SQL学习笔记
一、SQL简介
1.1 SQL是什么
SQL是结构化查询语言,它是一种用于存储,操作和检索存储在关系数据库中的数据的计算机语言
1.2 SQL命令
1)DDL——数据定义语言
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | CREATE | 用于在数据库中创建新表,表视图或其他对象 |
| 2 | ALTER | 用于修改现有数据库对象,例如:表 |
| 3 | DROP | 用于删除整个表,数据库中的表或其他对象的视图 |
2) DML——数据操纵语言
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | SELECT | 从一个或多个表中检索某些记录 |
| 2 | INSERT | 创建一条记录 |
| 3 | UPDATE | 用于修改(更新)记录 |
| 4 | DELETE | 删除记录 |
3)DCL——数据控制语言
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | GRANT | 为用户提供权限 |
| 2 | REVOKE | 撤销用户授予的权限 |
1.3 数据的完整性
-
实体完整性 - 表中没有重复的行。
-
域完整性 - 通过限制值的类型,格式或范围,为给定列强制执行有效条目。
-
参照完整性 - 其他记录使用(引用)导致这些行无法删除。
-
用户定义的完整性 - 实施一些不属于实体,域或参照完整性的特定业务规则
1.4 SQL约束
-
NOT NULL约束 - 确保列不能具有
NULL值。 -
默认值约束 - 在未指定列时为列提供默认值。
-
唯一约束 - 确保列中的所有值都不同。
-
主键 - 唯一标识数据库表中的每一行/记录。
-
外键 - 唯一标识任何其他数据库表中的行/记录。
-
检查约束 -
CHECK约束确保列中的所有值都满足特定条件。 -
索引 - 用于非常快速地从数据库创建和检索数据。
1.5 数据库范式
1) 第一范式(1NF)
-
定义所需要的数据项,因为它们成为在表中的列。放在一个表中的相关的数据项。
-
确保有数据没有重复的组。
-
确保有一个主键。
1.6 运算符
变量a的值是:10,变量b的值是:20
1) SQL算术运算符
| 操作符 | 描述 | 示例 |
|---|---|---|
| + | 加法,执行加法运算。 | a + b = 30 |
| - | 减法,执行减法运算。 | a + b = -10 |
| * | 除法,执行除法运算 | a * b = 200 |
| / | 用左操作数除右手操作数 | b / a = 2 |
| % | 用左手操作数除左手操作数并返回余数 | b % a = 0 |
1.7 在MySQL中创建表的示例
CREATE TABLE regions (
region_id INT (11) AUTO_INCREMENT PRIMARY KEY,
region_name VARCHAR (25) DEFAULT NULL
);
CREATE TABLE countries (
country_id CHAR (2) PRIMARY KEY,
country_name VARCHAR (40) DEFAULT NULL,
region_id INT (11) NOT NULL,
FOREIGN KEY (region_id) REFERENCES regions (region_id) ON DELETE CASCADE ON UPDATE CASCADE
);
CREATE TABLE locations (
location_id INT (11) AUTO_INCREMENT PRIMARY KEY,
street_address VARCHAR (40) DEFAULT NULL,
postal_code VARCHAR (12) DEFAULT NULL,
city VARCHAR (30) NOT NULL,
state_province VARCHAR (25) DEFAULT NULL,
country_id CHAR (2) NOT NULL,
FOREIGN KEY (country_id) REFERENCES countries (country_id) ON DELETE CASCADE ON UPDATE CASCADE
);
CREATE TABLE jobs (
job_id INT (11) AUTO_INCREMENT PRIMARY KEY,
job_title VARCHAR (35) NOT NULL,
min_salary DECIMAL (8, 2) DEFAULT NULL,
max_salary DECIMAL (8, 2) DEFAULT NULL
);
CREATE TABLE departments (
department_id INT (11) AUTO_INCREMENT PRIMARY KEY,
department_name VARCHAR (30) NOT NULL,
location_id INT (11) DEFAULT NULL,
FOREIGN KEY (location_id) REFERENCES locations (location_id) ON DELETE CASCADE ON UPDATE CASCADE
);
CREATE TABLE employees (
employee_id INT (11) AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR (20) DEFAULT NULL,
last_name VARCHAR (25) NOT NULL,
email VARCHAR (100) NOT NULL,
phone_number VARCHAR (20) DEFAULT NULL,
hire_date DATE NOT NULL,
job_id INT (11) NOT NULL,
salary DECIMAL (8, 2) NOT NULL,
manager_id INT (11) DEFAULT NULL,
department_id INT (11) DEFAULT NULL,
FOREIGN KEY (job_id) REFERENCES jobs (job_id) ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY (department_id) REFERENCES departments (department_id) ON DELETE CASCADE ON UPDATE CASCADE,
