date: 2018-2-22 22:12:29
title: go| 感受并发编程的乐趣 后篇
这篇 blog 紧接我的上篇 blog - go| 感受并发编程的乐趣 前篇.
学习了 ccmouse - googl工程师 在 慕课网 - 搭建并行处理管道,感受GO语言魅力, 获益匪浅, 也想把这份编程的快乐传递给大家.
强烈推荐一下ccmouse大大的课程, 总能让我生出 Google工程师果然就是不一样 之感, 每次都能从简单的 hello world 开始, 一步步 coding 到教程的主题, 并在过程中给予充分的理由 -- 为什么要一步步变复杂. 同时也会亲身 踩坑 示范, 干货满满.
内容提要:
- go 实现完整外部排序
- go 实现集群版(web版)外部排序
另外, ccmouse大大关于语言学习的方法也值得借鉴:
- 首先, 学习一下语言语法的要点
- 立刻找一个不那么简单的项目来做, 边做边查文档/stackoverflow
go 实现完整外部排序
先来看看完整外部排序的设计图:
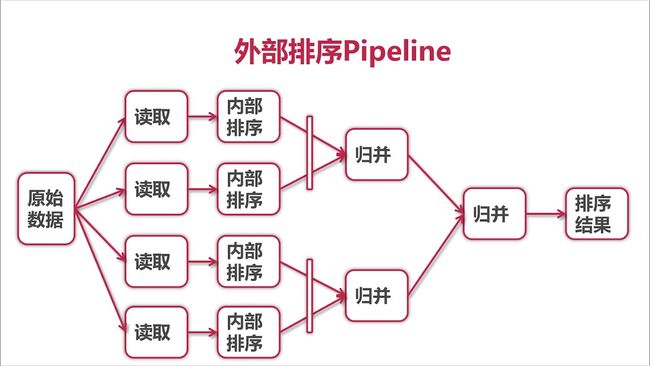
图解: 外部排序
涉及到的功能大部分在上一章都有讲到, 整体流程:
- 从文件中读取数据: 注意这里使用了 chunk 的设计, 将文件进行分块读取, 而且 chunkSize 的设计很巧妙, 同时支持 全文读取 和 chunk读取
- 对读取到的 chunk 的数据进行内存排序(快排)
- 通过递归, 对排序后的 chunk 进行二路归并
- 将归并后的数据写入到文件中
从协程的角度来看待整个流程:
- goroutine1 进行 chunk读取, 写入 channel
- goroutine2 进行 内存排序, 排序后数据写入 channel
- goroutine3 进行 二路归并, 归并的过程中, 数据不断写入到 channel
- goroutine4 进行 文件写入, 将 channel 中的数据写入到文件
注意这里:
- goroutine1-4 可能是多个协程, 可能某一时刻是同一个协程, go 底层会有任务队列(runq)进行协程调度
- 可以通过数据流的角度来思考这个问题: 数据是怎么在 文件/channel/协程 之间进行流转的.
