词向量总结
词向量
词向量是自然语言理解的重要工具,它的核心思想是把词映射到一个向量空间,并且这个向量空间很大程度上保留了原本的语义。词向量既可以作为对语料进行数据挖掘的基础,也可以作为更复杂的模型的输入,是现在 nlp 的主流工具。下面就总结一下 nlp 中经典的词向量方法,并且用一些开源工具进行测试。
onehot
直接对词进行 onehot 编码,缺点显而易见,一是 onehot 编码向量维度将会很高,二是 onehot 编码并不能体现语义信息
GloVe(Global Vectors for Word Representation)
Pennington, Jeffrey, Richard Socher, and Christopher Manning. “Glove: Global vectors for word representation.” Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
根据语料,我们可以得出词的共现矩阵 X X X,其元素为 X i , j X_{i,j} Xi,j,表示在整个语料库中,单词 i i i,和单词 j j j共同出现在一个窗口中的次数。
(原文对代价函数的推导感觉有点绕,既然原文的推导主要是是逻辑推理,而不是数学推导,下面就说一下我的推理版本)
因为向量空间要保持语义的信息,根据最大熵模型(softmax),对于单词单词 i i i和单词 j j j的词向量 v i , v j v_i,v_j vi,vj应该有 X i , j ∑ i , j X i , j ∝ e x p ( v i T v j ) s u m i , j e x p ( v i T v j ) \frac{X_{i,j}}{\sum_{i,j}X_{i,j}}\propto \frac{exp(v_i^Tv_j)}{sum_{i,j}exp(v_i^Tv_j)} ∑i,jXi,jXi,j∝sumi,jexp(viTvj)exp(viTvj),我们不妨假设 e x p ( v i T v j ) ∝ X i , j exp(v_i^Tv_j)\propto X_{i,j} exp(viTvj)∝Xi,j,之所以正比是因为两个词共现次数不但和词之间的语义相似性有关,也和词本身出现的可能性有关,需要把这个因素考虑进去(因为两个相似的词可能出现的频率都很小,但是不能因为出现的频率都很小而让他们不相似),可以得到
v i T v j + b i + b j = l o g X i , j v_i^Tv_j+b_i+b_j=log X_{i,j} viTvj+bi+bj=logXi,j
b i b_i bi、 b j b_j bj是单词 i i i和单词 j j j的偏差项。
那么我们定义损失函数
J = ∑ i , j f ( X i , j ) ( v i T v j + b i + b j − l o g ( X i , j ) ) 2 J=\sum_{i,j}f(X_{i,j})(v_i^Tv_j+b_i+b_j-log(X_{i,j}))^2 J=i,j∑f(Xi,j)(viTvj+bi+bj−log(Xi,j))2
f f f是权重函数,因为对待不同的频次的共现单词对,我们的重视程度是不同的,作者通过实验确定权重函数为:
f ( x ) = { ( x / x m a x ) α , i f x < x m a x 1 , e l s e f(x)=\left\{ \begin{array}{lr}{(x/x_{max})^{\alpha}, if~x<x_{max}} \\ {1, else} \end{array} \right. f(x)={(x/xmax)α,if x<xmax1,else
有了损失函数,我们就可以进行训练了,作者采用了AdaGrad的梯度下降算法,对矩阵 X X X中的所有非零元素进行随机采样,learning rate 设为0.05,在 vector size 小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。最终学习得到的是两个vector是 v v v和 v ^ \hat{v} v^(对应着顺序前后的 v v v),因为 X X X是对称的,理论上 v v v和 v ^ \hat{v} v^是一样的,他们唯一的区别是初始化的值不一样,所以导致最终的值不一样。这两者其实是等价的,都可以当成最终的结果来使用。为了提高鲁棒性,最终选择两者之和作为最终的vector(两者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性)。
NNLM(Neural Network Language Model)
Neural Network Language Model. Bengio. 2003
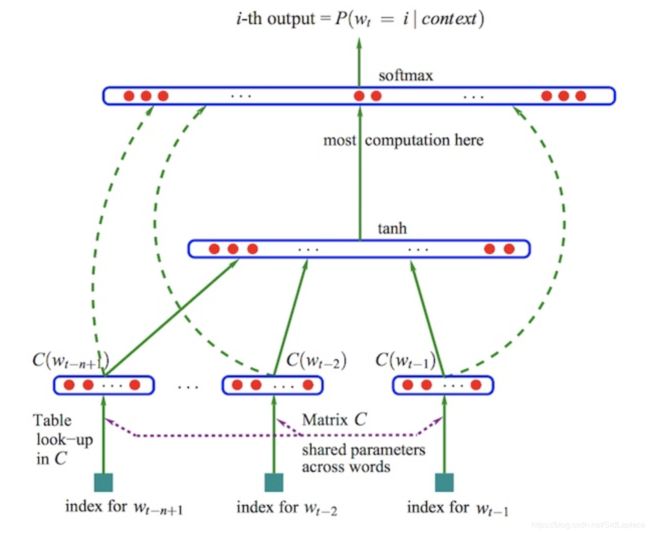
NNLM本身不产生词向量,但是是下面两种词向量的思想来源。NNLM要做的事情是通过前 n n n个词预测下一个出现的词,过程也比较简单,先对前 n n n个词进行 onehot 编码,在对每个 onehot 乘一个矩阵 C 来降维,再把这 n n n个向量拼接起来,输入到全联接网络中 softmax 输出各个词出现的概率。onehot 乘一个矩阵 C 得到的向量就有点词向量的意思。