FOREIGN KEY (manager_id) REFERENCES employees (employee_id)
);
CREATE TABLE dependents (
dependent_id INT (11) AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR (50) NOT NULL,
last_name VARCHAR (50) NOT NULL,
relationship VARCHAR (25) NOT NULL,
employee_id INT (11) NOT NULL,
FOREIGN KEY (employee_id) REFERENCES employees (employee_id) ON DELETE CASCADE ON UPDATE CASCADE
);
二、SQL数据库操作
2.1 Create Database 语句
SQL CREATE DATABASE语句用于创建新的SQL数据库:
CREATE DATABASE database_name
/*示例*/
CREATE DATABASE testdb;
/*查看*/
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sqldemo |
| sys |
| testdb |
+--------------------+
6 rows in set
数据库名称(database_name)在RDBMS中必须是唯一的
2.2 Drop Database 语句
SQL DROP DATABASE语句用于删除SQL模式中已存在的数据库。
DROP DATABASE database_name;
/*示例*/
DROP DATABASE testdb;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sqldemo |
| sys |
+--------------------+
5 rows in set
2.3 Rename Database 语句
当需要更改数据库的名称时,将使用SQL RENAME DATABASE
RENAME DATABASE old_db_name TO new_db_name;
ALTER DATABASE old_name MODIFY NAME = new_name''
2.4 Use 语句
如果SQL模式中有多个数据库,那么在开始操作之前,需要选择一个将执行操作的数据库。
SQL USE语句用于选择SQL模式中的任何现有数据库。
USE database_name;
/*示例*/
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sqldemo |
| sys |
+--------------------+
7 rows in set
USE sqldemo;
三、表操作
3.1 Create Table
CREATE TABLE table_name(
column_name_1 data_type default value column_constraint,
column_name_2 data_type default value column_constraint,
...,
table_constraint
);
- 由
table_name指定的表名在数据库中必须是唯一的 - 每个列定义由列名,列的数据类型,默认值和一个或多个列约束组成
- 列的数据类型指定列可以存储的数据类型。 列的数据类型可以是数字,字符,日期等
- 列约束控制可以存储在列中的值的类型。 例如,
NOT NULL约束确保列不包含NULL值。列可能有多个列约束。 例如,users表的username列可以同时具有NOT NULL和UNIQUE约束。 - 如果约束包含多个列,则使用表约束。 例如,如果表的主键包含两列,则在这种情况下,必须使用
PRIMARY KEY表约束。
示例:
CREATE TABLE courses (
course_id INT AUTO_INCREMENT PRIMARY KEY,
course_name VARCHAR(50) NOT NULL
);
/*
courses表有两列:course_id和course_name;
course_id是课程表的主键列。 每个表都有一个且只有一个主键,用于唯一标识表中的每一行
course_id的数据类型是整数,由INT关键字表示。 此外,course_id列的值为AUTO_INCREMENT。表示当在courses表中插入新行而不提供course_id列的值时,数据库系统将为该列生成一个整数值
course_name存储课程名称。 其数据类型是最大长度为50的字符串(VARCHAR)。NOT NULL约束确保course_name列中不存储NULL值。
*/
3.2 Alter Table
使用SQL ALTER TABLE更改数据库中现有表的结构
ALTER TABLE语句用于对现有表执行以下操作:
- 使用
ADD子句添加新列。 - 使用
MODIFY子句修改列的属性,例如:约束,默认值等。 - 使用
DROP子句删除列。
1) SQL ALTER TABLE ADD列
该子句的作用是向表中添加一个或多个列
ALTER TABLE table_name
ADD new_colum data_type column_constraint [AFTER existing_column];
column_name data_type constraint;
/* 列定义的典型语法*/
/*示例*/
ALTER TABLE courses
ADD fee NUMERIC (10, 2) AFTER course_name,
ADD max_limit INT AFTER course_name;
2) SQL ALTERE TABLE MODIFY列
MODIFY字句用于更改现有列的某些属性
ALTER TABLE table_name
MODIFY column_definition
3) SQL ALTER TABLE DROP列
当表的列已过时且未被任何其他数据库对象(如触发器,视图,存储过程和存储过程)使用时,需要将其从表中删除
ALTER TABLE table_name
DROP column_name,
DROP colum_name,
...
