷积神经网络和贝叶斯分类器的句子分类模型[J/OL].计算机应用研究:1-6[2019-05-16].https://doi.org/10.19734/j.issn.1001-3695.2018.07.0525.
[]邵晓文.多线程并发网络爬虫的设计与实现[J].现代计算机(专业版),2019(01):97-100.
[]袁若瀛.知识图谱系统研发[J].现代信息科技,2019,3(05):13-17.
[]李星宇,王丽娟.基于古诗文知识图谱的诗词创作系统[J].计算机产品与流通,2019(04):106.
[]结合卷积神经网络和词语情感序列特征的中文情感分析[J]. 陈钊,徐睿峰,桂林,陆勤. 中文信息学报. 2015(06).