MySQL的InnoDB的表数据存储原理和优化原理分析
前言
正文
1, InnoDB行记录格式
InnoDB存储引擎和大多数据库一样,记录是以行的形式存储的。 这意味着页中保存着表中一行行的数据。到MySQL5.1时,InnoDB存储引擎提供了Compact和Redundant两种格式来存放行记录数据,Redundant是为兼容之前版本而保留的,如果你阅读过InnoDB的源代码,会发现源代码张红是用PHYSICAL RECORD(NEW STYLE)和PHYSICAL RECORD (OLD STYLE)来区分两种格式的。MySQL5.1默认保存为Compact行格式。你可以通过命令SHOW TABLE STATUS LIKE ‘table_name’;来查看当前表使用的行格式,其中row_format就代表了当前使用的行记录结构类型。
mysql> show table status like 't_test%';
+--------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+-------------------+----------+--------------------+---------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment |
+--------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+-------------------+----------+--------------------+---------+
| t_test | InnoDB | 10 | Compact | 8 | 2048 | 16384 | 0 | 0 | 0 | NULL | 2019-07-30 11:14:24 | 2019-07-30 13:21:51 | NULL | latin1_swedish_ci | NULL | row_format=COMPACT | |
+--------+--------+---------+------------+------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+---------------------+------------+-------------------+----------+--------------------+---------+
1 row in set
可以看到,这里t_test表是Compact的行格式。
① Compact行记录格式
Compact行记录是在MySQL 5.0时被引入的,其设计目标是能高效存放数据。简单来说,如果一个页中存放的行数据越多,其性能就越高。Compact行记录以如下发送进行存储。
| 变长字段长度列表 | NULL标志位 | 记录头信息 | 列1数据 | 列2数据 | … |
|---|
从上表格中可以看到,Compact行格式的首部是一个非NULL变长字段长度列表,而且是按照列的顺序逆序放置的。当列的长度小于255字节,用1字节表示,若大于255个字节,用2个字节表示,变长字段的长度最大不可以超过2个字节(这也很好地解析了为什么MySQL中varchar的最大长度为65535,因为2个字节为16位,即2的16次方=65534)。第二个部分是NULL标志位,该位指示了该行数据中是否有NULL值,用1表示。该部分所占的字节应该为bytes。接下去的部分是为记录头信息(record head),固定占用5个字节(40位)。最后的部分就是时间匆匆的目光列的数据了,需要特别注意的是,NULL不占该部分如果数据,即NULL除了占有NULL标志位,实际存储不占有任何空间。另外有一点需要注意的是,每行数据除了用户定义的列外,还有两个隐藏列,事务ID列和回滚指针列,分别为6个字节和7个字节的大小。若InnoDB表没有定义primary key, 每行还会增加一个6字节的RowID列。
- 变长字段长度列表
默认都插入数据 默认是 01 01 01
Compact页格式
| 名称 | 大小(bit) | 描述 |
|---|---|---|
| () | 1 | 未知 |
| () | 1 | 未知 |
| deleted_flag | 1 | 该行是否移交被删除 |
| min_rec_flag | 1 | 为1,如果该记录是预先被定义为最小的记录 |