/*example*/
ALTER TABLE courses
DROP COLUMN max_limit,
DROP COLUMN credit_hours;
3.3 DROP TABLE
使用SQL DROP TABLE语句删除数据库中的一个或多个表
DROP TABLE [IF EXISTS] table_name;
DROP TABLE table_name1,table_name2,...;
-
DROP TABLE语句永久删除表的数据和结构,某些数据库系统要求表中的记录必须为空时才能从数据库中删除。 这有助于防止意外删除仍在使用的表。 -
要删除表中的所有数据,可以使用DELETE或TRUNCATE TABLE语句。
-
要删除由另一个表的外键约束引用的表,必须在删除表之前禁用或删除外部约束
3.4 TURNCATE TABLE
使用SQL TRUNCATE TABLE语句高效,快速地删除表中的所有数据
TRUNCATE TABLE table_name; /*快速删除大表中的所有行*/
TRUNCATE TABLE table_name1, table_name2, ...;
3.5 RENAME TABLE
ALTER TABLE Students
RENAME TO Student_bank;
RENAME Students TO Student_bank;
3.6 SQL复制表&临时表
1)复制表
SELECT * INTO <destination_table> FROM <source_table>
2)临时表
临时表可以在运行时创建,并且可以像普通表一样执行各种操作
1.局部临时变量
/*局部临时变量表仅在当前连接时可用。 当用户与实例断开连接时,它会自动删除。 它以哈希(#)符号开头*/
CREATE TABLE #local temp table (
User_id int,
User_name varchar (50),
User_address varchar (150)
)
2.全局临时变量
/*全局临时表名称以双哈希(##)开头。 创建此表后,它就像一个永久表。 它始终为所有用户准备好,并且在撤消总连接之前不会被删除。*/
REATE TABLE ##new global temp table (
User_id int,
User_name varchar (50),
User_address varchar (150)
)
四、数据操作语句
4.1 INSERT语句
SQL提供了INSERT语句,用于将一行或多行插入表中。 INSERT语句用于:
- 向表中插入一行
- 向表中插入多行
- 将行从一个表复制到另一个表中
语法:
INSERT INTO table1 (column1, column2,...)
VALUES
(value1, value2,...);
INSERT INTO table1
VALUES
(value1, value2,...),
(value1, value2,...),
(value1, value2,...),
...;
从其他表复制行记录
INSERT INTO table1 (column1, column2)
SELECT
column1,
column2
FROM
table2
WHERE
condition1;
INSERT INTO语句还可以包含许多子句,如:SELECT,GROUP BY,HAVING以及JOIN和ALIAS。 因此,insert into select语句可能会有些复杂。
INSERT INTO store (store_name, sales, transaction_date)
SELECT store_name, sum (sales), transaction_date
FROM sales_information
GROUP BY store_name, transaction_date;
4.2 UPDATE语句
使用SQL UPDATE语句来修改表中现有行的数据
UPDATE table_name
SET column1 = value1,
column2 = value2
WHERE
condition;
在上面的语法中 -
- 首先,在
UPDATE子句中指明要更新的表。 - 其次,在
SET子句中指定要修改的列。SET子句中未列出的列的值不会被修改。 - 第三,指定
WHERE子句中要更新的行。
4.3 UPDATE & JOIN语句
UPDATE JOIN可使用一个表和连接条件来更新另一个表。
假设有一个客户表,更新包含来自其他系统的最新客户详细信息的客户表。比如要用最新数据来更新客户表。 在这种情况下,将使用客户ID上的连接在目标表和源表之间执行连接
/*语法*/
UPDATE customer_table
INNER JOIN
Customer_table
ON customer_table.rel_cust_name = customer_table.cust_id
SET customer_table.rel_cust_name = customer_table.cust_name
/*Example:*/
UPDATE table1 t1
LEFT JOIN table2 t2
