python 实现MFCC
语音数据:http://www.voiptroubleshooter.com/open_speech/american.html
For this post, I used a 16-bit PCM wav file from [here]
import numpy
import scipy.io.wavfile
from matplotlib import pyplot as plt
from scipy.fftpack import dct
sample_rate,signal=scipy.io.wavfile.read('OSR_us_000_0010_8k.wav')
print(sample_rate,len(signal))
#读取前3.5s 的数据
signal=signal[0:int(3.5*sample_rate)]
plt.plot(signal)
plt.show()
2 预加重
y(t)=x(t)−αx(t−1)
pre_emphasis = 0.97
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
ax2=f1.add_subplot(2,2,2)
ax2.plot(emphasized_signal)
plt.show()
3
预加重后,我们需要将信号分成短时帧。这一步背后的基本原理是信号中的频率随时间而变化,所以在大多数情况下,对整个信号进行傅立叶变换是没有意义的,因为我们会随着时间的推移丢失信号的频率轮廓。为了避免这种情况,我们可以安全地假设信号中的频率在很短的时间内是平稳的。因此,通过在这个短时间帧内进行傅里叶变换,我们可以通过连接相邻帧来获得信号的频率轮廓的良好近似。
语音处理范围内的典型帧大小范围为20毫秒到40毫秒,连续帧之间重叠50%(+/- 10%)。流行设置25毫秒的帧大小,frame_size = 0.025和一10毫秒的步幅(15毫秒重叠), frame_stride = 0.01。
frame_size=0.025
frame_stride=0.1
frame_length,frame_step=frame_size*sample_rate,frame_stride*sample_rate
signal_length=len(emphasized_signal)
frame_length=int(round(frame_length))
frame_step=int(round(frame_step))
num_frames=int(numpy.ceil(float(numpy.abs(signal_length-frame_length))/frame_step))
pad_signal_length=num_frames*frame_step+frame_length
z=numpy.zeros((pad_signal_length-signal_length))
pad_signal=numpy.append(emphasized_signal,z)
indices = numpy.tile(numpy.arange(0, frame_length), (num_frames, 1)) + numpy.tile(numpy.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T
frames = pad_signal[numpy.mat(indices).astype(numpy.int32, copy=False)]
ax3=f1.add_subplot(2,2,3)
ax3.plot(pad_signal)
plt.show()
窗口
在将信号切分为帧后,我们将一个窗口函数(如Hamming窗口)应用于每个帧。汉明窗口具有以下形式:

有几个原因需要对窗框应用窗函数,特别是为了抵消FFT所假设的数据是无限的,并减少频谱泄漏。
frames *= numpy.hamming(frame_length)
# frames *= 0.54 - 0.46 * numpy.cos((2 * numpy.pi * n) /
(frame_length - 1)) # Explicit Implementation **5 傅立叶变换和功率谱
我们现在可以做一个在每个帧上计算频谱,这也称为短时傅立叶变换(STFT),其中N通常是256或512 ,NFFT = 512; 然后使用以下等式计算功率谱(周期图):
6 滤波器组
计算滤波器组的最后一步是nfilt = 40在麦克级上应用三角形滤波器(通常为40个滤波器)来提取功率谱以提取频带。梅尔尺度旨在通过在较低频率处更具辨别性并且在较高频率处较少辨别性来模拟非线性人类耳朵对声音的感知。
Hertz (ff)和 Mel (mm) 之间的公式:

滤波器组中的每个滤波器都是三角形的,在中心频率处响应为1,并朝着0线性减小,直至达到响应为0的两个相邻滤波器的中心频率,如下图所示:


low_freq_mel = 0
#将频率转换为Mel
nfilt = 40
high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700))
mel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # Equally spaced in Mel scale
hz_points = (700 * (10**(mel_points / 2595) - 1)) # Convert Mel to Hz
bin = numpy.floor((NFFT + 1) * hz_points / sample_rate)
fbank = numpy.zeros((nfilt, int(numpy.floor(NFFT / 2 + 1))))
for m in range(1, nfilt + 1):
f_m_minus = int(bin[m - 1]) # left
f_m = int(bin[m]) # center
f_m_plus = int(bin[m + 1]) # right
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])
filter_banks = numpy.dot(pow_frames, fbank.T)
filter_banks = numpy.where(filter_banks == 0, numpy.finfo(float).eps, filter_banks) # Numerical Stability
filter_banks = 20 * numpy.log10(filter_banks) # dB
7 梅尔频率倒谱系数(MFCC)
事实证明,前一步计算出的滤波器组系数高度相关,这在某些机器学习算法中可能存在问题。因此,我们可以应用离散余弦变换(DCT)去相关滤波器组系数并产生滤波器组的压缩表示。通常,对于自动语音识别(ASR),所得到的倒谱系数2-13被保留,其余的被丢弃; num_ceps = 12。丢弃其他系数的原因是它们表示滤波器组系数的快速变化,并且这些细节不会有助于自动语音识别(ASR)。
num_ceps = 12
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1 : (num_ceps + 1)]可以将正弦升降1应用于MFCC以降低已被声称在噪声信号中改善语音识别的较高MFCC
(nframes, ncoeff) = mfcc.shape
n = numpy.arange(ncoeff)
cep_lifter =22
lift = 1 + (cep_lifter / 2) * numpy.sin(numpy.pi * n / cep_lifter)
mfcc *= lift #*
7 平均标准化
如前所述,为了平衡频谱并改善信噪比(SNR),我们可以简单地从所有帧中减去每个系数的平均值。
平均归一化滤波器组:
filter_banks -= (numpy.mean(filter_banks, axis=0) + 1e-8)
plt.imshow(numpy.flipud(filter_banks.T), cmap=plt.cm.jet, aspect=0.2, extent=[0,filter_banks.shape[1],0,filter_banks.shape[0]]) #画热力图
plt.show()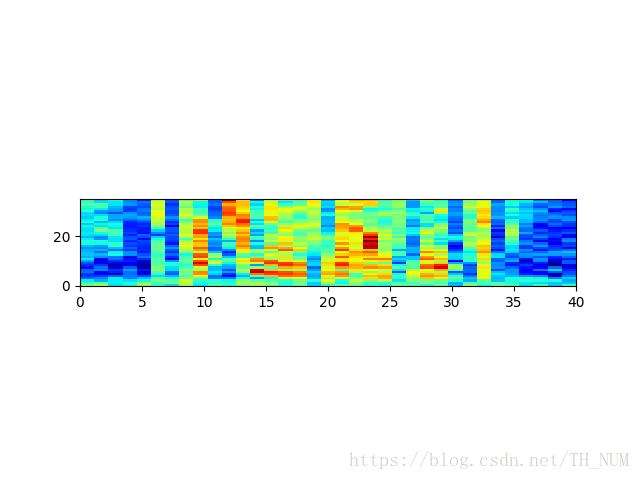
对于MFCC也是如此:
平均归一化MFCC:
mfcc -= (numpy.mean(mfcc, axis=0) + 1e-8)
plt.imshow(numpy.flipud(mfcc.T), cmap=plt.cm.jet, aspect=0.2, extent=[0,mfcc.shape[0],0,mfcc.shape[1]])#热力图
plt.show()

完整代码:
import numpy
import scipy.io.wavfile
from matplotlib import pyplot as plt
from scipy.fftpack import dct
sample_rate,signal=scipy.io.wavfile.read('OSR_us_000_0010_8k.wav')
print(sample_rate,len(signal))
#读取前3.5s 的数据
signal=signal[0:int(3.5*sample_rate)]
print(signal)
#预先处理
pre_emphasis = 0.97
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
frame_size=0.025
frame_stride=0.1
frame_length,frame_step=frame_size*sample_rate,frame_stride*sample_rate
signal_length=len(emphasized_signal)
frame_length=int(round(frame_length))
frame_step=int(round(frame_step))
num_frames=int(numpy.ceil(float(numpy.abs(signal_length-frame_length))/frame_step))
pad_signal_length=num_frames*frame_step+frame_length
z=numpy.zeros((pad_signal_length-signal_length))
pad_signal=numpy.append(emphasized_signal,z)
indices = numpy.tile(numpy.arange(0, frame_length), (num_frames, 1)) + numpy.tile(numpy.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T
frames = pad_signal[numpy.mat(indices).astype(numpy.int32, copy=False)]
#加上汉明窗
frames *= numpy.hamming(frame_length)
# frames *= 0.54 - 0.46 * numpy.cos((2 * numpy.pi * n) / (frame_length - 1)) # Explicit Implementation **
#傅立叶变换和功率谱
NFFT = 512
mag_frames = numpy.absolute(numpy.fft.rfft(frames, NFFT)) # Magnitude of the FFT
#print(mag_frames.shape)
pow_frames = ((1.0 / NFFT) * ((mag_frames) ** 2)) # Power Spectrum
low_freq_mel = 0
#将频率转换为Mel
nfilt = 40
high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700))
mel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # Equally spaced in Mel scale
hz_points = (700 * (10**(mel_points / 2595) - 1)) # Convert Mel to Hz
bin = numpy.floor((NFFT + 1) * hz_points / sample_rate)
fbank = numpy.zeros((nfilt, int(numpy.floor(NFFT / 2 + 1))))
for m in range(1, nfilt + 1):
f_m_minus = int(bin[m - 1]) # left
f_m = int(bin[m]) # center
f_m_plus = int(bin[m + 1]) # right
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])
filter_banks = numpy.dot(pow_frames, fbank.T)
filter_banks = numpy.where(filter_banks == 0, numpy.finfo(float).eps, filter_banks) # Numerical Stability
filter_banks = 20 * numpy.log10(filter_banks) # dB
num_ceps = 12
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1 : (num_ceps + 1)]
(nframes, ncoeff) = mfcc.shape
n = numpy.arange(ncoeff)
cep_lifter =22
lift = 1 + (cep_lifter / 2) * numpy.sin(numpy.pi * n / cep_lifter)
mfcc *= lift #*
#filter_banks -= (numpy.mean(filter_banks, axis=0) + 1e-8)
mfcc -= (numpy.mean(mfcc, axis=0) + 1e-8)
print(mfcc.shape)
plt.plot(filter_banks)
plt.show()