《C++ Primer》学习笔记(二):变量和基本类型
专栏C++学习笔记
《C++ Primer》学习笔记/习题答案 总目录
- https://blog.csdn.net/TeFuirnever/article/details/100700212
——————————————————————————————————————————————————————
- 《C++ Primer》习题参考答案:第2章 - 变量和基本类型
文章目录
- 专栏C++学习笔记
- 变量和基本类型
- 1、基本内置类型
- 1)算数类型
- 2)类型转换
- 3)字面值常量
- 1_整型字面值
- 2_浮点型字面值
- 3_字符字面值和字符串字面值
- 4_非打印字符的转义序列
- 5_多行字面值
- 6_特殊情况
- 2、变量
- 1)变量定义
- 2)变量声明和定义的关系
- 3)变量名
- 4)名字的作用域
- 3、复合类型
- 1)引用
- 2)指针(难点)
- 3)理解复合类型的声明
- 4、const限定符
- 1)const的引用
- 2)指针和const
- 3)顶层const
- 4)constexpr和常量表达式
- 5、处理类型
- 1)类型别名
- 2)auto类型说明符
- 3)decltype类型指示符
- 6、自定义数据结构
- 参考文章
- 补充
变量和基本类型
类型是所有程序的基础。它告诉了我们,数据代表什么意思以及可以对数据执行哪些操作。那么C++ 都有哪些类型呢?
C++ 语言定义了几种基本类型:字符型、整型、浮点型 等;除此之外,还提供了可用于 自定义数据类型 的机制,标准库正是利用这些机制定义了许多更复杂的类型,比如 可变长字符串 string、vector 等;最后,还能修改已有的类型以形成 复合类型。
类型确定了数据和操作在程序中的意义。在第一章(《C++ Primer》学习笔记(一):快速入门)已经看到,如下的语句 i = i + j ; i =i +j; i=i+j; 有不同的含义,具体含义取决于 i 和 j 的类型。如果 i 和 j 都是整型,则这条语句表示一般的算术“+”运算;如果 i 和 j 都是 Sales_item 对象,则这条语句是将这两个对象的组成成分分别加起来。
C++ 中对类型的支持是非常广泛的:语言本身定义了一组基本类型和修改已有类型的方法,还提供了一组特征用于自定义类型。详细的看下面:
1、基本内置类型
1)算数类型
C++ 定义了一组表示 整数、浮点数、单个字符 和 布尔值 的算术类型,另外还定义了一种称为 void 的特殊类型。
算术类型的存储空间依机器而定。这里的存储空间是指用来表示该类型的 位(bit)数。C++ 标准规定了每个算术类型的最小存储空间,但它并不阻止编译器使用更大的存储空间。
下表列出了内置算术类型及其对应的最小存储空间。
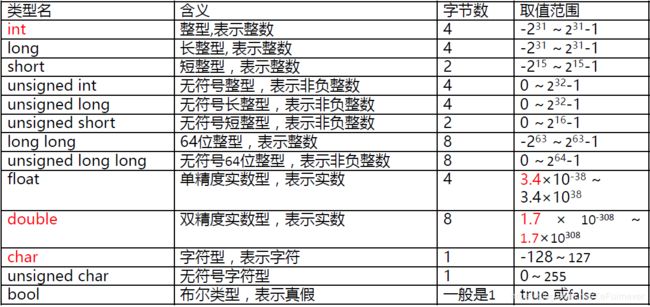
整数、字符和布尔值合称为 整型。
字符类型有两种:char 和 wchar_t。char 类型通常是单个机器字节(byte),可以存放机器基本字符集中任意字符对应的数值。而 wchar_t 可以存放机器最大扩展字符集中的任意一个字符。
bool 类型的取值是真值 true 或假值 false。0 值算术类型代表 false,任何非 0 的值都代表 true。
在整型类型大小方面,C++ 规定 short ≤ int ≤ long ≤ long long(long long 是C++11定义的类型)。
整型可以是 带符号的(signed),也可以是 无符号的(unsigned)。int、short 和 long 都默认为带符号型。无符号型必须指定 unsigned,比如 unsigned long。unsigned int 类型可以简写为 unsigned。
字符型分为char、signed char 和 unsigned char 三种,但是表现形式只有带符号和无符号两种。类型 char 和 signed char 并不一样, char的具体形式由编译器(compiler)决定。