ON t1.column1 = t2.column1
SET t1.column2 = t2.column2,
t1.column3 = t2.column3
where t1.column1 in(21,31);
4.4 更新日期数据
UPDATE table
SET Column_Name = 'YYYY-MM-DD HH:MM:SS'
WHERE Id = value
4.5 DELETE语句
使用SQL DELETE语句删除表中的一行或多行
DELETE
FROM
table_name
WHERE
condition;
-
首先,提供要删除行的表名称(
table_name)。 -
其次,在
WHERE子句中指定条件以标识需要删除的行记录。 如果省略WHERE子句,则将删除表中的所有行记录。 因此,应始终谨慎使用DELETE语句。
五、SQL查询语句
5.1 SELECT语句
除了SELECT和FROM子句之外,SELECT语句还可以包含许多其他子句,例如 -
- WHERE - 用于根据指定条件过滤数据
ORDER BY- 用于对结果集进行排序LIMIT- 用于限制返回的行JOIN- 用于查询来自多个相关表的数据GROUP BY- 用于根据一列或多列对数据进行分组HAVING- 用于过滤分组
/*查询表中所有的数据*/
SELECT
*
FROM
table_name
/*查询特定的列*/
SELECT
employee_id,
first_name,
last_name,
hire_date
FROM
employees;
/*执行简单的计算*/
SELECT
employee_id,
first_name,
last_name,
FLOOR(DATEDIFF(NOW(), hire_date) / 365) AS YoS
FROM
employees;
5.2 ORDER BY排序
SELECT
column1, column2
FROM
table_name
ORDER BY column1 ASC ,
column2 DESC;
/*优先对第一列的结果进行排序 */
在此语法中,ORDER BY子句放在FROM子句之后。 如果SELECT语句包含WHERE子句,则ORDER BY子句必须放在WHERE子句之后。
要对结果集进行排序,请指定要排序的列以及排序顺序的类型:
- 升序(使用:
ASC表示) - 降序(使用:
DESC表示)
5.3 DISTINCT运算符
使用SQL DISTINCT运算符从结果集中删除重复数据项
SELECT DISTINCT
column1,column2......
FROM
tables1;
通常,DISTINCT运算符将所有NULL值视为相同的值。 因此在结果集中,DISTINCT运算符只保留一个NULL值,并从结果集中删除其它的NULL值。
5.4 LIMIT子句
使用SQL LIMIT子句来限制SELECT语句返回的行数。
要检索查询返回的行的一部分,请使用LIMIT和OFFSET子句
SELECT
column_list
FROM
table1
ORDER BY column_list
LIMIT row_count OFFSET offset_count;
/*
row_count确定将返回的行数。OFFSET子句在开始返回行之前跳过偏移行。
OFFSET子句是可选的。 如果同时使用LIMIT和OFFSET子句,OFFSET会在LIMIT约束行数之前先跳过偏移行
*/
/*EXAMPLE*/
SELECT
employee_id, first_name, last_name
FROM
employees
ORDER BY first_name
LIMIT 5 OFFSET 3;
5.5 FETCH语句
OFFSET FETCH子句用于在开始返回任何行之前跳过结果集中的前N行。
OFFSET offset_rows { ROW | ROWS }
FETCH { FIRST | NEXT } [ fetch_rows ] { ROW | ROWS } ONLY
在上面语法中,
ROW和ROWS,FIRST和NEXT是同义词,因此,可以互换使用它们。offset_rows是一个整数,必须为零或正数。 如果offset_rows大于结果集中的行数,则不会返回任何行。fetch_rows也是一个整数,用于确定要返回的行数。fetch_rows的值等于或大于1。
/*Example*/
SELECT
employee_id,
first_name,
last_name,
salary
FROM employees
ORDER BY
salary DESC
OFFSET 5 ROWS
FETCH NEXT 5 ROWS ONLY;
5.6 BETWEEN | IN | LIKE | NULL
expression BETWEEN low AND high;
expression NOT BETWEEN low AND high
在上面语法中,
- 表达式是在低和高定义的范围内测试的表达式。
low和high可以是表达式或文字值,要求low的值小于high的值。
expression IN (value1,value2,...)
expression NOT IN (value1, value2,...)
