爬虫实践---正方教务系统爬取历年成绩
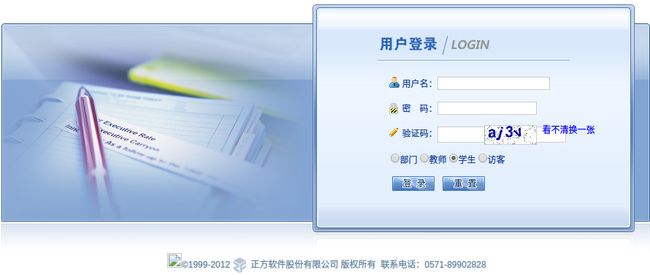
打开学校教务处官网,发现官网的地址其实是http://222.24.19.201/default2.aspx
这次的爬虫既有账号密码登录,也有验证码和登录角色选择,有点难度了,搞了两天才搞定,看来还是才疏学浅了,通过这个博客将知识点已经坑点等方面进行总结,也是一个学习的过程。
大体思路:
一.确认教务处官网
1.随便登录用户密码,确认From Data
2.确定验证码链接
二.初步访问
4.构造自己的data,确认访问形式是post
5.打开网页,获取Cookie,获取验证码图片,完善data并用它post访问教务处官网
6.获取登陆后自己姓名,确认是否登录成功
三.成绩查询
7.确认成绩查询页面,完善Headers
8.初步访问获取网页验证,得到referer
9.构造data,并且使用它爬取历年成绩
四.瞅瞅全是60分飘过,心好累
第一步,打开F12中的下面界面。

通过登录一个错误账号,我们可以发现,
Request URL:http://222.24.19.201/default2.aspx
Request Method:POST__VIEWSTATE:dDwtNTE2MjI4MTQ7Oz40VgXJB8DXjui8rTCUMZ5zS6eY7w==
#教务处网站的识别,其gb2312格式=dDwtNTE2MjI4MTQ7Oz40VgXJB8DXjui8rTCUMZ5zS6eY7w%3D%3D
txtUserName:04151106 #登录的学号
Textbox1:
TextBox2:123456 #密码
txtSecretCode:aj3v #验证码
RadioButtonList1:(unable to decode value)
# 选择学生身份登录 = %D1%A7%C9%FA
#这个是网站的GB2312编码格式,我们通过点击URl encoded可以看到编码,后面我们将一直采用这种格式来看
Button1:
lbLanguage:
hidPdrs:
hidsc:之前利用encode('gb2312')进行转码的时候遇见了如下情况
>>> name = "你好"
>>> res = name.encode('gb2312')
>>> res = str(res)
>>> print(res)
# OUT
b'\xc4\xe3\xba\xc3'然而我们需要的是字符串格式的,经过百般查询资料,询问大佬,终于解决了这个问题,学生身份的登录就OK了
>>> from urllib import parse
>>> hanzi = "你好"
>>> res = hanzi.encode('GBK')
>>> print(parse.quote(res))
# OUT
%C4%E3%BA%C3
接下来要 解决验证码的问题