| n_owned | 4 | 该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该记录的排序记录 |
| record_type | 3 | 记录类型000=普通 001=B+树节点指针 010=Infimum 011=Supremum 1xx=保留 |
| next_recorder | 16 | 页中下一条记录的相对位置 |
分析图
① Redundant行记录格式
Redundant是MySQL 5.0版本之前InnoDB的行记录存储方式,MySQL5.0支持Redundant是为了向前兼容性。Redundant行记录以如下发送存储:

| 字段长度偏移列表 | 记录头信息 | 列1数据 | 列2数据 | … |
|---|
从上图看到, 不同于Compact行记录格式,Redundant行格式的首部是一个字段长度偏移列表,同样是按照的顺序逆序放置的。当列的长度小于255字节,用1字节表示,若大于255个字节,用2个字节表示。第二个部分为记录头信息(record header),不同于Compact行格式, Redundant行格式固定占用6个字节(48位),每位的见小标,从表中可以看到,n_fields值代表一行中列的数量,占用10位,这也很好地解释了为什么MySQL一个行支持最多的列为1023.另一个需要注意的值为1byte_offs_flags,该值定义了偏移列表占用1个字节还是2个字节。最后的部分就是实际存储的目光列的数据了。
Redundant页格式
| 名称 | 大小(bit) | 描述 |
|---|---|---|
| () | 1 | 未知 |
| () | 1 | 未知 |
| deleted_flag | 1 | 该行是否已经被删除 |
| min_rec_flag | 1 | 为1,如果该记录是预先被定义为最小的记录 |
| n_owned | 4 | 该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该条记录的排序记录 |
| n_fields | 10 | 记录中列的数量 |
| 1byte_offs_flag | 1 | 偏移列表位1个字节还是2个字节 |
| next_record | 16 | 页中下一条记录的相对位置 |
23 20 16 14 13 0c 06,逆序为06, 0c, 13, 14, 16, 20, 23。分别代表第一列长度6,第二列长度6(6+6=0x0c),第三列长度为7(6+6+7=0x13),第四列长度1(6+6+7+1=0x14),第五列长度2(6+6+7+1+2=0x16),第六列长度10(6+6+7+1+2+10=0x20),第七列长度3(6+6+7+1+2+10+3=0x23)。
接着的记录头头信息中应该注意48位中22~32位,位0000000111,表示表共有7个列(包含了隐藏的3列),接下去的33位为1,代表偏移列表为应该字节。
2, InnoDB数据页结构
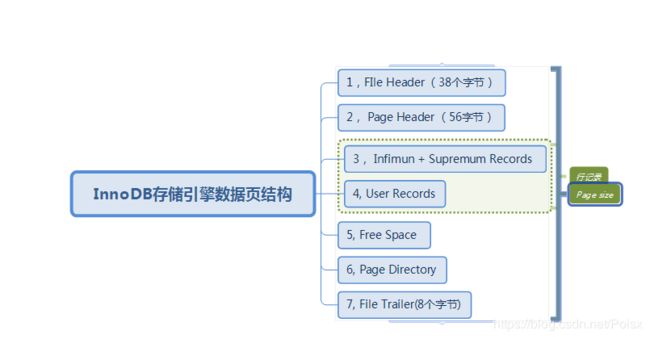
InnoDB数据页由以下7个部分组成,
- File Header(文件头)38个字节
- Page Header (页头)56个字节
- Infimun 和 Supremum Recoreds
- User Record(用户记录,即行记录)
- Free Space(空闲空间)
- Page Directory(页目录)
- File Trailer (文件结尾信息)8个字节
其中File Header, Page Header, File Tailer的大小是固定的,分别为38,56,8字节,这些空间用来标记该页的一些信息,如Checksum,数据页所在B+树索引的层数等,User Records, Free Space, Page Directory这些部分为实际的行记录存储空间,因此大小是动态的。在接下来的各小小结中即将具体分析各组成部分。
① File Header
File Header用来记录页的一些头信息,由如下8个部分组成,共占用38个字节。
FIle Header组成部分
| 名称 | 大小(字节) | 描述 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4 | 当MySQL版本小MySQL-4.0.14,该值代表该页属于哪个表空间,因为如果我们没有开启innodb_file_per_table,共享表空间中可能存放许多页,不去这些也属于不同的表的空间。之后版本的MySQL,该值代表页的checksum值(一种新的checksum值)。 |