/*示例*/
SELECT
employee_id, first_name, last_name, salary
FROM
employees
WHERE
department_id IN (SELECT
department_id
FROM
departments
WHERE
department_name = '市场营销'
OR department_name = 'IT')
使用SQL LIKE运算符来测试表达式是否与模式匹配
expression LIKE pattern
/*示例一*/
SELECT
employee_id,
first_name,
last_name
FROM
employees
WHERE
first_name LIKE 'Sh%';
/*示例二*/
SELECT
employee_id,
first_name,
last_name
FROM
employees
WHERE
first_name LIKE 'Jo__';
/*示例三*/
SELECT
employee_id, first_name, last_name
FROM
employees
WHERE
first_name LIKE 'M%'
AND first_name NOT LIKE 'Ma%'
ORDER BY
first_name;
要构造模式,请使用两个SQL通配符:
%百分号匹配零个,一个或多个字符。_下划线符号匹配单个字符。
expression IS NULL;
expression IS NOT NULL;
/*示例*/
SELECT
employee_id,
first_name,
last_name,
phone_number
FROM
employees
WHERE
phone_number IS NOT NULL;
- 不能使用比较运算符的等于(
=)将值与NULL值进行比较 NULL值是特殊的,因为任何与NULL值的比较都不会导致true或false,但在第三个逻辑结果中:未知
5.7 SQL别名
SQL别名,包括表和列别名,使查询更短,更易理解
1) 列别名
SELECT
inv_no AS invoice_no,
amount,
due_date AS '截止日期',
cust_no '客户编号'
FROM
invoices;
-
invoice_no是inv_no列的别名 -
'Due date'是due_date列的列别名。 因为别名包含空格,所以必须使用单引号(')或双引号(")来包围别名。 -
'Customer no'是cust_no列的别名。注意这里没有使用AS关键字。AS关键字是可选的,因此可以省略它。
2) 表别名
SELECT
d.department_name
FROM
departments AS d
/*示例一*/
SELECT
employee_id,
first_name,
last_name,
e.department_id,
department_name
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
ORDER BY
first_name;
/*示例二*/
SELECT
e.first_name AS employee,
m.first_name AS manager
FROM
employees e
LEFT JOIN employees m ON m.employee_id = e.manager_id
ORDER BY
manager;
5.8 JOIN操作
1) INNER JOIN
内连接子句消除了与另一个表的行不匹配的行。
SELECT
A.n
FROM A
INNER JOIN B ON B.n = A.n
/*INNER JOIN子句可以连接三个或更多表,只要它们具有关系,通常是外键关系*/
SELECT
A.n
FROM A
INNER JOIN B ON B.n = A.n
INNER JOIN C ON C.n = A.n;
/*示例*/
SELECT
first_name, last_name, job_title, department_name
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
INNER JOIN jobs j ON j.job_id = e.job_id
WHERE
e.department_id IN (1, 2, 3);
2) LEFT JOIN
左连接将返回左表中的所有行,而不管右表中是否存在匹配的行
SELECT
A.n
FROM
A
LEFT JOIN B ON B.n = A.n;
/*示例*/
SELECT
c.country_name, c.country_id, l.country_id, l.street_address, l.city
FROM
countries c
LEFT JOIN locations l ON l.country_id = c.country_id
WHERE
c.country_id IN ('US', 'UK', 'CN')
3) FULL OUTER JOIN
理论上,完全外连接是左连接和右连接的组合。 完整外连接包括连接表中的所有行,无论另一个表是否具有匹配的行。
如果连接表中的行不匹配,则完整外连接的结果集包含缺少匹配行的表的每列使用NULL值。 对于匹配的行,结果集中包含从连接表填充列的行
SELECT column_list
FROM A
FULL OUTER JOIN B ON B.n = A.n;
4) CROSS JOIN
交叉连接是一种连接操作,它生成两个或多个表的笛卡尔积
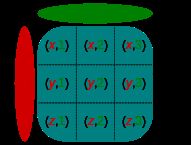
SELECT column_list
FROM A
CROSS JOIN B;
/*在SQL中,两个表A和B的笛卡尔乘积是结果集,其中第一个表(A)中的每一行与第二个表(B)中的每一行配对。 假设A表有n行,而B表有m行,那么A和B表的交叉连接结果有n x m行*/
5) 自连接
/*示例一*/
SELECT
CONCAT(e.first_name, ' ', e.last_name) as employee,
CONCAT(m.first_name, ' ', m.last_name) as manager
FROM
employees e
INNER JOIN
employees m ON m.employee_id = e.manager_id
ORDER BY manager;
/*示例二*/
SELECT
CONCAT(e.first_name, ' ', e.last_name) as employee,
CONCAT(m.first_name, ' ', m.last_name) as manager