浮点型可表示 单精度(single-precision)、双精度(double-precision) 和 扩展精度(extended-precision) 值,分别对应 float、double 和 long double 类型。
void 类型没有对应的值,仅用在有限的一些情况下,通常用作无返回值函数的返回类型。
如何选择算数类型:
- 当明确知晓数值不可能为负时,应该使用无符号类型。
- 使用
int执行整数运算,不易出错,如果数值超过了int的表示范围,应该使用long long类型。 - 在算数表达式中不要使用
char和bool类型。如果需要使用一个不大的整数,应该明确指定它的类型是signed char还是unsigned char。 - 执行浮点数运算时建议使用
double类型,基本上不会有错。
2)类型转换
进行类型转换时,类型所能表示的值的范围决定了转换的过程。
- 把非布尔类型的算术值赋给布尔类型时,初始值为0则结果为
false,否则结果为true。 - 把布尔值赋给非布尔类型时,初始值为
false则结果为0,初始值为true则结果为1。 - 把浮点数赋给整数类型时,进行近似处理,结果值仅保留浮点数中的整数部分。
- 把整数值赋给浮点类型时,小数部分记为0。如果该整数所占的空间超过了浮点类型的容量,精度可能有损失。
- 赋给无符号类型一个超出它表示范围的值时,结果是初始值对无符号类型表示数值总数(8比特大小的
unsigned char能表示的数值总数是256)取模后的余数。 - 赋给带符号类型一个超出它表示范围的值时,结果是 未定义的(undefined)。
避免无法预知和依赖于实现环境的行为。
无符号数不会小于0这一事实,关系到循环的写法。
for (unsigned u = 10; u >= 0; --u) // 错误:永远不能小于0;条件总是成功的
std::cout << u << std::endl;
预期是0的时候停止。
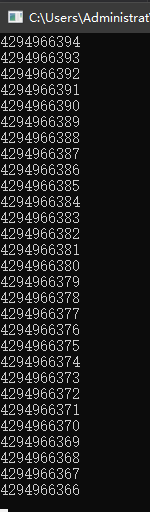
然而并没有,这是因为当 u 等于0时,–u 的结果将会是4294967295( 2 32 − 1 2^{32} - 1 232−1),循环仍然会继续。
一种解决办法是用 while 语句来代替 for 语句,前者可以在输出变量前先减去1,同时还是先判断条件再输出结果。
unsigned u = 11; //在要打印的第一个元素之后开始循环
while (u > 0)
{
--u; //首先递减,以便最后一次迭代将打印0
std::cout << u << std::endl;
}
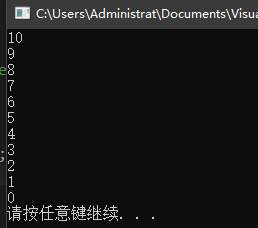
注意:不要混用带符号类型和无符号类型。
3)字面值常量
以 0 开头的整数代表 八进制(octal)数,以 0x 或 0X 开头的整数代表 十六进制(hexadecimal)数。在C++14中,0b 或 0B 开头的整数代表 二进制(binary)数。
1_整型字面值
整型字面值具体的数据类型由它的值和符号决定,默认为 int 或 long 类型。
- 在数值后面加
L或者l指定常量为long类型。(定义长整型时,应该使用大写字母 L。小写字母 l 很容易和数值 1 混淆。) - 在数值后面加
U或u定义unsigned类型。 - 同时加
L和U就能够得到unsigned long类型的字面值常量。
128u /* unsigned */
024UL /* unsigned long*/
1L /* long */
8Lu /* unsigned long*/
C++14 新增了单引号 ' 形式的数字分隔符。数字分隔符不会影响数字的值,但可以通过分隔符将数字分组,使数值读写更容易。
// 按照书写形式,每3位分为一组
std::cout << 0B1'101; // 输出"13"
std::cout << 1'100'000; // 输出"1100000"
2_浮点型字面值
浮点型字面值默认是一个 double。
- 在数值的后面加上 F 或 f 表示单精度。
3.14159F
.001f
12.345L
0.