| FIL_PAGE_OFFSET | 4 | 表空间中页的偏移值。 |
| FIL_PAGE_PREV | 4 | 当前页的上一个页B+Tree特性决定了叶子节点必须是双向列表。 |
| FIL_PAGE_NEXT | 4 | 当前页的下一个页。B+Tree特性决定了叶子节点必须是双向列表。 |
| FIL_PAGE_LST | 8 | 该值代表该页最后被修改的日子序列位置LSN(Log Sequence Number)。 |
| FIL_PAGE_TYPE | 2 | 页的类型。通常有以下几种类型 请记住0x45BF,该值代表了存放的数据页。 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 该值仅在数据挖掘中的一共页中定义,代表挖掘至少被更新到了该LSN值。 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4 | 从MySQL 4.1开始,该值代表页属于哪个表空间。 |
Page类型表
| 名称 | 十六进制 | 解析 |
|---|---|---|
| FIL_PAGE_INDEX | 0x45BF | B+树叶节点 |
| FIL_PAGE_UNDO_LOG | 0x0002 | Undo Log页 |
| FIL_PAGE_INODE | 0x0003 | 索引节点 |
| FIL_PAGE_IBUF_FREE_LIST | 0x0004 | Insert Buffer空闲列表 |
| FIL_PAGE_TYPE_ALLOCATED | 0x0000 | 该页为最新分配 |
| FIL_PAGE_IBUF_BITMAP | 0x0005 | Insert Buffer位图 |
| FIL_PAGE_TYPE_SYS | 0x0006 | 系统页 |
| FIL_PAGE_TYPE_TRX_SYS | 0x0007 | 事务系统数据 |
| FIL_PAGE_TYPE_FSP_HDR | 0x0008 | File Space Header |
| FIL_PAGE_TYPE_XDES | 0x0009 | 扩展描述页 |
| FIL_PAGE_TYPE_BLOB | 0x000A | BLOB页 |
② Page Header
接着FIle Header部分的是Page Header, 用来记录数据页的状态信息。由以下14个部分组成,共占用56个字节。
Page Header 组成部分
| 名称 | 大小(字节) | 描述 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | 在Page Directory(页目录)中的Slot(槽)数。 |
| PAGE_HEAP_TOP | 2 | 堆中第一个记录的指针。 |
| PAGE_N_HEAP | 2 | 堆中的记录数。 |
| PAGE_FREE | 2 | 指向空闲列表的首指针。 |
| PAGE_GARBASGE | 2 | 已删除记录的字节数,即行记录结构中,delete flag 为1的记录大小的总数。 |
| PAGE_LAST_INSERT | 2 | 最后插入记录的位置。 |
| PAGE_DIRECTION | 2 | 最后插入的方向。可能的取值为PAGE_LEFT(0x01),PAGE_RIGHT(0x02),PAGE_SAME_REC(0x03),PAGE_SAME_PAGE(0x04),PAGE_NO_DIRECTION(0x05) |
| PAGE_N_DIRECTION | 2 | 一个方向连接插入记录的数量。 |
| PAGE_N_RECS | 2 | 该页中记录的数量。 |
| PAGE_MAX_TRX_ID | 8 | 修改当前页的最大事务ID,注意该值仅在Secondary Index定义。 |
| PAGE_LEVEL | 2 | 当前页在索引树中的位置,0x00代表叶节点。 |
| PAGE_INDEX_ID | 8 | 当前页属于哪个索引ID。 |
| PAGE_BTR_SEG_LEAF | 10 | B+树的叶节点中,文件段的首指针位置。注意该值仅在B+树的Root页中定义。 |
| PAGE_BTR_SEG_TOP | 10 | B+树的非叶节点中,文件段的首指针位置。注意该值仅在B+树的Root页中定义。 |
③ Infimum和Supremum记录
