概率图系列之隐马尔可夫模型(HMM)
文章目录
- 概率图模型
- 隐马尔可夫模型(HMM)
- 观测序列的生成
- HMM的三个基本问题及解法
- 概率问题
- 直接计算
- 前向算法
- 后向算法
- 概率和期望
- 学习问题
- 监督学习
- Baum-Welch 算法
- 预测问题
- 近似算法
- 维特比算法(Viterbi)
- 结语
概率图模型
概率图模型是一类用图来表达变量相关关系的概率模型。常见的是用一个节点表示一个或一组随机变量,节点之间的边表示变量之间的概率相关关系,如下图:

概率图根据边的性质,可以划分为两种:
- 有向图无环图——有向图模型或贝叶斯网
- 无向图——无向图图或马尔可夫网
隐马尔可夫模型(HMM)
性质:结构最简单的动态贝叶斯网——有向无环图
描述:由一个隐藏的马尔可夫链生成不可观测的状态随机序列,再由各个状态生成一个可观测而产生观测随机序列的过程。
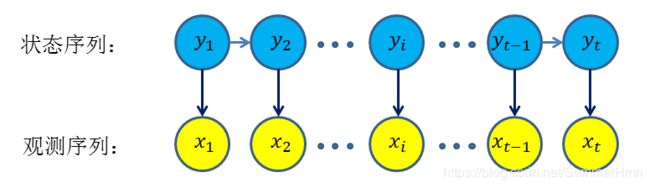
上图的箭头表示依赖关系,HMM做了两个基本假设:
- 齐次马尔可夫假设:隐藏的马尔可夫链在任一时刻 t t t的状态只依赖于上一个时刻 t − 1 t-1 t−1的状态
p ( y t ∣ y 1 , x 1 , y 2 , x 2 . . . , y t − 1 , x t − 1 ) = p ( y t ∣ y t − 1 ) p(y_t|y_1,x_1,y_2,x_2...,y_{t-1},x_{t-1})=p(y_t|y_{t-1}) p(yt∣y1,x1,y2,x2...,yt−1,xt−1)=p(yt∣yt−1) - 观测独立性假设:任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测即状态无关
p ( x t ∣ y 1 , x 1 , y 2 , x 2 . . . , y t − 1 , x t − 1 , y t ) = p ( x t ∣ y t ) p(x_t|y_1,x_1,y_2,x_2...,y_{t-1},x_{t-1},y_t)=p(x_t|y_t) p(xt∣y1,x1,y2,x2...,yt−1,xt−1,yt)=p(xt∣yt)
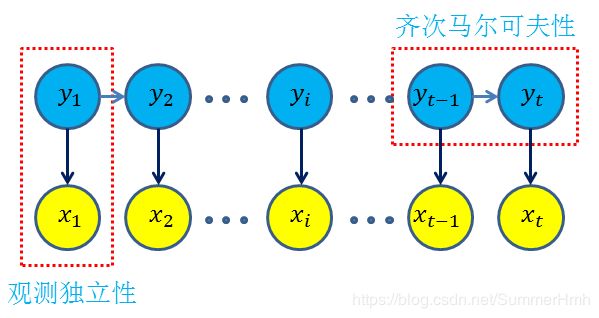
基于如上的两个假设,可以获取所有变量的联合概率分布为:
p ( x 1 , y 1 , x 2 , y 2 , . . . , x t , y t ) = p ( y 1 ) p ( x 1 ∣ y 1 ) ∏ i = 2 t p ( y i ∣ y i − 1 ) p ( x i ∣ y i ) p(x_1,y_1,x_2,y_2,...,x_t,y_t)=p(y_1)p(x_1|y_1)\prod_{i=2}^tp(y_i|y_{i-1})p(x_i|y_i) p(x1,y1,x2,y2,...,xt,yt)=p(y1)p(x1∣y1)i=2∏tp(yi∣yi−1)p(xi∣yi)
其中 y ∈ { s 1 , s 2 , . . . , s N } y \in \{s_1,s_2,...,s_N\} y∈{s1,s2,...,sN},表示有N种状态, x ∈ { o 1 , o 2 , . . . , o M } x \in \{ o_1,o_2,...,o_M\} x∈{o1,o2,...,oM},表示有M种观测值。
除了结构信息,根据联合概率分布可得,如果要确定一个HMM,需要以下三组参数:
- 初始状态概率:模型在初始时刻各状态出现的概率,即 p ( y ) p(y) p(y),通常记为 π = ( π 1 , π 2 , . . . , π N ) \mathbf{\pi}=(\pi_1,\pi_2,...,\pi_N) π=(π1,π2,...,πN), N N N为状态的种类,其中
π i = p ( y = s i ) , 1 ⩽ i ⩽ N \pi_i=p(y=s_i),1 \leqslant i \leqslant N πi=p(y=si),1⩽i⩽N - 状态转移概率:模型在各个状态间转换的概率,通常记为 A = [ a i j ] N × M \mathbf{A}=[a_{ij}]_{N\times M} A=[aij]N×M