- 测试很重要, 示例中就先使用了small 数据进行测试, 检查程序的正确性, 再调整到 large 数据
- 日志很重要, 可以帮助我们获取到程序的更多信息, 比如 debug/性能调优
关于性能:
- 并行 最终受限于 cpu 核数, 即 N 核cpu最多同时运行 N 个线程
- 协程间的抢占会带来性能损耗, 同理还有 进程/线程 的调度
- 协程+channel的机制方便并发编程扩展, 相对于单机内存操作自然性能要低一些
package main
import (
"io"
"encoding/binary"
"os"
"bufio"
"sort"
"fmt"
"time"
)
var startTime time.Time
func main() {
fileIn := "small.in"
fileOut := "small.out"
p := createPipeline(fileIn, 512, 4) // 按照cpu核数设置节点数, 减少协程间抢占带来性能损耗
writeToFile(p, fileOut)
printFile(fileOut, -1)
startTime = time.Now() // 添加日志
fileIn = "large.in"
fileOut = "large.out"
p = createPipeline(fileIn, 800000000, 4)
writeToFile(p, fileOut)
printFile(fileOut, 100)
}
func createPipeline(filename string, fileSize, chunkCount int) <-chan int {
chunkSize := fileSize / chunkCount // fileSize/8/chunkCount = int/chunk, 这里简单处理, 设置为可以整除的参数
sortResults := []<-chan int{} // 传递给 mergeN() 的已排序切片
for i := 0; i < chunkCount; i++ {
file, err := os.Open(filename) // 为什么没有用 defer file.close() ? 因为需要在函数外去关闭掉, 比较麻烦, 这里暂时省略
if err != nil {
panic(err)
}
file.Seek(int64(i*chunkSize), 0) // 定位到每个 chunk 的起始位置
s := readerChunk(bufio.NewReader(file), chunkSize)
sortResults = append(sortResults, memSort(s))
}
return mergeN(sortResults...)
}
func writeToFile(ch <-chan int, filename string) {
file, err := os.Create(filename)
if err != nil {
panic(err)
}
defer file.Close()
writer := bufio.NewWriter(file)
defer writer.Flush() // defer 是 LIFO
for v := range ch {
buffer := make([]byte, 8)
binary.BigEndian.PutUint64(buffer, uint64(v))
writer.Write(buffer)
}
}
func printFile(filename string, count int) {
file, err := os.Open(filename)
if err != nil {
panic(err)
}
defer file.Close()
p := readerChunk(file, -1) // -1 的作用体现出来了, 这里就可以读取全部文件
if count == -1 {
for v := range p {
fmt.Println(v)
}
} else {
n := 0
for v := range p {
fmt.Println(v)
n++
if n >= count {
break
}
}
}
}
// 递归解决两两归并
func mergeN(ins ...<-chan int) <-chan int {
if len(ins) == 1 {
return ins[0]
}
m := len(ins) / 2
// ins[0..m) + ins[m..end)
return merge(mergeN(ins[:m]...),
mergeN(ins[m:]...))
}
func merge(in1, in2 <-chan int) <-chan int {
out := make(chan int, 1024) // 性能优化, 给 channel 添加 buffer, 而不是收一个就发一个
go func() {
// 归并的过程要处理某个通道可能没有数据的情况, 代码非常值得一读
v1, ok1 := <-in1
v2, ok2 := <-in2
for ok1 || ok2 {
if !ok2 || (ok1 && v1 <= v2) {
out <- v1
v1, ok1 = <-in1
} else {
out <- v2
v2, ok2 = <-in2
}
}
close(out)