在InnoDB存储引擎中,每个数据页中有两个虚拟的行记录,用来限定记录的边界。Infimum记录是比该页中任何主键值都要小的值,Supremum指比任何困难大的值还要大的值。这两个值在页创建时被建立,并且在任何情况下班后被删除。在Compact行格式和Redundant行格式下,两者占用的字节数各不相同。
④ User Records与FreeSpace
User Records 是实际存储行记录的内容。InnoDB存储引擎表总是B+树索引组织的。
Free Space 指的就是空闲空间,同样也是个链表数据结构。当一条记录被删除后,该空间会被加入空闲链表中。
⑤ Page Directory
Page Directory(页目录)中存放了记录的相对位置(注意,这里存放的是页相对位置,而不是偏移量),有些时候最小记录指针称为slots(槽)或者目录槽(Directory Slots)。与其他数据库系统不同的是,InnoDB并不是每个记录拥有一个槽,InnoDB存储引擎的槽是一个稀疏目录(sparse directory),即一个槽中可能属于(belong to)多个记录,最少属于4条记录,最多属于8条记录。
Slots中记录安装键顺序存放,这样可以利用二叉查找迅速找到记录的指针。假设我们有(‘i’, ‘d’, ‘c’, ‘b’, ‘e’, ‘g’, ‘l’, ‘h’, ‘f’, ‘j’, ‘k’, ‘a’),同时假设一个槽中包含4条记录,则Slots中的记录可能是(‘a’, ‘e’, ‘i’)。
由于InnoDB存储引擎中Slots是稀疏目录,二叉查找的价格指数一个粗略的价格,所以InnoDB必须通过recorder header 中next_record来继续查找相关记录。同时,slots很好地解析了recorder header 中的n_owned值的含义,即还有多少记录需要查找,因为最小记录并不包含在slots中。
需要牢记的是,B+树索引本身并不能找到具体的一条记录,B+树索引能找到指数该记录所在的页。数据库把页载入内存,然后通过Page Directory在进行二叉查找。只不过二叉查找的时间复杂度很低,同时内存中的查找很快,因此通常我们忽略了这部分查找所用的时间。
⑥ File Trailer
为了保证页能够完整地写入磁盘(如可能发生的写入过程中磁盘损坏,机器宕机等原因),InnoDB存储引擎的页中设置了File Trailer部分。File Tailer只有一个FIL_PAGE_SPACE_OR_CHKSUM和FIL_PAGE_LSN值较小比较,看是否一致(checksum的比较需要通过InnoDB的checksum函数来进行比较,不是简单的等值比较),以此来保证页的完整性(corrupted)。
3, InnoDB 数据页结构分析
首先创建一个表的, 导入一定量的数据:
drop table if exists `t_test_innodb_data`;
create table `t_test_innodb_data`(
`a` int unsigned not null auto_increment,
`b` char(10),
primary key(`a`)
)ENGINE=InnoDB CHARSET=UTF8;
-- 存储过程
delimiter $$
create procedure load_t(count int unsigned)
begin
set @c = 0;
while @c < count do
insert into `t_test_innodb_data` select null, repeat(char(97+rand()*26), 10);
set @c=@c+1;
end while;
end;
$$
delimiter;
-- 调用
call load_t(100);
接下来使用 py_innodb_page_info 来分析t_test_innodb_data.ibd 信息
python py_innodb_page_info.py C:\wamp\bin\mysql\mysql5.7.14\data\chensong\t_test_innodb_data.ibd -v
page offset 00000000, page type
page offset 00000001, page type
page offset 00000002, page type
page offset 00000003, page type , page level <0000>