发现了验证码的地址,哈哈!!!可以用下面的方法将验证码下载下来,观察后手动输入。后续我试试能不能自动识别验证码!
# 这是Python的一个非常有名的图片库,这里我们用它来显示验证码
from PIL import Image
pic=requests.get(url_check,cookies=Cookie,headers=headers)
with open(r'ver_pic.png','wb')as f:
f.write(pic.content)
# 打开验证码图片
image = Image.open('{}/ver_pic.png'.format(os.getcwd()))
image.show()
ycode=input("输入弹出的验证码: ")对了,还用教务处网站里面的死长的鬼东西需要抠出来才能登录成功,那就将它抓出来
![]()
soup = bs4.BeautifulSoup(webpage.text, 'lxml')
# 熬汤
# 找到form的验证参数,教务处网站存在着验证---"__VIEWSTATE"
__VIEWSTATE = soup.find('input', attrs={'name': '__VIEWSTATE'})['value']好像 data已经构造完成啦,就差学号和密码啦!!!
不管三七二十一,先把代码贴上来
import requests
import re
import urllib.request
import os
import bs4
import http.cookiejar
from urllib import parse
# 这是Python的一个非常有名的图片库,这里我们用它来显示验证码
from PIL import Image
# 验证码
webpage=requests.get(url = 'http://222.24.19.201/default2.aspx')
cookie=webpage.cookies
# 获取网页cookies
print(cookie)
soup = bs4.BeautifulSoup(webpage.text, 'lxml')
# 找到form的验证参数
__VIEWSTATE = soup.find('input', attrs={'name': '__VIEWSTATE'})['value']
headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'}
url_check='http://222.24.19.201/CheckCode.aspx'
#验证码所在连接
pic=requests.get(url_check,cookies=cookie,headers=headers)
with open(r'ver_pic.png','wb')as f:
f.write(pic.content)
username=input("输入用户名: ")
password=input("输入密码 ")
# 打开验证码图片
image = Image.open('{}/ver_pic.png'.format(os.getcwd()))
image.show()
ycode=input("输入弹出的验证码: ")
payload={
'__VIEWSTATE':__VIEWSTATE,
'txtUserName':username,
'TextBox2':password,
'txtSecretCode':ycode,
'RadioButtonList1':'%D1%A7%C9%FA',#学生GB2312格式
'Button1':"",
'lbLanguage':'',
'hidPdrs':'',
'hidsc':'',
}
Log_in=r"http://222.24.19.201/default2.aspx"
r=requests.post(url=Log_in,data=payload,headers=headers,cookies=cookie)
# 测试看看是否能找到登陆后的信息
#print(r.headers)
soup = bs4.BeautifulSoup(r.text, 'lxml')
#print(soup.headers)
try:
name = soup.find('span', attrs={'id': 'xhxm'}).text
except:
name = '登录失败 '
print(name)哈哈,是不是很激动呢,下来我们需要进行下一步获取历年成绩啦!
![]()
这样我们就偷渡进来啦,

对历年成绩进行甄别

Request URL:http://222.24.19.201/xscjcx.aspx?xh=XXXXXXXX&xm=XXXXXXXX&gnmkdm=XXXXXXXX
Request Method:GET我们看到访问页面发生变化了,访问形式也变成GET了
xh=XXXXXXXX#自己的学号
xm=XXXXXXXX#自己姓名的GB2312格式
gnmkdm=XXXXXXXX#选择的选项
我们在网页里面有发现了那个讨厌的死长怪物
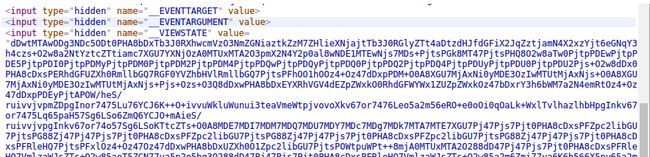
所以我们应该先get一次网页,将这个网页验证扒下来,才能做其他事情,我第一次写的时候,发现了出现下面的情况

这是为什么呢?不卖关子了,由于在网页的Request Headers里面,
Referer:http://222.24.19.201/xscjcx.aspx?xh=XXXXXX&xm=XXXXXX&gnmkdm=N121605这个东西的存在,网页才允许我们进行下一步的查询操作,否则就会出现上面哪个错误。看来我们需要 对Headers进行改进了。
latest_headers={
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36',
'Referer':'http://222.24.19.201/xscjcx.aspx?xh='+ID+'&xm='+name+'&gnmkdm=N121605',
'Cookie': cookie,
#扩大适用性
} Cookie = webpage.cookies #获取访问教务处的cookie
for c in Cookie:
cookie=c.name+'='+c.value ASP.NET_SessionId=zr4xqczw4axpapjej0g2vh45
上面那个是网页返回的Cookie,格式和我们Headers里面需要的格式时第二种,然而c.name=ASP.NET_SessionId, c.value=zr4xqczw4axpapjej0g2vh45,这样我们就可以耍点小九九来偷渡哈哈。


我们还需要最后btn_zcj:XXXXXX 从上面呢个发现这个就是历年成绩,后面哪个是历年成绩的gb2312编码。
# 找到form的验证参数
__VIEWSTATE_1 = soup.find('input', attrs={'name': '__VIEWSTATE'})['value']
name_1 = "历年成绩"
res = name_1.encode('GBK')
name_1 = parse.quote(res)
data_1 = {
'__VIEWSTATE':__VIEWSTATE_1,
'btn_zcj': name_1,
}这样呢,大体的思路就是这样。
下面呢,整个代码就是这样子:
访问我的GitHub