fmt.Println("merge done: ", time.Now().Sub(startTime))
}()
return out
}
// 添加 chunk 来读取文件,
func readerChunk(reader io.Reader, chunkSize int) <-chan int {
out := make(chan int, 1024) // 性能优化, 给 channel 添加 buffer, 而不是收一个就发一个
bytesRead := 0
go func() {
buffer := make([]byte, 8) // int: 64bit -> 8byte
for {
n, err := reader.Read(buffer)
bytesRead += n
if n > 0 { // 可能数据不足 8byte
v := int(binary.BigEndian.Uint64(buffer))
out <- v
}
// 使用 -1 表示不添加 chunk 大小限制
// 使用是 >=, 读取区间是 [0, chunkSize)
if err != nil || (chunkSize != -1 && bytesRead >= chunkSize) {
break
}
}
close(out)
}()
return out
}
func memSort(in <-chan int) <-chan int {
out := make(chan int, 1024) // 性能优化, 给 channel 添加 buffer, 而不是收一个就发一个
go func() {
// read into memory
a := []int{}
for v := range in {
a = append(a, v)
}
fmt.Println("read into memory: ", time.Now().Sub(startTime))
// sort
sort.Ints(a)
fmt.Println("sort done: ", time.Now().Sub(startTime))
// output
for _, v := range a {
out <- v
}
close(out)
}()
return out
}
go 实现集群版(web版)外部排序
网络版的设计:
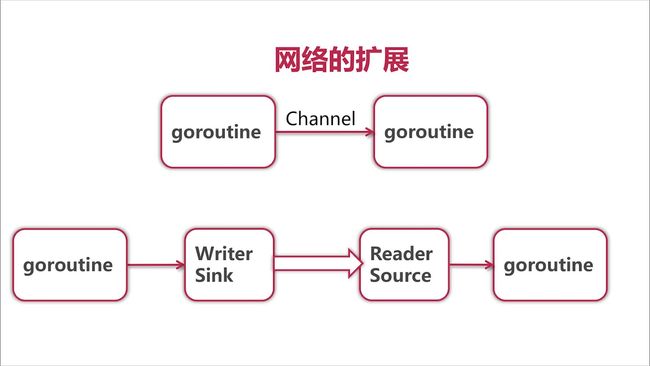
图解: 网络版的修改
网络版只是在完整外排序的版本上, 新增了从网络读写数据, 并相应修改 pipeline 即可
package main
import (
"net"
"bufio"
"encoding/binary"
"os"
"strconv"
"time"
"fmt"
"sort"
"io"
)
var startTime time.Time
func main() {
startTime = time.Now()
// 测试 net server
//netPipeline("small.in", 512, 4) // 按照cpu核数设置节点数, 减少协程间抢占带来性能损耗
//time.Sleep(time.Hour)
// 测试 small
p := netPipeline("small.in", 512, 4)
writeToFile(p, "small.out")
printFile("small.out", -1)
// 测试 large
//p := netPipeline("small.in", 512, 4)
//writeToFile(p, "small.out")
//printFile("small.out", -1)
}
func netPipeline(filename string, fileSize, chunkCount int) <-chan int {
chunkSize := fileSize / chunkCount // fileSize/8/chunkCount = int/chunk, 这里简单处理, 设置为可以整除的参数
sortAddr := []string{}
for i := 0; i < chunkCount; i++ {
file, err := os.Open(filename) // 为什么没有用 defer file.close() ? 因为需要在函数外去关闭掉, 比较麻烦, 这里暂时省略
if err != nil {
panic(err)
}
file.Seek(int64(i*chunkSize), 0) // 定位到每个 chunk 的起始位置
s := readerChunk(bufio.NewReader(file), chunkSize)
addr := ":" + strconv.Itoa(7000 + i) // 设置不同端口号来设置不同的 server
netSink(addr, memSort(s)) // 注意 pipeline 的设计思路是建立执行流程, 真正开始执行在 pipeline 创建之后
sortAddr = append(sortAddr, addr)
}
//return nil // 测试 net server
sortResults := []<-chan int{}
for _,addr := range sortAddr {
sortResults = append(sortResults, netSource(addr))
}
return mergeN(sortResults...)