page offset 00000000, page type
page offset 00000000, page type
Total number of page: 6:
Freshly Allocated Page: 2
Insert Buffer Bitmap: 1
File Space Header: 1
B-tree Node: 1
File Segment inode: 1
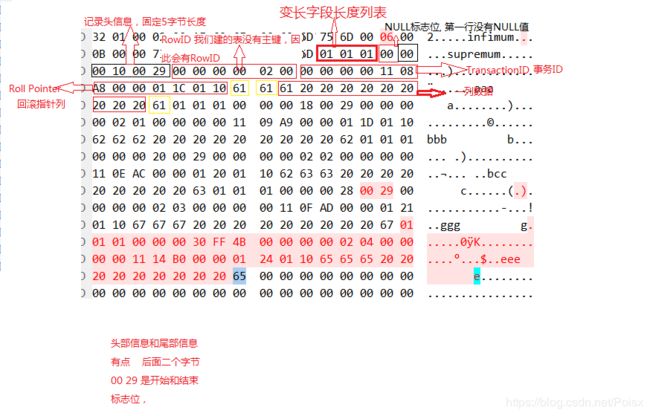
看到第四个页(page offset 3)是数据页,然后通过hex来分析.ibd文件,打开整理得到的十六进制文件,数据页在0x0000c000h(16K*3=0xc000)处开始,得到以下内容:

先来分析前面File Header的38个字节:
- CC AB 6E 4F 数据页的Checksum值。
- 00 00 00 03 页的偏移量, 从0开始
- FF FF FF FF 前一个页,因为只有当前一个数据页,所以这里为0xFFFFFF。
- FF FF FF FF 下一个页,因为只有当前一个数据页,所以这里为0xFFFFFF。
- 00 00 00 00 00 27 FA AC 页的LSN 占8字节
- 45 BF 页类型, 0x45BF代表数据页。
- 00 00 00 00 00 00 00 这里暂时不管该值。
- 00 00 00 00 表空间的SPACE ID
来看一下File Trailer部分。因为FIle Trailer 通过比较File Header部分来保证页写入的完整性。

CC AD 6E 4F Checknum值,该值通过checksum函数和File Header部分的checksum值较小比较。
00 27 FA AC 注意到该值和File Header部分也的LSN后4个值相等。
接下来分析56个字节的Page Header 部分。对于数据页而言,Page Header部分保存了该页中行记录大大量细节信息。分析后可得
page Header (56 bytes)
PAGE_N_DIR_SLOTS = 0x001A
PAGE_HEAP_TOP = 0x0DC0
PAGE_N_HEAP = 0x8066
PAGE_FREE = 0x0000
PAGE_GARBAGE = 0x0000
PAGE_LAST_INSERT = 0x0DA5
PAGE_DIRECTION = 0x0002
PAGE_N_DIRECTION = 0x0063
PAGE_N_RECS = 0x0064
PAGE_MAX_TRX_ID = 0x0000000000000000
PAGE_LEVEL = 0x0000
PAGE_INDEX_ID = 0x000000000000002B
PAGE_BTR_SEG_LEAF = 0x0000001F0000000200F2
PAGE_BTR_SEG_TOP = 0x0000001F000000020032
PAGE_N_DIR_SLOTS = 0x001A ,代表Page Directory有26个槽,每个槽占用2字节,我们可以从0x0000FFC4到0x0000FFF7中找到如下内容:

PAGE_HEAP_TOP = 0x0DC0,代表空闲开始位置开始位置的偏移量,即0xC000 + 0x0DC0 = 0xCDC0处开始,观察这个位置的情况,可以发展这的确是最后一行的结束,接下去的部分都是空闲空间了
PAGE_N_HEAP = 0x8066,当行记录格式位Compact时,初始值位0x0802,当行格式位Redundant时,初始值是2.其实这些值表示也初始时就已经有Infnimun和Supremum的伪记录行,0X8066 - 0X8002 = 0X64,代表该页中实际的记录有100条记录。
PAGE_FREE = 0x0000,代表可重用的空间首地址,因为这里没有进行过任何删除操作,故这里的值为0.
PAGE_GARBAGE = 0x0000, 代表删除的记录字节为0,同样因为我们没有进行过删除操作,这里的值依然为0
PAGE_LAST_INSERT = 0x0DA5,表示页最后插入的位置的偏移量,即最后的插入位置应该在0XC0000 + 0X0DA5 = 0XCDA5,
可以看到的确是最后插入a列值为100的行记录,但是这次直接指向了行记录的内容,而不是指向行记录的变长字段长度的列表位置。
PAGE_DIRECTION = 0x0002,因为通过自增长的方式进行行记录的插入,所以PAGE_DIRECTION的方向是向右,为0X0002.
