面向机器智能的TensorFlow实战6:循环神经网络与自然语言处理
本章将探讨序列模型(sequential model),可对序列输入进行分类或标记,生成文本序列或将一个序列转换为另一个序列。RNN提供了一些构件,可以很好地切入全连接层和卷积层的工具集。
1、RNN简介
许多真实问题本质上都是序列化的。2006年提出的一种LSTM。RNN能够很好地完成许多领域的序列任务,如语音识别、语音合成、手写连体字识别、时间序列预测、图像标题生成以及端到端的机器翻译等。
近似任意程序:之前的前馈神经网络只能在固定长度的向量上工作。相比之下,无论输入还是输出为可变长向量,或输入输出均为可变长向量,RNN都可以应对。
RNN基本上是一个由神经元和连接权值构成的任意有向图。输入神经元的活性值是由输入数据设置的。输出神经元也只是数据流图中的一组可从中读取预测结果的神经元。其他神经元都被称为隐含神经元。RNN的当前隐含活性值被称为状态。在每个序列的最开始,通常会设置一个值为0的空状态。
RNN的状态依赖于当前输入和上一个状态,而后者又依赖于更上一步的输入和状态。因此,状态与序列之前提供的所有输入都间接相关,从而可理解为工作记忆。
带有sigmoid函数的RNN已由Sch和Z于2006年证明是图灵完备的。这意味着,当给正确的权值时,RNN可完成与任意计算程序相同的计算。然而这只是一个理论性质,因为当给定一项任务时,不存在找到完美权值的方法。尽管如此,利用梯度下降法仍然能够得到相当好的结果。
随时间反向传播:如何在RNN这种动态系统中将误差反向传播并非那么显而易见。优化RNN可采取这样一种技巧,即沿时间轴将其展开,之后就可使用与优化前馈网络相同的方式对RNN进行优化。这样,为计算误差相对于各权值的梯度,便可对这个展开的RNN网络运用标准的反向传播算法。这种算法被称为随时间反向传播(Back-Propagation Through Time, BPTT)。该算法将返回与时间相关的误差对每个权值(也包括那些联结相邻副本的权值)的偏导。为保持联结权值相同,可采用普通的联结权值处理方法,即将它们的梯度相加。请注意,这种方式与卷积神经网络中处理卷积滤波器的方式等价。
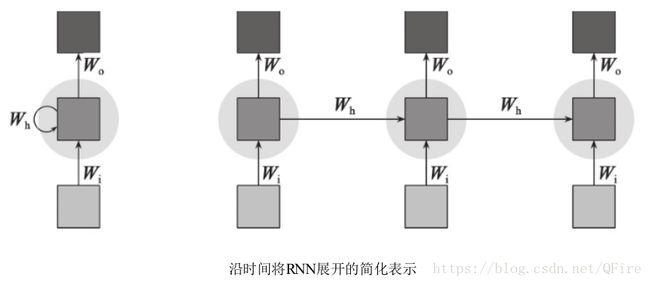
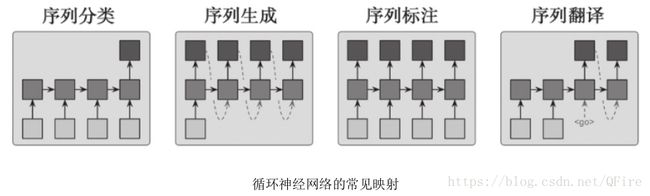
序列的编码与解码: 常见的映射
实现第一个RNN:TensorFlow支持RNN的各种变体,可从tf.nn.rnn_cell模块中找到这些变体的实现。借助tensorflow.models.rnn中的tf.nn.dynamic_rnn()运算,TensorFlow还为我们实现了RNN动力学。关于参数,dynamic_rnn()接收一个循环网络的定义以及若干输入序列构成的批数据。就目前而言,所有的序列都是等长的。该函数会向数据流图创建RNN所需的计算,并返回保存了每个时间步的输出和隐含状态的两个张量。
import tensorflow as tf
from tensorflow.models.rnn import rnn_cell
from tensorflow.models.rnn import rnn
# 输入数据的维数为batch_size*sequence_length*frame_size
# 不希望限制批次的大小,将第1维的尺寸设为None
sequence_length = ...
frame_size = ...
