大数据处理基础之利用hadoop写的简单mapreduce案例
案例:
需要处理的数据:
13877779999 bj zs 2145
13766668888 sh ls 1028
13766668888 sh ls 9987
13877779999 bj zs 5678
13544445555 sz ww 10577
13877779999 sh zs 2145
13766668888 sh ls 9987
处理后输出格式为:名字 电话+地区+总流量
分析: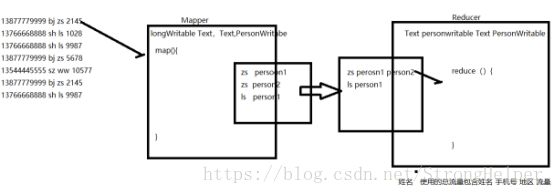
由于此处输出的value为 电话+地区+总流量,所以我们要自定义数据类型。
package cn.tedu.flow;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.io.Serializable;
import org.apache.hadoop.io.Writable;
/**
* MR中自定义数据类型需要实现Writable接口来序列化
* java中原生序列化 实现的是Serializable接口,在hadoop并没有使用
* @author mi
*
*/
public class PersonWritable implements Writable{
private String phone;//手机号
private String addr;//地区
private String name;//姓名
private String flow;//流量
//该方法是将对象中的属性进行序列化
@Override
public void write(DataOutput out) throws IOException {
//UTF ----对应的是字符串 参数是指定需要序列化的属性名称
out.writeUTF(phone);
out.writeUTF(addr);
out.writeUTF(name);
out.writeUTF(flow);
}
//该方法是将对象中的属性进行反序列化
@Override
public void readFields(DataInput in) throws IOException {
//in.readUTF() 将序列化的数据 进行反序列化 并将结果赋值给属性
this.phone = in.readUTF();
this.addr = in.readUTF();
this.name = in.readUTF();
this.flow = in.readUTF();
}
//提供getter and setter方法 ---右击--source--generat getterand sertter
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getAddr() {
return addr;
}
public void setAddr(String addr) {
this.addr = addr;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getFlow() {
return flow;
}
public void setFlow(String flow) {
this.flow = flow;
}
//生成toString()方法 为了方便查看对象的内容 需要重写toString()
@Override
public String toString() {
return "PersonWritable [phone=" + phone + ", addr=" + addr + ", name=" + name + ", flow=" + flow + "]";
}
}Mapper类:
package cn.tedu.flow;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowMapper extends Mapper<LongWritable, Text, Text, PersonWritable> {
@Override
public void map(LongWritable key, Text value, Mapper.Context context) throws IOException, InterruptedException {
// 获取每一行数据
String line = value.toString();
//对每一行数据 利用空格分割
String[] data = line.split(" ");
//创建一个PersonWritable 对象
PersonWritable person = new PersonWritable();
//针对每一个person中的属性赋值
person.setPhone(data[0]);
person.setAddr(data[1]);
person.setName(data[2]);
person.setFlow(data[3]);
//将每一个person对象作为value输出
context.write(new Text(data[2]), person);
}
}
reducer类:
package cn.tedu.flow;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowReducer extends Reducer<Text, PersonWritable, Text, PersonWritable>{
@Override
protected void reduce(Text key, Iterable values,
Reducer.Context context) throws IOException, InterruptedException {
int sumFlow = 0;
/*//最终输出的value
PersonWritable person1 = new PersonWritable();
//遍历values中的元素 并获取每一元素中的流量
for(PersonWritable person:values){
//每一个Person的流量
int flow = Integer.parseInt(person.getFlow());
sumFlow=flow+sumFlow;
person1.setPhone(person.getPhone());
person1.setAddr(person.getAddr());
person1.setName(person.getName());
}
person1.setFlow(sumFlow+"");*/
Iterator it = values.iterator();
//获取第一个元素
PersonWritable person = it.next();
int firstFlow = Integer.parseInt(person.getFlow());
//遍历从第二个元素开始
while(it.hasNext()){
int flow = Integer.parseInt(it.next().getFlow());
//累加求流量总和
firstFlow = flow+firstFlow;
}
//在person中设置总流量
person.setFlow(firstFlow+"");
//输出结果
context.write(key, person);
}
}
实现自定义分区类:
package cn.tedu.flow;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
//自定义分区
//Partitioner 其中key 是mapper输出的key的类型 value是mapper输出的value的数据类型
public class FlowPartitoner extends Partitioner<Text, PersonWritable>{
@Override
public int getPartition(Text key, PersonWritable value, int numPartitions) {
//1. key mapper输出key传入的值
//2. value mapper输出value传入的值
//3. numPartitions 执行job一共有的 分区数
//根据地区来分区 bj sz sh分别存在不同的文件中
String add = value.getAddr();
if(add.equals("bj")){
return 0;
}else if(add.equals("sh")){
return 1;
}else{
return 2;
// key.hashCode()& Integer.MAX_VALUE % numPartitions 默认分区
}
}
}
Driver执行类:
package cn.tedu.flow;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowDriver {
public static void main(String[] args) throws Exception {
//1. 获取配置文件对象
Configuration conf = new Configuration();
//2. 获取job对象
Job job = Job.getInstance(conf);
//3. 设置job 处理的mapper类
job.setMapperClass(FlowMapper.class);
//4. 设置job 处理的reducer类
job.setReducerClass(FlowReducer.class);
//5. mapper reducer输出的key value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PersonWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(PersonWritable.class);
job.setNumReduceTasks(3);
//设置处理job任务分区的类
job.setPartitionerClass(FlowPartitoner.class);
//6. job处理的数据的路径 写目录也可以是处理整个目录下的数据
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.174.20:9000/data/flow.txt"));
//7. job处理后的数据 存放地址
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.174.20:9000/data/result"));
job.waitForCompletion(true);
}
}
整个mapreduce实现的机制:
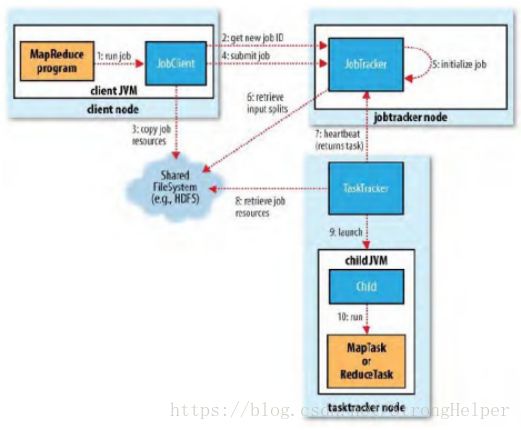
- runjob: 检查环境 例如:路劲是否合法,如提交不正确,则停止提交任务,报错。
2.申请job id,job id作用:1. job任务的唯一标识 2. 利于查询 kill 任务
3.jobclient 将申请的job id ,还有jobresources(一个mr程序对应jar)传到hdfs中 - 由jobtracker提交任务,在这个过程中,JobClient把jobid,以及jar包在HDFS上的存储路径提交给jobTracker。
5.初始化任务 jobtracker根据提交的job 来计算有多少分片(一个分片对应一个任务)
6.根据计算的任务 来再计算有多少个map 多少个reduce
7.根据jobtrack分配的任务,taskTracker利用心跳机制领取老大的任务
8.从hdfs中抓取jar 包到对应的tasktracker
9.其中jvm执行程序处理数据