a i j = p ( y t + 1 = s j ∣ y t = s i ) a_{ij}=p(y_{t+1}=s_j|y_t=s_i) aij=p(yt+1=sj∣yt=si) - 输出观测概率:模型根据当前状态获得各个观测值得概率,通常记为 B = [ b i j ] N × M \mathbf{B}=[b_{ij}]_{N \times M} B=[bij]N×M,状态 s i s_i si下观测值为 o j o_j oj的概率
b i j = p ( x t = o j ∣ y t = s i ) b_{ij}=p(x_t=o_j|y_t=s_i) bij=p(xt=oj∣yt=si)
这样,一个HMM模型可以表示为 λ = [ A , B , π ] \lambda=[\mathbf{A},\mathbf{B},\mathbf{\pi}] λ=[A,B,π]
观测序列的生成
已知HMM的模型 λ = [ A , B , π ] \lambda=[\mathbf{A},\mathbf{B},\mathbf{\pi}] λ=[A,B,π],可根据模型生成观测序列
-
步骤
输入:HMM模型 λ = [ A , B , π ] \lambda=[\mathbf{A},\mathbf{B},\mathbf{\pi}] λ=[A,B,π],观测序列长度 T T T
输出:观测序列 x = ( x 1 , x 2 , . . . , x T ) \mathbf{x}=(x_1,x_2,...,x_T) x=(x1,x2,...,xT)
(1)设置 t = 1 t=1 t=1,并根据初始状态概率 π \mathbf{\pi} π产生状态 y 1 y_1 y1
(2)按照状态 y t y_t yt的观测输出概率 B \mathbf{B} B输出观测序列 x t x_t xt
(3)根据状态转移概率 A \mathbf{A} A和 y t y_t yt产生状态 y t + 1 y_{t+1} yt+1
(4) t = t + 1 t=t+1 t=t+1,跳转到第(2)步,如果 t = T t=T t=T,结束输出 -
代码
初始状态,和观测状态都是属于多项分布,因此通过多项分布进行模拟
import numpy as np
np.random.seed(1234) # 设置随机种子,使得可以复现
#numpy.random.multinomial(n, pvals, size=None) n : int:实验次数 pvals:浮点数序列,长度p,P个不同结果的概率,值和为1 size : 输出形状,每次为一个迭代
#测试np.random.multinomial效果
np.random.multinomial(5, [0.3,0.7], size=1)
np.random.multinomial(5, [0.3,0.7], size=2)
#生成序列代码
class HMM():
def __init__(self,A,B,pi,N=0,M=0):
self.A=A
self.B=B
self.pi=pi
if N==0 :
self.N=len(self.A)
else:
self.N=N
if M==0:
self.M=len(self.B[0])
else:
self.M=M
# 模拟序列
def simulate(self,T):
def genetate_from(probs):
return np.where(np.random.multinomial(1,probs)==1)[0][0]
obs=np.zeros(T,dtype=int)
states=np.zeros(T,dtype=int)
states[0]=genetate_from(self.pi)
obs[0]=genetate_from(self.B[states[0],:])
for t in range(1,T):
states[t]=genetate_from(self.A[states[t-1],:])
obs[t]=genetate_from(self.B[states[t],:])
return states,obs
#模型参数
A=np.array([[0,1,0,0],[0.4,0,0.6,0],[0,0.4,0,0.6],[0,0,0.5,0.5]])
B=np.array([[0.5,0.5],[0.3,0.7],[0.6,0.4],[0.8,0.2]])