3.14159E0f
1E-3F
1.2345E1L
0e0
3_字符字面值和字符串字面值
由单引号括起来的一个字符称为 char 型字面值,双引号括起来的零个或多个字符称为字符串字面值。
- 可打印的字符型字面值通常用一对单引号来定义
char类型,在字符字面值前加L就能够得到wchar_t类型的宽字符字面值。
std::cout << 'a'
std::cout << '2'
std::cout << ','
std::cout << ' ' // blank
std::cout << L'a'
- 字符串字面值的类型是由常量字符构成的数组(array)。为了兼容 C 语言,C++ 中所有的字符串字面值都由编译器自动在末尾添加一个空字符
'\0',因此字符串字面值的实际长度要比它的内容多一位。
std::cout << "Hello World!" // 文字简单字符串
std::cout << "" // 文本空字符串
std::cout << "\nCC\toptions\tfile.[cC]\n" // 文字字符串 using newlines and tabs
4_非打印字符的转义序列
非打印字符的转义序列,即不可显示的字符,都以反斜线符号开始。

\7 (bell)
\12 (newline)
\40 (blank)
\0 (null)
\062 ('2')
\115 ('M')

std::cout << '\n'; // prints a newline
std::cout << "\tHi!\n"; // prints a tab 跟着是 "Hi!" and a newline
泛化转义序列的形式是 \x 后紧跟1个或多个十六进制数字,或者\后紧跟1个、2个或3个八进制数字,其中数字部分表示字符对应的数值。如果\后面跟着的八进制数字超过3个,则只有前3个数字与\构成转义序列。相反,\x要用到后面跟着的所有数字。
std::cout << "Hi \x4dO\115!\n"; // prints Hi MOM! 后面是换行符
std::cout << '\115' << '\n'; // prints M 后跟着是换行符
5_多行字面值
处理长字符串有一个更基本的(但不常使用)方法,这个方法依赖于很少使用的程序格式化特性:在一行的末尾加一反斜线符号可将此行和下一行当作同一行处理。有一些地方不能插入空格,其中之一是在单词中间。特别是不能在单词中间断开一行,但可以通过使用反斜线符号巧妙实现:
// ok: 换行符前的 \ 会忽略换行符
std::cou\
t << "Hi" << st\
d::endl;
等价于
std::cout << "Hi" << std::endl;
可以使用这个特性来编写长字符串字面值:
// 多行字符串文本
std::cout << "a multi-line \
string literal \
using a backslash"
<< std::endl;
return 0;
}
注意:反斜线符号必须是该行的尾字符——不允许有注释或空格符。同样,后继行行首的任何空格和制表符都是字符串字面值的一部分。正因如此,长字符串字面值的后继行才不会有正常的缩进。
6_特殊情况
如果连接字符串字面值和宽字符串字面值,将会出现什么结果呢?
例如:
// 连接普通字符串字面值和宽字符串字面值的未定义类型
std::cout << "multi-line " L"literal " << std::endl;
其结果是未定义的,也就是说,连接不同类型的行为标准没有定义。这个程序可能会执行,也可能会崩溃或者产生没有用的值,而且在不同的编译器下程序的动作可能不同。
VS2013运行结果如下:

2、变量
1)变量定义
变量定义的基本形式:类型说明符(type specifier) 后紧跟由一个或多个变量名组成的列表,其中变量名以 逗号 分隔,最后以 分号 结束。
下列语句定义了 5 个变量:
int units_sold;
double sales_price, avg_price;
std::string title;
Sales_item curr_book;
每个定义都是以 类型说明符 开始,后面紧跟着以逗号分开的含有一个或多个说明符的列表,分号结束定义。类型说明符指定与对象相关联的类型:int 、double、std::string 和 Sales_item 都是类型名。
其中 int 和 double 是内置类型,std::string 是标准库定义的类型,Sales_item 是在类中使用的类型。类型决定了分配给变量的存储空间的大小和可以在其上执行的操作。