FROM
employees e
LEFT JOIN
employees m ON m.employee_id = e.manager_id
ORDER BY manager;
六、聚合函数
- SQL聚合函数计算一组值并返回单个值
- 因为聚合函数对一组值进行操作,所以它通常与
SELECT语句的GROUP BY子句一起使用。GROUP BY子句将结果集划分为值分组,聚合函数为每个分组返回单个值
以下是常用的SQL聚合函数:
- AVG() - 返回集合的平均值。
- COUNT() - 返回集合中的项目数。
- MAX() - 返回集合中的最大值。
- MIN() - 返回集合中的最小值
- SUM() - 返回集合中所有或不同值的总和。
6.1 AVG (平均)
AVG([ALL|DISTINCT] expression)
- 如果使用
ALL关键字,AVG函数将获取计算中的所有值 - 如果明确指定
DISTINCT关键字,AVG函数将仅在计算中采用唯一值。
/*示例1*/
SELECT
AVG(salary)
FROM
employees;
SELECT
ROUND(AVG(DISTINCT salary), 2)
FROM
employees;
/*示例2 : 与分组一起使用*/
SELECT
department_id,
AVG(salary)
FROM
employees
GROUP BY
department_id;
/*示例3:与JOIN一起使用*/
SELECT
e.department_id,
department_name,
AVG(salary)
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
GROUP BY
e.department_id;
/*示例4 : 与HAVING一起使用*/
SELECT
e.department_id,
department_name,
AVG(salary) AS avgsalary
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
GROUP BY
e.department_id
HAVING avgsalary<5000
ORDER BY
AVG(salary) DESC;
/*示例5: 子查询*/
SELECT
AVG(employee_sal_avg)
FROM
(
SELECT
AVG(salary) employee_sal_avg
FROM
employees
GROUP BY
department_id
) t;
6.2 COUNT(统计)
COUNTC ([ALL | DISTINCT] expression);
/*COUNT(*)函数返回表中的行数,包括包含NULL值的行。*/
/*示例1 : 与GROUP BY一起使用*/
SELECT
e.department_id,
department_name,
COUNT(*)
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
GROUP BY
e.department_id;
/*示例2 :与HAVING一起使用 */
/*要按COUNT(*)函数的结果过滤分组,需要在COUNT(*)函数使用HAVING子句*/
SELECT
e.department_id,
department_name,
COUNT(*)
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
GROUP BY
e.department_id
HAVING
COUNT(*) > 5
ORDER BY
COUNT(*) DESC;
6.3 SUM(求和)
SUM([ALL|DISTINCT] expression)
- 只能将
SUM函数应用于数字列 SUM函数忽略NULL值。
/*示例1 :与HAVING 以及 GROUP BY一起使用*/
SELECT
e.department_id,
department_name,
SUM(salary)
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
GROUP BY
e.department_id
HAVING
SUM(salary) > 30000
ORDER BY
SUM(salary) DESC;
6.4 MAX & MIN
MAX(expression)
MIN(expression)
/*示例1 : 用于子查询中*/
SELECT
employee_id,
first_name,
last_name,
salary
FROM
employees
WHERE
salary = (
SELECT
MAX(salary)
FROM
employees
);
/*示例2 : 用于ORDER BY 以及 排序中*/
SELECT
d.department_id,
department_name,
MAX(salary)
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
GROUP BY
e.department_id
ORDER BY
MAX(salary) DESC;
/*示例3 : 与HAVING一起使用*/
SELECT
d.department_id,
department_name,
MAX(salary)
FROM
employees e
INNER JOIN departments d ON d.department_id = e.department_id
GROUP BY
e.department_id
HAVING
MAX(salary) > 12000;
6.5 HAVING
SQL HAVING子句,该子句用于为GROUP BY子句汇总的组指定条件
HAVING子句通常与SELECT语句中的GROUP BY子句一起使用。 如果使用带GROUP BY子句的HAVING子句,HAVING子句的行为类似于WHERE子句
SELECT
column1,
column2,
AGGREGATE_FUNCTION (column3)
FROM
table1
GROUP BY
column1,
column2
HAVING
group_condition;
注:需要注意的是,在GROUP BY子句之前应用WHERE子句之后应用HAVING子句
七、高级查询
7.1 GROUPING SETS运算符
使用SQL GROUPING SETS运算符生成多个分组集
分组集是一组使用GROUP BY子句进行分组的列。 通常,单个聚合查询定义单个分组集
SELECT
c1,
c2,
