机器学习教程 二.在股票上的回归预测
这一篇算是实战篇,如果有对里面的步骤或者代码不是很明白,不用担心我们现在要做是知道机器学习的整个流程,心有余力可以查查资料,我会在后面一篇详细解释回归算法,下面我们将对股票价格利用线性回归和支持向量机两种算法构建我们的模型来预测。我们这篇博客将要学到内容包括:
1,数据的预处理
2,交叉验证
3,构建我们的模型
4,训练我们的模型
5,完成我们的预测
6,n_jobs的作用和如何选择我们的kernel
上一篇教程我们代码如下
import quandl
import pandas as pd
import pandas as pd
df = quandl.get("WIKI/GOOGL")
df = df[['Adj. Open', 'Adj. High', 'Adj. Low', 'Adj. Close', 'Adj. Volume']]
df['HL_PCT'] = (df['Adj. High'] - df['Adj. Low']) / df['Adj. Close'] * 100.0
df['PCT_change'] = (df['Adj. Close'] - df['Adj. Open']) / df['Adj. Open'] * 100.0
df = df[['Adj. Close', 'HL_PCT', 'PCT_change', 'Adj. Volume']]
# print(df.head())
我们把数据准备好了, 现在我们主角即将登场。首先导入相应库:
import quandl, math
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
import numpy as np
import pandas as pd
from sklearn import preprocessing, cross_validation, svm
from sklearn.linear_model import LinearRegression
接下来,我们将会更多地讨论如何preprocessing(预处理)和cross_ alidation(交叉验证),preprocessing是在机器学习训练之前进行数据清理/数据转换的步骤,在测试阶段使用cross_ alidation(交叉验证)。最后,我们还导入了LinearRegression(线性回归算法)和svm(支持向量机),我们将使用它们作为机器学习算法来预测结果。现在,我们得到了我们认为有用的数据。那么实际机器学习是如何工作的?在有监督学习的情况下,得有特征和标签。特征是描述性的属性,而标签是我们预测的目标。在我们的案例中,我们的特征实际上是:Adj. Close(当前价格),HL_PCT(价格变化率),以及PCT_change(收盘波动率)而我们的标签显然是未来股票的价格。 我们接着做如下操作:
forecast_col = 'Adj. Close'
df.fillna(value=-99999, inplace=True)
forecast_out = int(math.ceil(0.01 * len(df)))
在这里,我们定义了将要的预测列(forecast_col ),然后用- 99999填充缺失数据。我们不能只通过一个非数字数据到一个机器学习分类器,我们必须处理它。一个流行的选择是用- 99999代替丢失的数据。对于许多机器学习分类器,这将被视为一个异常值。我们还可以删除包含缺失数据的所有特性/标签集,但是您可能会丢失很多重要的数据,我们可以观察我们数据集,其中大多数行包含一些缺失的信息。所以我们不一定要放弃所有这些有趣的数据,而且如果我们的样本数据也有缺失, 所以需要合理处理缺失值,并在与训练集有相似特征的测试集上做出预测,我们还定义了forecast_out,它表示我们想要预测整个数据集的1%(比如100天历史股票数据,我们通过前99天,预测第100天的股票结果)接下来我需要对添加如下代码:
df['label'] = df[forecast_col].shift(-forecast_out)
我们将从dataframe中删除任何仍为NaN(非数字)的信息:
df.dropna(inplace=True)
#下面是一个典型的标准,机器学习在代码中定义X(大写X),作为特征,y(小写y)作为对应于特征的标签。因此,我们可以这样定义我们的特性和标签:
X = np.array(df.drop(['label'], 1))
我们可以用上面的代码继续进行训练和测试,但是我们还要做一些预处理。一般来说,您希望您的机器学习的特性在- 1到1之间。它可能没有什么大作用,但它通常加速处理和提高预测的准确率。很幸运这个功能它被包含在scikit- learn的预处理模块中,您可以调用preprocessing.scale来缩放到你的X变量:
X = preprocessing.scale(X)
接下来我们可以创建y标签:
y = np.array(df['label'])
接下来我们要做是训练与测试,我们要拿75%的数据,用这个来训练机器学习分类器。然后将剩下的25%的数据进行测试,并对分类器进行测试。因此,我们可以根据25%的数据验证我们的模型,这样就可以让我们的模型更可靠,是不是很有道理?那么我们怎么合理切分这些数据呢?不要急,没错我们有我们的sklearn大法,里面又给我们写好了cross_validation 功能:
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.25)
这里返回的X_train(训练集的特征), X_test(测试集的特征), y_train(训练集的标签), y_test(测试集的标签),现在,我们准备定义分类器。一般来说,通过scikit- learn可以得到许多分类器,甚至还有一些专门用于回归的分类器。在本例中我们使用scikitt - learn的svm包中的支持向量回归:
clf = svm.SVR()
初次构建SVM分类器,我们使用默认的参数,接下来我们开始训练分类器了,我们将使用到sklearn中fit()这个函数:
clf.fit(X_train, y_train)
模型训练好了,我们可以预测它了:
confidence = clf.score(X_test, y_test)
print(confidence)
预测结果如下:
这里,我们可以看到准确率大约是80%。让我们尝试另一个分类器,这一次使用sklearn的LinearRegression(线性回归):
clf=LinearRegression()
clf.fit(X_train, y_train)
模型训练好了,我们可以预测它了:
confidence = clf.score(X_test, y_test)
print(confidence)
预测结果如下:

哇!提高不少啊!是不是很惊讶?那么我们实际生活中选择哪种算法呢?如果你问那些经常使用机器学习的人,他们的答案永远只有一个不断试错,不断调参。当然您可以尝试一些算法,并简单地使用最有效的算法。赶快去尝试别的算法吧!哈哈。。。
接下来给大家补充点小知识,有些算法必须是线性运行的,有些则不是,这就意味着有些算法可以利用多线程提高运行速率。那么怎么区分哪些算法可以调高多线程呢?其实很简单,我们可以看算法的官方文档,如果它有n_jobs,那么您就有一个可以为高性能而线程化的算法。如果不是这样,真不走运!因此,如果您正在处理大量的数据,或者处理中等数据,但是需要速度非常高,那么您就需要一些线程。我们来检查两种算法。前往sklearn.svm的文档,发现它并没n_jobs,所以这个算法是没有多线程的。正如您所看到的,在我们的小数据上,它几乎没有什么差别,但是,即使只说20mb的数据,它也会产生巨大的差异。接下来,我们来看看线性回归算法。你看到这里有n_jobs吗?确实!这里,你可以精确地指定你想要多少个线程。如果输入- 1的值,那么算法将使用所有可用的线程。
clf = LinearRegression(n_jobs=-1)
是不是很有趣,当我让你做这样一件非常罕见的事情(查看文档)时,让我提请你注意这个事实,仅仅因为机器学习算法使用默认参数,并不意味着你可以忽略它们。
我们再来看另一个问题,svm.SVR()中有一个参数那就是kernel,这它到底是什么?将(kernel)内核想象成与数据的转换,换句话说kernel简化你的数据。这使得处理的速度更快。 在svm的情况下。默认的SVR是rbf,它是一种内核。你还有其他的选择。检查文档,有“linear”、“poly”、“rbf”、“sigmoid”、“precomputed”等。
# 同样,就像建议尝试不同的ML算法可以尝试修改内核内核。代码如下:
接下来给大家补充点小知识,有些算法必须是线性运行的,有些则不是,这就意味着有些算法可以利用多线程提高运行速率。那么怎么区分哪些算法可以调高多线程呢?其实很简单,我们可以看算法的官方文档,如果它有n_jobs,那么您就有一个可以为高性能而线程化的算法。如果不是这样,真不走运!因此,如果您正在处理大量的数据,或者处理中等数据,但是需要速度非常高,那么您就需要一些线程。我们来检查两种算法。前往sklearn.svm的文档,发现它并没n_jobs,所以这个算法是没有多线程的。正如您所看到的,在我们的小数据上,它几乎没有什么差别,但是,即使只说20mb的数据,它也会产生巨大的差异。接下来,我们来看看线性回归算法。你看到这里有n_jobs吗?确实!这里,你可以精确地指定你想要多少个线程。如果输入- 1的值,那么算法将使用所有可用的线程。
clf = LinearRegression(n_jobs=-1)
是不是很有趣,当我让你做这样一件非常罕见的事情(查看文档)时,让我提请你注意这个事实,仅仅因为机器学习算法使用默认参数,并不意味着你可以忽略它们。
我们再来看另一个问题,svm.SVR()中有一个参数那就是kernel,这它到底是什么?将(kernel)内核想象成与数据的转换,换句话说kernel简化你的数据。这使得处理的速度更快。 在svm的情况下。默认的SVR是rbf,它是一种内核。你还有其他的选择。检查文档,有“linear”、“poly”、“rbf”、“sigmoid”、“precomputed”等。
# 同样,就像建议尝试不同的ML算法可以尝试修改内核内核。代码如下:
for k in ['linear','poly','rbf','sigmoid']:
clf = svm.SVR(kernel=k)
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print(k,confidence)
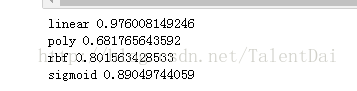
正如我们所看到的,linear的内核是最好的我们已经测试了分类器。接下来,我们将使用我们的分类器来为我们做一些预测!代码如下:
X = preprocessing.scale(X)
X = np.array(df.drop(['label'], 1))
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])[:-forecast_out]
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = LinearRegression()
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
# print(confide nce)
X = np.array(df.drop(['label'], 1))
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
df.dropna(inplace=True)
y = np.array(df['label'])[:-forecast_out]
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
clf = LinearRegression()
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
# print(confide nce)
首先我们取所有的数据,先处理它,然后再把它分解。我们的 X_lately变量包含最近的特性,我们将对它进行预测。
正如您应该看到的那样,定义一个分类器、训练和测试都非常简单。预测也非常简单:
正如您应该看到的那样,定义一个分类器、训练和测试都非常简单。预测也非常简单:
forecast_set = clf.predict(X_lately)
print(forecast_set)
我们可以看到预测的结果如下:

我们已经完成了对股票价格预测,接下来的文章我会对回归算法做进一步分析。。如果发现错误或者不当的地方,欢迎指正。