pi=np.array([0.25]*4)
states_bag=["box1","box2","box3","box4"]
obs_bag=["red","white"]
#进行模拟输出
hmm=HMM(A,B,pi)
states,obs=hmm.simulate(10)
print("状态序列:",end=" ")
for i in states:
print("{:6s}".format(states_bag[i]),end=" ")
print()
print("观测序列:",end=" ")
for i in obs:
print("{:6s}".format(obs_bag[i]),end=" ")
结果:
![]()
HMM的三个基本问题及解法
HMM主要有三个应用点
- 概率问题:已知观测序列 x \mathbf{x} x和模型 λ \lambda λ,计算在模型 λ \lambda λ下,观测序列 x \mathbf{x} x出现的概率 p ( x ∣ λ ) p(\mathbf{x}|\lambda) p(x∣λ)
- 学习问题:已知观测序列 x \mathbf{x} x,估计模型的参数 λ = [ A , B , π ] \lambda=[\mathbf{A},\mathbf{B},\mathbf{\pi}] λ=[A,B,π],使得该模型下观测序列概率 p ( x ∣ λ ) p(\mathbf{x}|\lambda) p(x∣λ)最大,可用MLE
- 预测问题:已知观测序列 x \mathbf{x} x和模型 λ \lambda λ,求最有可能的对应状态序列
概率问题
直接计算
列举长度为 T T T所有可能的状态序列 y \mathbf{y} y,一共有 N T N^T NT种,然后求各个状态对应观测序列的联合概率 p ( x , y ∣ λ ) p(\mathbf{x},\mathbf{y}|\lambda) p(x,y∣λ),再对所有可能的状态序列求和,得到 p ( x ∣ λ ) p(\mathbf{x}|\lambda) p(x∣λ)
p ( x , y ∣ λ ) = p ( x ∣ y , λ ) p ( y ∣ λ ) p(\mathbf{x},\mathbf{y}|\lambda)=p(\mathbf{x}|\mathbf{y},\lambda)p(\mathbf{y}|\lambda) p(x,y∣λ)=p(x∣y,λ)p(y∣λ)
上式计算量很大,是 O ( T N T ) O(TN^T) O(TNT),一般不直接计算。
前向算法
前向概率:给定HMM的模型 λ \lambda λ,定义到时刻 t t t部分观测序列为 o 1 , o 2 , . . . , o t o_1,o_2,...,o_t o1,o2,...,ot,且状态为 s i s_i si的概率为前向概率,记作
α t ( i ) = p ( o 1 , o 2 , . . . , o t , y t = s i ∣ λ ) \alpha_t(i)=p(o_1,o_2,...,o_t,y_t=s_i|\lambda) αt(i)=p(o1,o2,...,ot,yt=si∣λ)
-
算法步骤
输入:HMM模型 λ = [ A , B , π ] \lambda=[\mathbf{A},\mathbf{B},\mathbf{\pi}] λ=[A,B,π],观测序列 x = ( x 1 , x 2 , . . . , x T ) \mathbf{x}=(x_1,x_2,...,x_T) x=(x1,x2,...,xT)
输出:观测序列概率 p ( x ∣ λ ) p(\mathbf{x}|\lambda) p(x∣λ)
(1)初始化,根据初始概率,计算状态为 s i s_i si,观测结果为 o 1 o_1 o1的概率
α 1 ( i ) = π i b i ( o 1 ) \alpha_1(i)=\pi_ib_i(o_1) α1(i)=πibi(o1)
(2)递推,对 t = 1 , 2 , . . . , T − 1 t=1,2,...,T-1 t=1,2,...,T−1