aggregate (c3)
FROM
table
GROUP BY
GROUPING SETS (
(c1, c2),
(c1),
(c2),
()
);
7.2 ROLLUP运算符
ROLLUP是GROUP BY子句的扩展。 ROLLUP选项允许包含表示小计的额外行,通常称为超级聚合行,以及总计行。
SELECT
c1, c2, aggregate_function(c3)
FROM
table
GROUP BY ROLLUP (c1, c2);
ROLLUP假定输入列之间存在层次结构。 例如,如果输入列是(c1,c2),则层次结构c1> c2。ROLLUP生成考虑此层次结构有意义的所有分组集。 这就是为什么我们经常使用ROLLUP来生成小计和总计以用于报告目的
/*示例1*/
SELECT
COALESCE(warehouse, 'All warehouses') AS warehouse,
SUM(quantity)
FROM
inventory
GROUP BY ROLLUP (warehouse);
/*示例2*/
SELECT
warehouse, product, SUM(quantity)
FROM
inventory
GROUP BY warehouse, ROLLUP (product);
7.3 UNION运算符 (并集)
使用SQL UNION组合来自多个查询的两个或多个结果集
UNION运算符简介
UNION运算符将两个或多个SELECT语句的结果集合并到一个结果集中
SELECT
column1, column2
FROM
table1
UNION [ALL]
SELECT
column3, column4
FROM
table2;
A UNION B:

A UNION ALL B:
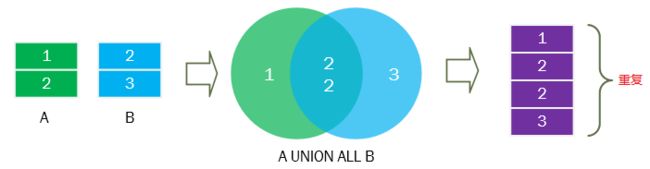
7.4 INTERSECT(交)
SELECT
id
FROM
a
INTERSECT
SELECT
id
FROM
b;
要使用INTERSECT运算符,SELECT语句的列需要遵循以下规则:
- 列的数据类型必须兼容。
SELECT语句中的列数及其顺序必须相同。

7.5 MINUS(差)
SELECT
id
FROM
A
MINUS
SELECT
id
FROM
B;
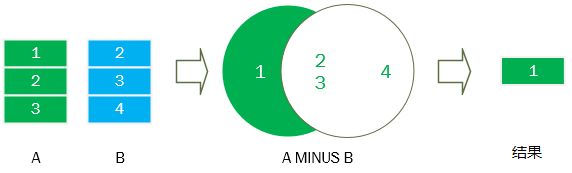
/*示例*/
SELECT
employee_id
FROM
employees
MINUS
SELECT
employee_id
FROM
dependents
ORDER BY employee_id;
7.6 子查询
/*示例1:*/
SELECT
employee_id, first_name, last_name
FROM
employees
WHERE
department_id NOT IN (SELECT
department_id
FROM
departments
WHERE
location_id = 1700)
ORDER BY first_name , last_name;
/*示例2:*/
SELECT
employee_id, first_name, last_name, salary
FROM
employees
WHERE
salary = (SELECT
MAX(salary)
FROM
employees)
ORDER BY first_name , last_name;
/*示例3:*/
SELECT
employee_id, first_name, last_name, salary
FROM
employees
WHERE
salary > (SELECT
AVG(salary)
FROM
employees);
EXISTS运算符检查子查询返回的行是否存在。 如果子查询包含任何行,则返回true。 否则,它返回false。
EXISTS (subquery )
/*示例*/
SELECT
department_name
FROM
departments d
WHERE
NOT EXISTS( SELECT
1
FROM
employees e
WHERE
salary > 10000
AND e.department_id = d.department_id)
ORDER BY department_name;
7.7 EXISTS运算符
EXISTS运算符用于指定子查询以测试行的存在。 以下是EXISTS运算符的语法
EXISTS (subquery)
NOT EXISTS (subquery)
7.8 ALL & SOME运算符
WHERE column_name comparison_operator ALL (subquery)
/*示例*/
SELECT
first_name, last_name, salary
FROM
employees
WHERE
salary > ALL (SELECT
salary
FROM
employees
WHERE
department_id = 2)
ORDER BY salary;
WHERE column_name comparison_operator ANY (subquery)
/*示例*/
SELECT
first_name,
last_name,
salary
FROM
employees
WHERE
salary = ANY (
SELECT
AVG(salary)
FROM
employees
GROUP BY
department_id)
ORDER BY
first_name,
last_name,
salary;
SQL ALL运算符必须以比较运算符开头,例如:>,>=,<,<=,<>,=,后跟子查询
八、约束
8.1 SQL主键约束
每个表都有一个且只有一个主键。 主键不接受NULL或重复值。如果主键由两列或更多列组成,则值可能在一列中重复,但主键中所有列的值组合必须是唯一的。
/*示例1 : 主键由一列组成 */
CREATE TABLE projects (
project_id INT PRIMARY KEY,
project_name VARCHAR(255),
start_date DATE NOT NULL,
end_date DATE NOT NULL
);
/*示例2 : 主键由多列组成*/
CREATE TABLE project_assignments (
project_id INT,
employee_id INT,
join_date DATE NOT NULL,
CONSTRAINT pk_assgn PRIMARY KEY (project_id , employee_id)
);
使用ALTER TABLE语句添加主键