CBOW(Continuous Bag-of-Words 连续词袋) 和 Skip-gram
Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
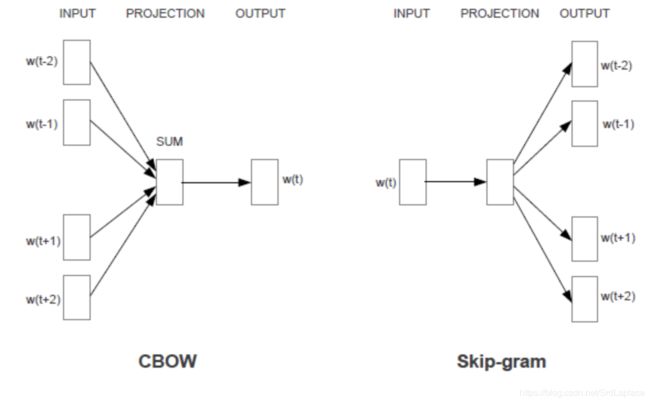
和 NNLM 思想类似,CBOW 和 Skip-gram 也是根据 contex 来预测单词,与 NNLM 相比做的优化是采用了 hierarchical softmax 来替代 NNLM 中的 C。hierarchical softmax 就是根据语料产生一棵 haffman tree,每个叶子结点代表一个单词的词向量,非叶子节点上也有词向量,只不过不是对应具体单词,得到结果后通过对叶子节点上与叶子结点上的词向量求一个2分类的 softmax 来决定走那条路径,优化时也一并优化叶子结点上和非叶子结点上的词向量。
CBOW
CBOW 认为窗口中间位置单词的出现概率为 v I v O T ∑ v v I v T \frac{v_Iv^T_O}{\sum_vv_Iv^T} ∑vvIvTvIvOT, v I v_I vI为窗口内其他单词的词向量的和。也就是说目标函数是
J = ∑ c ∈ c o r p u s l o g v I c v c T ∑ v v I c v T J=\sum_{c\in corpus}log\frac{v_{I_c}v^T_c}{\sum_vv_{I_c}v^T} J=c∈corpus∑log∑vvIcvTvIcvcT
需要最大化 J J J得到词向量,可以采用梯度下降对词向量进行训练。
Skip-gram
Skip-gram 和 CBOW 正好相反, 是由当前词来预测 contex,目标函数是
J = ∑ c ∈ c o r p u s s u m t ∈ c o n t e x ( c ) l o g v t v c T ∑ v v v c T J=\sum_{c\in corpus}sum_{t\in contex(c)}log\frac{v_tv^T_c}{\sum_vvv^T_c} J=c∈corpus∑sumt∈contex(c)log∑vvvcTvtvcT
需要最大化 J J J得到词向量,可以采用梯度下降对词向量进行训练。Skip-gram 算法对低频词敏感。
实验代码
训练
GloVe
https://github.com/stanfordnlp/GloVe
Git clone 下来 GloVe 的代码后,make 生成 build 文件,里面的 demo.sh 时一个训练的 demo,过程是先 make,然后下载语料在进行训练,可以改成自己的训练数据。
下面介绍要训练自己的 GloVe 的过程:
- 准备训练数据:训练数据的格式是每行是一句话(一段文章),去掉标点,用空格分隔每个词,中文记得要分词。
- build/vocab_count:输入是准备好的训练数据,输出词汇表。词汇表每行表示一个词,含有词汇和频次,用空格分隔。可选参数:“-min-count ”表示作为词汇的最低出现次数,”-max-vocab ”表示词汇表最大的规模(超过规模的低频词会随机采样到词汇表中),”-verbose ”表示屏幕输出信息显示的程度;
- build/cooccur:输入是训练数据,输出共现矩阵。可选参数:”-verbose ”同上,”-symmetric ”如果输入0,则只记录左侧的共现情况,输入1(默认)记录两侧的共现情况,”-window-size ”每侧的窗口大小,”-vocab-file ”词汇表文件,默认是 vocab.txt,”-memory ”内存限制(软限制,并不精确),”-max-product ”共现矩阵的大小,根据词频来限制,”-overflow-length ”限制写入硬盘的稀疏矩阵的大小,”-overflow-file ”稀疏矩阵的临时文件,”-distance-weighting ”如果为0,不根据单词间距离进行加权,为1根据距离进行加权;
- build/shuffle:输入共现矩阵,输出置乱的共现矩阵。可选参数:”-verbose ”同上,”-memory ”内存限制,”-array-size ”写如硬盘前没块矩阵大小限制,”-temp-file ”临时文件名称;
- build/glove:输入(置乱)的共现矩阵和词汇表,输出词向量。可选参数:”-verbose ”同上,”-write-header ”如果为1,第一行写入词汇表大小和词向量长度,为0不写,”-vector-size ”词向量长度,”-threads ”线程数,”-iter ”迭代次数,”-eta ”学习率,”-alpha ” weighting function 的指数参数,“-x-max ”weighting function 的参数,”-binary ”储存向量的格式,“-model ”保存模型的模式,”-vocab-file ”词汇表,”-save-file ”保存文件的名字,”-gradsq-file ”保存梯度的文件名,”-save-gradsq ”是否保存梯度文件,默认不保存,”-checkpoint-every ”每轮迭代是否保存文件。