α t ( i ) = [ ∑ j = 1 N α t ( j ) a j i ] b i ( o t + 1 ) , i = 1 , 2 , . . . , N \alpha_t(i)=\left[\sum _{j=1}^N\alpha_t(j)a_{ji}\right]b_i(o_{t+1}),i=1,2,...,N αt(i)=[j=1∑Nαt(j)aji]bi(ot+1),i=1,2,...,N
(3)终止
p ( x ∣ λ ) = ∑ i = 1 N α T ( i ) p(\mathbf{x}|\lambda)=\sum_{i=1}^N\alpha_T(i) p(x∣λ)=i=1∑NαT(i) -
代码实现
#前向算法
def probsForward(self,x):
T=len(x)
alpha=np.zeros([T,self.N],dtype=float)
for t in range(T):
obt=int(x[t])
if t==0 :
alpha[t]=self.pi*self.B[:,obt]
else:
alpha[t]=np.multiply(np.sum(alpha[t-1]*self.A.T,axis=1),self.B[:,obt])
#print(alpha[t])
return np.sum(alpha[T-1]),alpha
时间复杂度 O ( N 2 T ) O(N^2T) O(N2T),从时间方向,进行如下计算
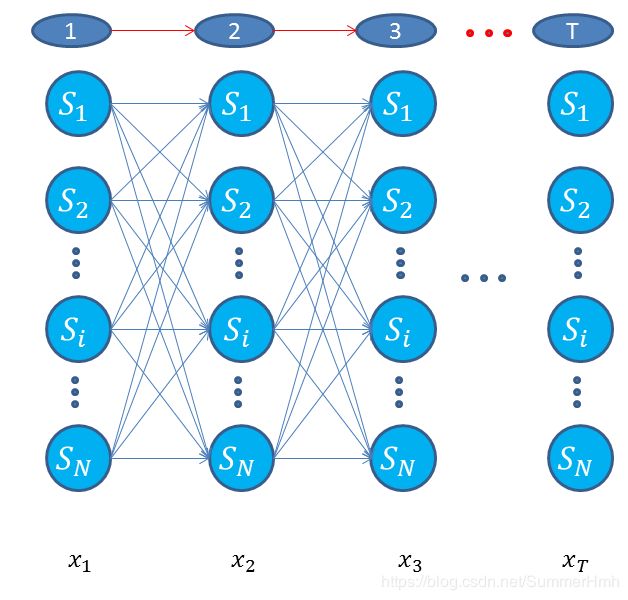
从时间切片,进行如下计算当前序列值为 o j o_j oj的概率

后向算法
后向概率:给定HMM的模型 λ \lambda λ,定义在 t t t时刻状态为 s i s_i si的条件下,从 t + 1 t+1 t+1到T的部分观测序列 o t + 1 , o t + 2 , . . . , o T , o_{t+1},o_{t+2},...,o_T, ot+1,ot+2,...,oT,$的概率为后验概率,记作
β t ( i ) = p ( o t + 1 , o t + 2 , . . . , o T ∣ y t = s i , λ ) \beta_t(i)=p(o_{t+1},o_{t+2},...,o_T|y_t=s_i,\lambda) βt(i)=p(ot+1,ot+2,...,oT∣yt=si,λ)
-
算法步骤
输入:HMM模型 λ = [ A , B , π ] \lambda=[\mathbf{A},\mathbf{B},\mathbf{\pi}] λ=[A,B,π],观测序列 x = ( x 1 , x 2 , . . . , x T ) \mathbf{x}=(x_1,x_2,...,x_T) x=(x1,x2,...,xT)
输出:观测序列概率 p ( x ∣ λ ) p(\mathbf{x}|\lambda) p(x∣λ)
(1)终值
β T ( i ) = 1 , i = 1 , 2 , . . , N \beta_T(i)=1,i=1,2,..,N βT(i)=1,i=1,2,..,N
(2)对于 t = T − 1 , T − 2 , . . . , 1 t=T-1,T-2,...,1 t=T−1,T−2,...,1
β t ( i ) = ∑ j = 1 N a i j b j ( o t + 1 ) β t + 1 ( j ) \beta_t(i)=\sum_{j=1}^Na_{ij}b_j(o_{t+1})\beta_{t+1}(j) βt(i)=j=1∑Naijbj(ot+1)βt+1(j)
(3)结束
p ( x ∣ λ ) = ∑ i = 1 N π i b i ( o 1 ) β 1 ( i ) p(\mathbf{x}|\lambda)=\sum_{i=1}^N\pi_ib_i(o_1)\beta_1(i) p(x∣λ)=i=1∑Nπibi(o1)β1(i) -
代码实现
#后向算法
def probsBack(self,x):
T=len(x)
beta=np.zeros([T,self.N],dtype=float)
for t in range(T-1,-1,-1):
if t==T-1:
beta[t]=[1]*self.N
else:
beta[t]=np.sum(self.A*self.B[:,int(x[t+1])]*beta[t+1],axis=1)
return np.sum(self.pi*self.B[:,int(x[0])]*beta[0]),beta