CREATE TABLE project_milestones(
milestone_id INT,
project_id INT,
milestone_name VARCHAR(100)
);
ALTER TABLE project_milestones
ADD CONSTRAINT pk_milestone_id PRIMARY KEY (milestone_id);
或
ALTER TABLE project_milestones
ADD PRIMARY KEY (milestone_id);
8.2 外键
CREATE TABLE project_milestones (
milestone_id INT AUTO_INCREMENT PRIMARY KEY,
project_id INT,
milestone_name VARCHAR(100),
FOREIGN KEY (project_id)
REFERENCES projects (project_id)
);
/*可以为FOREIGN KEY约束指定名称*/
CREATE TABLE project_milestones (
milestone_id INT AUTO_INCREMENT PRIMARY KEY,
project_id INT,
milestone_name VARCHAR(100),
CONSTRAINT fk_project FOREIGN KEY (project_id)
REFERENCES projects (project_id)
);
/*hk_project是FOREIGN KEY约束的名称。*/
/*使用ALTER来向现有表中添加FOREIGN KEY约束*/
ALTER TABLE table_1
ADD CONSTRAINT fk_name FOREIGN KEY (fk_key_column)
REFERENCES table_2(pk_key_column)
/*删除外键约束*/
ALTER TABLE table_name
DROP CONSTRAINT fk_name;
8.3 唯一约束
使用SQL UNIQUE约束强制列或一组列中值的唯一性
UNIQUE约束定义了一个规则,该规则可防止存储在不参与主键的特定列中有重复值
| 比较项 | PRIMARY KEY约束 | UNIQUE约束 |
|---|---|---|
| 约束的数量 | 一个 | 多个 |
| NULL值 | 不允许 | 允许 |
/*示例1*/
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL UNIQUE,
password VARCHAR(255) NOT NULL
);
/*示例2: 表约束*/
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
password VARCHAR(255) NOT NULL,
CONSTRAINT uc_username UNIQUE (username)
);
/*示例3: 将UNIQUE约束添加到现有表*/
ALTER TABLE users
ADD CONSTRAINT uc_username UNIQUE(username);
ALTER TABLE users
ADD new_column data_type UNIQUE;
/*示例4: 删除UNIQUE约束*/
ALTER TABLE table_name
DROP CONSTRAINT unique_constraint_name;
ALTER TABLE users
DROP CONSTRAINT uc_username;
8.5 NOT NULL
NOT NULL约束是一个列约束,它定义将列限制为仅具有非NULL值的规则。
CREATE TABLE table_name(
...
column_name data_type NOT NULL,
...
);
/*等同于*/
CREATE TABLE table_name (
...
column_name data_type,
...
CHECK (column_name IS NOT NULL)
);
/*示例*/
CREATE TABLE training (
employee_id INT,
course_id INT,
taken_date DATE NOT NULL,
PRIMARY KEY (employee_id , course_id)
);
ALTER TABLE NOT NULL语句
UPDATE training
SET taken_date = CURRENT_DATE ()
WHERE
taken_date IS NULL;
ALTER TABLE training
MODIFY taken_date date NOT NULL;
8.6 检查约束
CHECK约束是SQL中的完整性约束,它允许指定列或列集中的值必须满足布尔表达式
/*示例1:单个列*/
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(255) NOT NULL,
selling_price NUMERIC(10,2) CHECK (selling_price > 0)
);
/*示例2 : 单个列,指定名字*/
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(255) NOT NULL,
selling_price NUMERIC(10,2) CONSTRAINT positive_selling_price CHECK (selling_price > 0)
);
/*示例3: 涉及多个列 (表约束)*/
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR (255) NOT NULL,
selling_price NUMERIC (10, 2) CHECK (selling_price > 0),
cost NUMERIC (10, 2) CHECK (cost > 0),
CHECK (selling_price > cost)
);
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR (255) NOT NULL,
selling_price NUMERIC (10, 2) CHECK (selling_price > 0),
cost NUMERIC (10, 2) CHECK (cost > 0),
CONSTRAINT valid_selling_price CHECK (selling_price > cost)
);