data = tf.placeholder(tf.float32, [None, sequence_length, frame_size])
num_neurons = 200
network = rnn_cell.BasicRNNCell(num_neurons)
# 为sequence_length步定义模拟RNN的运算
outputs, states = rnn.dynamic_rnn(network, data, dtype=tf.float32)梯度消失与梯度爆炸: 上面的模型无法扑捉输入帧间的长时依赖关系,而这种关系正是NLP任务所需要的。如判别给定输入序列是否为给定语法的一部分。为完成该任务,网络必须记住其中含有许多后续不相关的帧的序列的第一帧。RNN之所以难于学习这种长时依赖关系,原因在于优化期间误差在网络中的传播方式。为了计算梯度,要将误差在展开后的RNN中传播。对于长序列而言,这种展开的网络的深度将会非常大,层数非常多,在每一层中,反向传播算法都会将来自网络上一层的误差乘以局部偏导。如果大多数局部偏导都远小于1,则梯度每经过一层都会变小,且呈指数级衰减,从而最终消失。类似地,如果许多偏导都大于1,则会使梯度值急剧增大。
实际上,在任何深度网络中,该问题都是存在的,而非只有循环神经网络中才有这样的问题。在RNN中,相邻时间步是联结在一起的,因此,这样的权值的局部偏导要么都小于1,要么都大于1,原始RNN中每个权值都会向着相同的方向被缩放。因此,相比于前馈神经网络,梯度消失或梯度爆炸这个问题在RNN中更为突出。
当梯度的各分量接近于0或无穷大时,训练分别会出现停滞或发散。此外,由于我们做的是数值优化,因此,浮点精度也会对梯度值产生影响。该问题也被称为深度学习中的基本问题。在近年来已受到许多研究者的关注。目前最流行的解决方案是一种称为长短时记忆网络(long-short term memory, LSTM)的RNN架构。
长短时记忆网络:LSTM是一种特殊形式的RNN,由Hochreiter和Schmidhuber于1997年提出,它是专为解决梯度消失和梯度爆炸问题而设计的。在学习长时依赖关系时它有着卓越的表现,并成为RNN事实上的标准。自从该模型被提出后,相继提出了LSTM的若干变种,这些变种的实现已包含在TensorFlow中。
为解决梯度消失和梯度爆炸问题,LSTM架构将RNN中的普通神经元替换为其内部拥有少量记忆的LSTM单元(LSTM Cell)。如同普通RNN,这些单元也被联结在一起,但它们还拥有有助于记忆许多时间步中的误差的内部状态。LSTM的窍门在于这种内部状态拥有一个固定权值为1的自连接,以及一个线性激活函数,因此其局部偏导始终为1 。在反向传播阶段,这个所谓的常量误差传输子能够在许多时间步中携带误差而不会发生梯度消失或梯度爆炸。
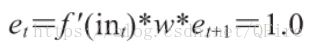
尽管内部状态的目的是随许多时间步传递误差,LSTM架构中负责学习的实际上是环绕门,这些门都拥有一个非线性的激活函数。在原始的LSTM单元中,有两种门:一种负责学习如何对到来的活性值进行缩放,而另一种负责学习如何对输出的活性值进行缩放。因此,这种单元可学习何时包含或忽略新的输入,以及何时将它表示的特征传递给其他单元。一个单元的输入会送入使用不同权值的所有门中。
RNN结构的变种:LSTM的一种比较流行的变种是添加一个对内部循环连接进行比例缩放的遗忘门,以允许网络学会遗忘。这样,内部循环连接的局部偏导就变成了遗忘门的活性值,从而可取为非1的值。当记忆单元上下文非常重要时,这种网络也可以学会将遗忘门保持关闭状态。将遗忘门的初始值设为1是非常重要的,因为这样可使LSTM单元从一个记忆状态开始工作。如今,在几乎所有的实现中,遗忘门都是默认存在的。在TensorFlow中,可通过指定LSTM层的forget_bias参数对遗忘门的偏置进行初始化,默认初值为1,也建议不要修改这个默认值。
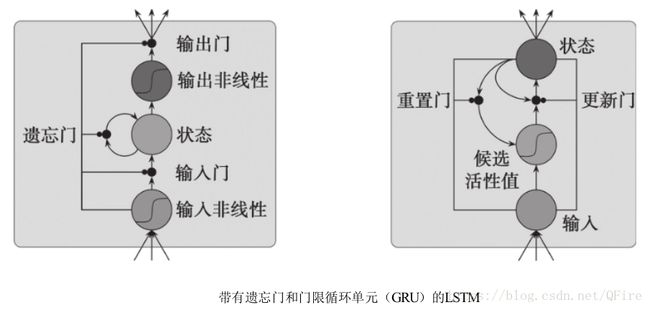 另一种扩展是添加窥视孔连接,以使一些门能够看到单元的状态。提出该变种的作者声称当任务中涉及精确的时间选择和间隔时,使用窥视孔连接是有益的。TensorFlow的LSTM层支持窥视孔连接,可通过为LSTM层传入use_peepholes=True标记将窥视孔连接激活。
另一种扩展是添加窥视孔连接,以使一些门能够看到单元的状态。提出该变种的作者声称当任务中涉及精确的时间选择和间隔时,使用窥视孔连接是有益的。TensorFlow的LSTM层支持窥视孔连接,可通过为LSTM层传入use_peepholes=True标记将窥视孔连接激活。
基于LSTM的基本思想,Chung Junyoung等于2014年提出了门限循环单元(Gated Recurrent Unit, GRU)。与LSTM相比,GRU的架构更简单,而且只需更少的计算量就可得到与LSTM非常相近的结果。GRU没有输出门,它将输入和遗忘门整合为一个单独的更新门(update gate)。更新门决定了内部状态与候选活性值的融合比例。候选活性值是依据由重置门(reset gate)和新的输入确定的部分隐含状态计算得到的。Tensorflow的GRU层对应GRUCell类,除了该层中的单元数目,它不含任何其他参数。如果参数进一步了解GRU,参考文献:
Jozefowicz, Rafal, Wojciech Zaremba, and Ilya Sutskever. “ An empirical exploration of recurrent network architectures.” Proceedings of the 32nd International Conference on Machine Learning (ICML-15). 2015.

由于信息只能在两层之间向上流动,与规模较大的全连接RNN相比,多层RNN拥有的权值数目更少,而且有助于学习到更多的抽象特征。
PTB数据:http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz,本文只关心data文件夹,有三个数据文件并经过了预处理,包含了10000个不同的词语和语句结束标记符以及标记稀有词语的特殊符号
TensorFlow提供了两个函数来帮助实现数据的预处理。ptb_raw_data函数读取PTB的原始数据,并将原始数据中的单词转化为单词ID,训练数据中总共包含了929589个单词,而这些单词被组成了一个非常长的序列。这个序列通过特殊的标识符给出了每句话结束的位置。在这个数据集中,句子结束的标识符ID为2.
时间序列预测:预测正弦函数。