后向算法本质上跟前向算法一致,不过递推方向相反
概率和期望
-
给定模型 λ \lambda λ和观测 x \mathbf{x} x,在 t t t时刻处于状态 s i s_i si的概率
γ t ( i ) = p ( i t = s i ∣ λ , x ) = p ( i t = s i , x ∣ λ ) p ( x ∣ λ ) \gamma_t(i)=p(i_t=s_i|\lambda,\mathbf{x})=\frac{p(i_t=s_i,\mathbf{x}|\lambda)}{p(\mathbf{x}|\lambda)} γt(i)=p(it=si∣λ,x)=p(x∣λ)p(it=si,x∣λ) ∵ α t ( i ) β t ( i ) = p ( i t = s t , x ∣ λ ) \because \alpha_t(i)\beta_t(i)=p(i_t=s_t,\mathbf{x}|\lambda) ∵αt(i)βt(i)=p(it=st,x∣λ) ∴ γ t ( i ) = α t ( i ) β t ( i ) p ( x ∣ λ ) = α t ( i ) β t ( i ) ∑ j = 1 N α t ( j ) β t ( j ) \therefore \gamma_t(i)=\frac{ \alpha_t(i)\beta_t(i)}{p(\mathbf{x}|\lambda)}=\frac{ \alpha_t(i)\beta_t(i)}{\sum_{j=1}^{N}\alpha_t(j)\beta_t(j)} ∴γt(i)=p(x∣λ)αt(i)βt(i)=∑j=1Nαt(j)βt(j)αt(i)βt(i) -
给定模型 λ \lambda λ和观测 x \mathbf{x} x,在 t t t时刻处于状态 s i s_i si, t + 1 t+1 t+1时刻处于状态 s j s_j sj的概率
ξ t ( i , j ) = p ( i t = s i , i t + 1 = s j ∣ λ , x ) = p ( i t = s i , i t + 1 = s j , x ∣ λ ) p ( x ∣ λ ) \xi_t(i,j)=p(i_t=s_i,i_{t+1}=s_j|\lambda,\mathbf{x}) =\frac{p(i_t=s_i,i_{t+1}=s_j,\mathbf{x}|\lambda)}{p(\mathbf{x}|\lambda)} ξt(i,j)=p(it=si,it+1=sj∣λ,x)=p(x∣λ)p(it=si,it+1=sj,x∣λ)
∵ p ( i t = s i , i t + 1 = s j , x ∣ λ ) = α t ( s i ) a i j b j ( o t + 1 ) β t + 1 ( j ) \because p(i_t=s_i,i_{t+1}=s_j,\mathbf{x}|\lambda)=\alpha_t(s_i)a_{ij}b_j(o_{t+1})\beta_{t+1}(j) ∵p(it=si,it+1=sj,x∣λ)=αt(si)aijbj(ot+1)βt+1(j)
∴ ξ t ( i , j ) = α t ( s i ) a i j b j ( o t + 1 ) β t + 1 ( j ) ∑ j = 1 N ∑ i = 1 N α t ( s i ) a i j b j ( o t + 1 ) β t + 1 ( j ) \therefore \xi_t(i,j)=\frac{\alpha_t(s_i)a_{ij}b_j(o_{t+1})\beta_{t+1}(j)}{\sum_{j=1}^N\sum_{i=1}^{N}\alpha_t(s_i)a_{ij}b_j(o_{t+1})\beta_{t+1}(j)} ∴ξt(i,j)=∑j=1N∑i=1Nαt(si)aijbj(ot+1)βt+1(j)αt(si)aijbj(ot+1)βt+1(j) -
在观测 x \mathbf{x} x下状态 s i s_i si出现的期望值
∑ t = 1 T γ t ( i ) \sum_{t=1}^T\gamma_t(i) t=1∑Tγt(i) -
在观测 x \mathbf{x} x下由状态 s i s_i si转移的期望值
