hive 3.x 特性更改
Apache Hive 3.x 架构介绍
hive 的更新操作一直是大数据仓库头痛的问题,在3.x之前也支持update,但是速度太慢,还需要进行分桶,现在hive 支持全新ACID,并且底层采用TEZ 和内存进行查询,性能是hive2的50倍。生产建议升级到hive3.1.1版本。
了解Apache Hive 3主要的设计更改,例如默认的ACID事务处理和仅支持瘦配置客户端,可以帮助您使用新功能来满足企业数据仓库系统不断增长的需求。
1.执行引擎更改
Apache Tez将MapReduce替换为默认的Hive执行引擎。不再支持MapReduce,并证明了Tez的稳定性。通过有向无环图(DAG)和数据传输原语的表达式,在Tez下执行Hive查询可以提高性能。您提交给Hive的SQL查询执行如下:
Hive编译查询。
Tez执行查询。
YARN为群集中的应用程序分配资源,并为YARN队列中的Hive作业启用授权。
Hive根据表类型更新HDFS或Hive仓库中的数据。
Hive通过JDBC连接返回查询结果。该过程的简化视图如下图所示:
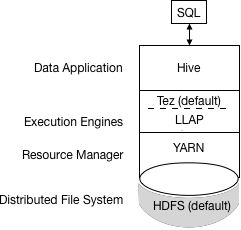
如果旧脚本或应用程序指定MapReduce执行,则会发生异常。您可以设置一个选项以静默忽略MapReduce设置。
大多数用户定义的函数(UDF)不需要在Tez而不是MapReduce上执行更改。
2.设计影响安全性的更改
以下Hive 3体系结构更改提供了更高的安全性:
2.1紧密控制的文件系统和计算机内存资源,取代灵活的边界:确定的边界提高了可预测性。更强大的文件系统控制可提高安
共享文件和YARN容器中的优化工作负载
2.2默认情况下,HDP 3.0 Ambari安装添加了Apache Ranger安全服务。Hive的主要授权模型是Ranger。此模型仅允许Hive访问HDFS。Hive强制执行Ranger中指定的访问控制。此模型提供比其他安全方案更强的安全性以及更灵活的策略管理。
如果您未启用Ranger安全服务或其他安全性,则默认情况下Hive使用基于用户模拟的基于存储的授权(SBA)。
3.HDFS权限更改
在HDP 3.0中,SBA在很大程度上依赖于HDFS访问控制列表(ACL)。ACL是HDFS中权限系统的扩展。HDP 3.0默认打开HDFS中的ACL,为您提供以下优势:
在为多个组和用户提供特定权限时,可以提高灵活性
方便地将权限应用于目录树而不是单个文件
4.交易处理变更
您可以通过利用事务处理中的以下改进来部署新的Hive应用程序类型:
4.1成熟版本的ACID事务处理和LLAP:
ACID表是HDP 3.0中的默认表类型。
默认情况下启用ACID不会导致性能或操作过载。
4.2简化的应用程序开发,具有更强事务保证的操作,以及更简单的SQL命令语义
您不需要在HDP 3.0中存储ACID表,因此维护更容易。
5.其他特性修改
物化视图重写
自动查询缓存
6.高级优化
6.1Hive客户端更改
Hive 3仅支持瘦客户端Beeline,用于从命令行运行查询和Hive管理命令。Beeline使用与HiveServer的JDBC连接来执行所有命令。在HiveServer中进行解析,编译和执行操作。Beeline支持与Hive CLI相同的命令行选项,但有一个例外:Hive Metastore配置更改。
您可以通过使用hive 关键字,命令选项和命令调用Beeline来输入支持的Hive CLI命令。例如,hive -e set。使用Beeline而不是不再支持的胖客户端Hive CLI有几个优点,包括:
您现在只维护JDBC客户端,而不是维护整个Hive代码库。
使用Beeline可以降低启动开销,因为不涉及整个Hive代码库。
瘦客户端体系结构有助于以这些方式保护数据:
会话状态,内部数据结构,密码等驻留在客户端而不是服务器上。
执行查询所需的少量守护进程简化了监视和调试。
HiveServer强制执行您可以使用SET命令更改的白名单和黑名单设置。使用黑名单,您可以限制内存配置以防止HiveServer不稳定。您可以使用不同的白名单和黑名单配置多个HiveServer实例,以建立不同级别的稳定性。
6.2Hive客户端的更改要求您使用grunt命令行来使用Apache Pig。
6.3pache Hive Metastore发生了变化
HiveServer现在使用远程而不是嵌入式Metastore; 因此,Ambari不再使用hive.metastore.uris=' '.您不再key=value在命令行上设置 命令来配置Hive Metastore来启动Metastore。您可以在hive-site.xml中配置属性。Hive目录位于Hive Metastore中,它与早期版本中的RDBMS一样。使用此体系结构,Hive可以利用云部署中的RDBMS资源。
7.Spark目录更改
Spark和Hive现在使用独立的目录来访问相同或不同平台上的SparkSQL或Hive表。Spark创建的表驻留在Spark目录中。Hive创建的表位于Hive目录中。虽然是独立的,但这些表互操作。
您可以使用HiveWarehouseConnector从Spark访问ACID和外部表。
查询批处理和交互式工作负载的执行
下图显示了批处理和交互式工作负载的HDP 3.0查询执行体系结构:
您可以使用JDBC命令行工具(如Beeline)或使用带有BI工具(如Tableau)的JDBC / ODBC驱动程序连接到Hive。客户端与同一HiveServer版本的实例进行通信。您可以为每个实例配置设置文件,以执行批处理或交互式处理。
原文链接:https://smileyboy2009.iteye.com/blog/2433512
官方网站:http://hive.apache.org/downloads.html
hive文档:https://cwiki.apache.org/confluence/display/Hive/Home#Home-GeneralInformationaboutHive
spark官网:http://spark.apache.org/