多个变量可以定义在同一条语句中:
double salary, wage; // 定义两个 double 类型的变量
int month, day, year; // 定义三个 int 类型的变量
std::string address; // 定义一个 std::string 的变量
定义时可以为一个或多个变量赋初始值,即 初始化(initialization)。
初始化不等于 赋值(assignment)。
注意:初始化的含义是创建变量时赋予其一个初始值,而赋值的含义是把对象的当前值擦除,再用一个新值来替代。
用花括号初始化变量称为 列表初始化(list initialization)。当用于内置类型的变量时,如果使用了列表初始化并且初始值存在丢失信息的风险,则编译器会报错。
long double ld = 3.1415926536;
int a{ld}, b = {ld}; // error: 转换未执行,因为存在丢失信息的危险
int c(ld), d = ld; // ok: 转换执行,且确实丢失了部分值
如果定义变量时未指定初值,则变量被 默认初始化(default initialized)。对于内置类型,定义于任何函数体之外的变量被初始化为0,函数体内部的变量将不被 初始化(uninitialized)。定义于函数体内的内置类型对象如果没有初始化,则其值未定义,使用该类值是一种错误的编程行为且很难调试。类的对象如果没有显式初始化,则其值由类确定。
建议初始化每一个内置类型的变量。
2)变量声明和定义的关系
声明(declaration) 使得名字为程序所知。一个文件如果想使用其他地方定义的名字,则必须先包含对那个名字的声明。
定义(definition) 负责创建与名字相关联的实体。
如果想声明一个变量而不定义它,就在变量名前添加关键字 extern,并且不要显式地初始化变量。
extern int i; // 声明但不定义 i
int j; // 声明并定义 j
extern语句如果包含了初始值就不再是声明了,而变成了定义。
变量能且只能被定义一次,但是可以被声明多次。
如果要在多个文件中使用同一个变量,就必须将声明和定义分开。此时变量的定义必须出现且只能出现在一个文件中,其他使用该变量的文件必须对其进行声明,但绝对不能重复定义。
3)变量名
变量命名有许多约定俗成的规范,下面的这些规范能有效提高程序的可读性:
-
C++ 的变量名,即标识符,由字母、数字和下划线组成,其中必须以字母或下划线开头;
-
变量名一般用小写字母;
-
用户自定义的类名一般以大写字母开头;
-
标识符的长度没有限制,但是对大小写字母敏感。
// 声明四个不同的int变量
int somename, someName, SomeName, SOMENAME;
- 语言本身并没有限制变量名的长度,但考虑到将会阅读和/或修改我们的代码的其他人,变量名不应太长。
例如:gosh_this_is_an_impossibly_long_name_to_type 就是一个糟糕的标识符名。
- C++ 为标准库保留了一些名字。也就是关键字。关键字不能用作程序的标识符。
下表列出了 C++ 所有的63个关键字:
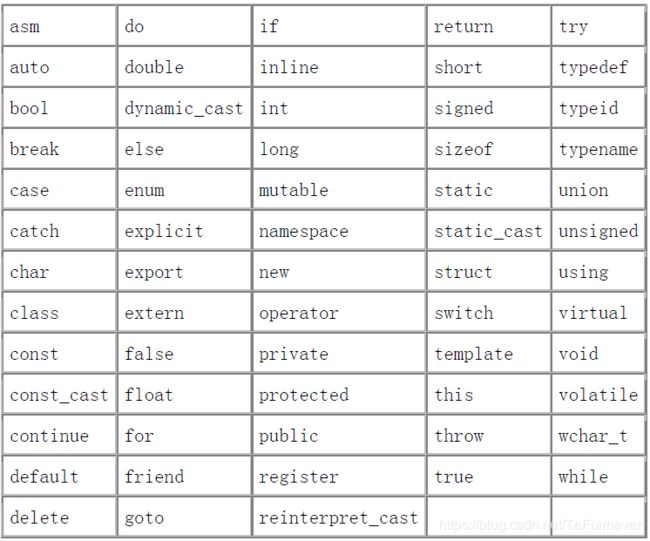
用户自定义的标识符不能连续出现两个下划线,也不能以下划线紧连大写字母开头。此外,定义在函数体外的标识符不能以下划线开头。
变量命名有许多被普遍接受的习惯,遵循这些习惯可以提高程序的可读性。
- 变量名一般用小写字母。例如,通常会写成 index,而不写成 Index 或 INDEX。
- 标识符应使用能帮助记忆的名字,也就是说,能够提示其在程序中的用法的名字,如 on_loan 或 salary。
- 包含多个词的标识符书写为在每个词之间添加一个下划线,或者每个内嵌的词的第一个字母都大写。例如通常会写成 student_loan 或 studentLoan,而不写成 studentloan。
命名习惯最重要的是保持一致。
4)名字的作用域
定义在函数体之外的名字拥有 全局作用域(global scope)。声明之后,该名字在整个程序范围内都可使用。最好在第一次使用变量时再去定义它。这样做更容易找到变量的定义位置,并且也可以赋给它一个比较合理的初始值。
作用域中一旦声明了某个名字,在它所嵌套着的所有作用域中都能访问该名字。同时,允许在内层作用域中重新定义外层作用域已有的名字,此时内层作用域中新定义的名字将屏蔽外层作用域的名字。
可以用作用域操作符 :: 来覆盖默认的作用域规则。因为全局作用域本身并没有名字,所以当作用域操作符的左侧为空时,会向全局作用域发出请求获取作用域操作符右侧名字对应的变量。