准备好数据集”corpus.txt”,运行下面的 shell 脚本,得到词向量文件 vectors.txt
#!/bin/bash
set -e
BUILDDIR=build
CORPUS=corpus.txt
VOCAB_FILE=vocab.txt
SAVE_FILE=vectors
VERBOSE=2
MEMORY=4.0
VOCAB_MIN_COUNT=5
WINDOW_SIZE=2
COOCCURRENCE_FILE=cooccurrence.bin
COOCCURRENCE_SHUF_FILE=cooccurrence.shuf.bin
VECTOR_SIZE=300
MAX_ITER=25
WINDOW_SIZE=2
BINARY=0
NUM_THREADS=8
X_MAX=10
HEADLINE=1
echo "$ $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE"
$BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
echo "$ $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE"
$BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE
echo "$ $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE"
$BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
echo "$ $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE -write-header $HEADLINE"
$BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE -write-header $HEADLINE
CBOW 和 Skip-gram
使用 gensim 训练 CBOW 和 Skip-gram 词向量
先安装好 gensim
sudo pip install gensim
用“gensim.models.Word2Vec”来训练词向量,准备好分词的数据,数据为一个列表,每个元素为一句话或一篇文章的分词列表重要的参数有
model = Word2Vec(sentences=sentences, min_count=5, sg=1, iter=5, hs=0) # fit skip-gram w2v
- min_count:最小词频
- sg:词向量的类型,为1则为 Skip-gram,为0则为 CBOW
- iter:迭代次数
- hs:是否采用 hierarchical softmax
用”gensim.corpora.Dictionary”得到词典,用“gensim.models.TfidfModel”分析词的 idf 值:
dct = Dictionary(sentences) # fit dictionary
dct.save('test.dct')
corpus = [dct.doc2bow(sentence) for sentence in sentences]
idf_model = TfidfModel(corpus) # fit idf
idf_model.save('test.idf')
测试
用”gensim.models.WordEmbeddingsKeyedVectors.load”训练好的词向量(GloVe 训练好的也可以用 gensim 载入,只不过不能继续训练了)
gv_model = KeyedVectors.load_word2vec_format("w2v/vectors.txt",binary=False)
sg_hs_model = WordEmbeddingsKeyedVectors.load("w2v/sg_hs.w2v")
sg_ng_model = WordEmbeddingsKeyedVectors.load("w2v/sg_ng.w2v")
cb_hs_model = WordEmbeddingsKeyedVectors.load("w2v/cb_hs.w2v")
cb_ng_model = WordEmbeddingsKeyedVectors.load("w2v/cb_ng.w2v")
vocab = list(sg_hs_model.vocab.keys())
dct = Dictionary.load('w2v/test.dct')
idf_model = TfidfModel.load('w2v/test.idf')
然后就可以进行测试了,如果当时保存不止是词向量,也把中间的变量保存下来(这样就可以继续训练)的话用”gensim.models.Word2Vec.load”来载入
然后可以用 model 里的方法来做一些数据挖掘,例如计算词向量的相似度,找到与词向量最接近的一些词向量,向量加减法找到向量之间的关系,在这里就不赘述了,根据需求来找相应的词向量