∑ t = 1 T − 1 γ t ( i ) \sum_{t=1}^{T-1}\gamma_t(i) t=1∑T−1γt(i) -
在观测 x \mathbf{x} x下由状态 s i s_i si转移到状态 s j s_j sj的期望值
∑ t = 1 T − 1 ξ t ( i , j ) \sum_{t=1}^{T-1}\xi_t(i,j) t=1∑T−1ξt(i,j)
学习问题
根据观测序列学习HMM的模型的过程
监督学习
- 条件:已知观测序列和对应的状态序列
- 方法:频率统计
- 不足:需要人工标注数据
Baum-Welch 算法
- 模型
p ( x ∣ λ ) = ∑ y p ( x ∣ y , λ ) p ( y ∣ λ ) p(\mathbf{x}|\lambda)=\sum_yp(\mathbf{x}|\mathbf{y},\lambda)p(\mathbf{y}|\lambda) p(x∣λ)=y∑p(x∣y,λ)p(y∣λ) - 方法:EM算法和拉格朗日乘子法
- 参数估计公式
a i j = ∑ t = 1 T − 1 ξ t ( i , j ) ∑ t = 1 T − 1 γ t ( i ) a_{ij}=\frac{\sum_{t=1}^{T-1}\xi _t(i,j)}{\sum_{t=1}^{T-1}\gamma_t(i)} aij=∑t=1T−1γt(i)∑t=1T−1ξt(i,j) b j ( k ) = ∑ t = 1 o t = v k T γ t ( j ) ∑ t = 1 T γ t ( j ) b_j(k)=\frac{\sum_{t=1o_t=v_k}^T\gamma_t(j)}{\sum_{t=1}^{T}\gamma_t(j)} bj(k)=∑t=1Tγt(j)∑t=1ot=vkTγt(j) π i = γ 1 ( i ) \pi_i=\gamma_1(i) πi=γ1(i)
-步骤
输入:观测数据 x \mathbf{x} x
输出:HMM的模型参数
(1)初始化模型参数
(2)递推,根据参数估计公式
(3)终止,得到模型参数 - 代码实现
def computeGammaAndXi(self,x):
_,alpha=self.probsForward(x)
_,beta=self.probsBack(x)
T=len(x)
gamma=np.zeros([T,self.N],dtype=float)
xi=np.zeros([T-1,self.N,self.N],dtype=float)
for t in range(T):
gamma[t]=np.multiply(alpha[t],beta[t])/np.sum(np.multiply(alpha[t],beta[t]))
if t < T-1:
tmp=np.sum(np.dot(alpha[t],self.A)*self.B[:,int(x[t])]*beta[t+1])
# for i in range(self.N):
# xi[t][i,:]=alpha[t][i]*self.A[i,:]*self.B[:,int(x[t+1])]*beta[t+1]/tmp
xi[t]=alpha[t]*self.A*self.B[:,int(x[t+1])]*beta[t+1]/tmp
return gamma,xi
#baum-Welch算法
def baumWelch(self,x,e=0.0005):
T=len(x)
# 初始化模型参数 不能这样初始化——随机初始化,同时满足约束条件——待添加,目前默认上一次计算的结果值
# self.A=np.ones([self.N,self.N],dtype=float)*1/self.N
# self.B=np.ones([self.N,self.M],dtype=float)*1/self.M
# self.pi=np.ones(self.N,dtype=float)*1/self.N
while True:
# E步
gamma,xi=self.computeGammaAndXi(x)
#M步
newPi=gamma[0]
newA=np.sum(xi,axis=0)/np.sum(gamma[:-1,:],axis=0)
newB=np.copy(self.B)
b_denominator=np.sum(gamma,axis=0)
for k in range(self.M):