}
func writeToFile(ch <-chan int, filename string) {
file, err := os.Create(filename)
if err != nil {
panic(err)
}
defer file.Close()
writer := bufio.NewWriter(file)
defer writer.Flush() // defer 是 LIFO
for v := range ch {
buffer := make([]byte, 8)
binary.BigEndian.PutUint64(buffer, uint64(v))
writer.Write(buffer)
}
}
func printFile(filename string, count int) {
file, err := os.Open(filename)
if err != nil {
panic(err)
}
defer file.Close()
p := readerChunk(file, -1) // -1 的作用体现出来了, 这里就可以读取全部文件
if count == -1 {
for v := range p {
fmt.Println(v)
}
} else {
n := 0
for v := range p {
fmt.Println(v)
n++
if n >= count {
break
}
}
}
}
func netSink(addr string, in <-chan int) {
listener, err := net.Listen("tcp", addr)
if err != nil {
panic(err)
}
go func() {
defer listener.Close()
conn, err := listener.Accept() // 通常 accept() 要放到 for{} 中不断的接收请求, 这里只处理一次就关闭了
if err != nil {
panic(err)
}
defer conn.Close()
writer := bufio.NewWriter(conn)
defer writer.Flush() // 别忘了 flush buffer
for v := range in {
buffer := make([]byte, 8)
binary.BigEndian.PutUint64(buffer, uint64(v))
writer.Write(buffer)
}
}()
}
func netSource(addr string) <-chan int {
out := make(chan int)
go func() {
conn, err := net.Dial("tcp", addr)
if err != nil {
panic(err)
}
defer conn.Close()
r := readerChunk(bufio.NewReader(conn), -1)
for v := range r {
out <- v
}
close(out)
}()
return out
}
// 递归解决两两归并
func mergeN(ins ...<-chan int) <-chan int {
if len(ins) == 1 {
return ins[0]
}
m := len(ins) / 2
// ins[0..m) + ins[m..end)
return merge(mergeN(ins[:m]...),
mergeN(ins[m:]...))
}
func merge(in1, in2 <-chan int) <-chan int {
out := make(chan int, 1024)
go func() {
// 归并的过程要处理某个通道可能没有数据的情况, 代码非常值得一读
v1, ok1 := <-in1
v2, ok2 := <-in2
for ok1 || ok2 {
if !ok2 || (ok1 && v1 <= v2) {
out <- v1
v1, ok1 = <-in1
} else {
out <- v2
v2, ok2 = <-in2
}
}
close(out)
fmt.Println("merge done: ", time.Now().Sub(startTime))
}()
return out
}
// 添加 chunk 来读取文件,
func readerChunk(reader io.Reader, chunkSize int) <-chan int {
out := make(chan int, 1024) // 性能优化, 给 channel 添加 buffer, 而不是收一个就发一个
bytesRead := 0
go func() {
buffer := make([]byte, 8) // int: 64bit -> 8byte
for {
n, err := reader.Read(buffer)
bytesRead += n
if n > 0 { // 可能数据不足 8byte
v := int(binary.BigEndian.Uint64(buffer))
out <- v
}
// 使用 -1 表示不添加 chunk 大小限制
// 使用是 >=, 读取区间是 [0, chunkSize)
if err != nil || (chunkSize != -1 && bytesRead >= chunkSize) {
break
}
}
close(out)
}()
return out
}
func memSort(in <-chan int) <-chan int {
out := make(chan int, 1024)
go func() {
// read into memory
a := []int{}
for v := range in {
a = append(a, v)
}
fmt.Println("read into memory: ", time.Now().Sub(startTime))
// sort
sort.Ints(a)
fmt.Println("sort done: ", time.Now().Sub(startTime))
// output
for _, v := range a {
out <- v
}
close(out)
}()
return out
}
写在最后
go 的「强制」在编程方面感觉优点大于缺点:
- 强制代码风格: 读/写代码都轻松了不少
- 强制类型检查: 出错时的错误提示非常友好
书写过程中, 基本根据编译器提示, 就可以把大部分 bug 清理掉.
go语言三大特色:
- 面向接口, 比如示例中的 Reader/Writer, 从而可以轻松添加 buffer 进行性能优化
- 函数式, go语言中函数式一等公民
- 并发编程: go + channel
再次推荐一下 go, 给想要写 并发编程 的程序汪, 就如 ccmouse大大的教程所说:
感受并发编程的乐趣
资源推荐:
- 首推 ccmouse大大的视频教程: 慕课网 - 搭建并行处理管道,感受GO语言魅力
- 同时推荐看完一本书 go并发编程: 讲解并发编程相关知识和 go并发编程原理 上面非常透彻, 几个实战的项目也适合 ccmouse大大推荐的学习方式 -- 不那么简单的项目来练手