PAGE_N_DIRECTION = 0x0063, 表示一个方向连续插入记录的数量,因为我们是自增长的方式插入了100条记录,因此该值为99.
PAGE_N_RECS = 0x0064,表示该页的行记录数为100,注意该值与PAGE_N_HEAP的比较,PAGE_H_HEAP包含两个伪行记录,并且是通过有符号的方式记录的,因此值为0X8066.
PAGE_LEVEL = 0x0000,代表该页为叶子节点。因为数据量目前比较少,因此当前B+树索引只有一层。B+树叶子层总是为0X00。
PAGE_MAX_TRX_ID = 0x0000000000000000, 索引ID
上面就是数据页的Page Header部分了,接下去就是存放的行记录了,前面提到过InnoDB存储引擎有两个伪记录,用来限定行记录的边界,接着往下看:

观察0XC05E到0XC077,这里存放的技术这两个伪行记录,在InnoDB存储引擎中设置伪行只有一个列,且类型是Char(8),伪行记录的读取发送和一般的行记录并无不同,我们整理后可以得到如下结果:
# Infimum 伪行记录
01 00 02 00 1C // recorder header
69 6E 66 69 6D 75 6D 00 // 只有一个列的伪行记录,记录内容就是Infimum(多了一个0X00字节)
# Supremum 伪行记录
05 00 0B 00 00 // recorder header
73 75 70 72 65 6D 75 6D // 只有一个列的伪行记录,记录内容就是Supremum
然后来分析infimum行记录的recorder header部分,最后两个字节位00 1C 表示下一个记录的位置的偏移量,即当前行记录内容的位置0XC063 + 0X001C,即0XC07F,0XC07F应该很熟悉了,之前分析的行记录结构都是从中国位置开始,如:

可以看到这就是第一条实际行记录内容的位置了,整理后我们可以得到:
00 00 01 // 因为我们在创建表是设置主键,这里的ROWID即为列a的值1
00 00 00 00 11 31 // Transaction ID
A5 00 00 00 01 19 01 // Roll Pointer
10 // 列a的值
76 76 76 76 76 76 76 76 76 //列b的值'vvvvv'
这和查询表得到的数据是一致的:
select a, b, hex(b) from `t_test_innodb_data` ORDER BY `a` limit 1;
通过Recorder Header 的最后两个字节记录的下一行记录的偏移量就可以得到该页中所有的行记录,通过Page Header的PAGE_PREV和PAGE_NEXT就可以知道上个页和下个页的位置,这样InnoDB存储引擎就能读到整张表所有的行记录数据。
最后分析Page Directory。前面已经提到了从0X0000FFC4到0X0000FFF7是当前页的Page Directory,如下:

需要注意的是, Page Directory是逆序存放的,每个槽占2个字节,因此可以看到00 63 是最初行的相对位置,即0XC063, 0X0070就是最后一行记录的相对位置,即0XC070.我们发现这就是前面分析的Infimun和Supremum的伪行记录。Page Directory槽中的数据都是按照主键的顺序存放的,因此查询具体记录就需要通过部分进行。前面已经提到InnoDB存储引擎的槽是稀疏的,故还需通过Recorder Header 的n_owned进行进一步的判断,如InnoDB存储引擎需要找到主键a为5的记录,通过二叉查找Page Directory的槽,可以定位记录的相对的位置在0X00E5处,找到行记录的实际位置0XC0E5。

可以看到第一行的记录是4,不是我们要找的6,但是可以发现前面的5字节的Record Header为 04 00 28 00 22 。找到4 ~8位表示n_owned值得部分,该值为4,表示该记录有4个记录,因此还需要进一步查找,通过Recorder header 最后两个字节的偏移量0X0022找到下一条记录的位置 0XC107,这才是最终要找的主键为5的记录。
结语
MYSQL的优化原理分析
个人博客地址