temp_matrix=np.zeros((T,1))
for t in range(T):
if int(x[t])==k:
temp_matrix[t][0]=1
#print(gamma*temp_matrix)
newB[:,k]=np.sum(gamma*temp_matrix,axis=0)/b_denominator
# 更新参数
self.A=newA
self.B=newB
self.pi=newPi
#终止阀值
if np.max(abs(self.pi-newPi))预测问题
根据观测序列和模型,求最可能的状态序列
近似算法
最大化 t t t时刻状态为 s i s_i si的概率
γ t ( i ) = α t ( i ) β t ( i ) p ( x ∣ λ ) = α t ( i ) β t ( i ) ∑ j = 1 N α t ( j ) β t ( j ) \gamma_t(i)=\frac{ \alpha_t(i)\beta_t(i)}{p(\mathbf{x}|\lambda)}=\frac{ \alpha_t(i)\beta_t(i)}{\sum_{j=1}^{N}\alpha_t(j)\beta_t(j)} γt(i)=p(x∣λ)αt(i)βt(i)=∑j=1Nαt(j)βt(j)αt(i)βt(i)
得到的状态序列为最可能的状态序列
这种方法计算简单,但是不能保证预测的状态序列整体是最有可能的状态序列,存在实际不发生的转移情况。
维特比算法(Viterbi)
用动态规划求概率最大路径。如果最优路径在时刻 t t t时刻状态为 s i s_i si,那么这一路径从节点 i t i_t it到终点 i T i_T iT的部分路径,必须是最优路径。
-
算法
在时刻 t t t上状态为 s i s_i si的所有单个路径中概率最大值为:
δ t ( i ) = max p ( y t = s i , y t − 1 , . . . . , y 1 , o t , . . . , o 1 ∣ λ ) \delta_t(i)=\max \ p(y_t=s_i,y_{t-1},....,y_1,o_t,...,o_1|\lambda) δt(i)=max p(yt=si,yt−1,....,y1,ot,...,o1∣λ)
则
δ t + 1 ( i ) = max 1 ⩽ j ⩽ N [ δ t ( j ) a j i ] b i ( o t + 1 ) \delta_{t+1}(i)=\max_{1 \leqslant j \leqslant N }\left[\delta_t(j)a_{ji}\right]b_i(o_{t+1}) δt+1(i)=1⩽j⩽Nmax[δt(j)aji]bi(ot+1)
记录每条路线经过的节点,最后的一个时刻,最大概率的路径为最优路径。 -
算法思路
(1)计算 t t t时刻,状态为 s i s_i si的最大概率
(2)根据 t t t时刻的 s i s_i si最大概率,计算 t + 1 t+1 t+1时刻,状态为 s j s_j sj的最大概率 -
代码实现
# viterbi算法
def viterbi(self,x):
T=len(x)
v=[{}]
path={}
for i in range(self.N):
print(self.pi[i])
v[0][i]=self.pi[i]*self.B[i][int(x[0])]
path[i]=[i]
for t in range(1,T):
v.append({})
newpath={}
for i in range(self.N):
prob,state=max([(v[t-1][j]*self.A[j][i]*self.B[i][int(x[t])],j) for j in range(self.N)])
v[t][i]=prob
newpath[i]=path[state]+[i]
path=newpath
prob,state=max([(v[T-1][i],i) for i in range(self.N)])
print(path)
return prob,path[state]
结语
之前对于HMM感觉一知半解,很多东西没有深入,看到HMM用于词性标注,深感自己知识的不通透,故此,整理一遍。
参考:李航《统计学习方法》
周志华 《机器学习》