#include 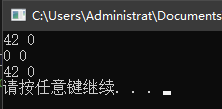
如果函数有可能用到某个全局变量,则不宜再定义一个同名的局部变量。
3、复合类型
1)引用
引用为对象起了另外一个名字,是一种复合类型,通过将声明符写成 &d 的形式来定义引用类型。不能定义引用类型的引用,但可以定义任何其他类型的引用。
int ival = 1024;
int &refVal = ival; // refval是指ival
int &refVal2; // error: 必须初始化引用
定义引用时,程序把引用和它的初始值绑定(bind)在一起,而不是将初始值拷贝给引用。一旦初始化完成,将无法再令引用重新绑定到另一个对象,因此 引用必须初始化。
引用不是对象,它只是为一个已经存在的对象所起的另外一个名字。
声明语句中引用的类型实际上被用于指定它所绑定的对象类型。大部分情况下,引用的类型要和与之绑定的对象严格匹配。
引用只能绑定在对象上,不能与字面值或某个表达式的计算结果绑定在一起。
可以在一个类型定义行中定义多个引用。必须在每个引用标识符前添加 & 符号:
int i = 1024, i2 = 2048;
int &r = i, r2 = i2; // r是引用,r2是int
int i3 = 1024, &ri = i3; // 定义一个对象和一个引用
int &r3 = i3, &r4 = i2; // 定义两个引用
2)指针(难点)
与引用类似,指针也是一种复合类型,也实现了对其他对象的间接访问。但是指针与引用相比又有很多不同点:
- 指针本身就是一个对象,允许对指针赋值和拷贝,而且在生命周期内它可以先后指向不同的对象。
- 指针无须在定义时赋初值。和其他内置类型一样,在块作用域内定义的指针如果没有被初始化,也将拥有一个不确定的值。
通过将声明符写成 *d 的形式来定义指针类型,其中 d 是变量名称。如果在一条语句中定义了多个指针变量,则每个量前都必须有符号 *。
int *ip1, *ip2; // ip1和ip2都是指向int对象的指针
double dp, *dp2; // dp2是指向double对象的指针;dp是double对象
指针存放某个对象的地址,要想获取对象的地址,需要使用取地址符 &。
int ival = 42;
int *p = &ival; // p保存ival的地址;p是指向ival的指针
因为引用不是对象,没有实际地址,所以不能定义指向引用的指针。
声明语句中指针的类型实际上被用于指定它所指向的对象类型。大部分情况下,指针的类型要和它指向的对象严格匹配。
指针的值(即地址)应属于下列状态之一:
- 指向一个对象。
- 指向紧邻对象所占空间的下一个位置。
- 空指针,即指针没有指向任何对象。
- 无效指针,即上述情况之外的其他值。
试图拷贝或以其他方式访问无效指针的值都会引发错误。编译器并不负责检查此类错误,这一点和试图使用未经初始化的变量是一样的,访问无效指针的后果无法预计,因此需要程序员自己清楚任意给定的指针是否有效。
如果指针指向一个对象,可以使用 解引用(dereference)符 * 来访问该对象。
int ival = 42;
int *p = &ival; // p存放着变量ival的地址,或者说p是指向变量ival的指针
cout << *p; // 由符号*得到指针p所指的对象,输出42
给解引用的结果赋值,就是给指针所指向的对象赋值。
*p = 0; // 由符号*得到指针p所指的对象,即可经由p为变量ival赋值
cout << *p; // 输出0
解引用操作仅适用于那些确实指向了某个对象的有效指针。
空指针(null pointer) 不指向任何对象,在试图使用一个指针前代码可以先检查它是否为空。得到空指针最直接的办法是用字面值 nullptr 来初始化指针。
旧版本程序通常使用 NULL(预处理变量,定义于头文件 cstdlib 中,值为0)给指针赋值,但在C++11中,最好使用 nullptr 初始化空指针。
int *p1 = nullptr; // 等价于 int *p1 = 0;
int *p2 = 0; // 直接将p2初始化为字面常量0
// 需要首先 #include cstdl ib
int *p3 = NULL; // 等价于 int *p3 = 0;
建议初始化所有指针:使用未经初始化的指针是引发运行时错误的一大原因。如果实在不清楚指针应该指向何处, 就把它初始化为 nullptr 或者0。
指针和引用都能提供对其他对象的间接访问,然而在具体实现细节上二者有很大不同,其中最重要的一点就是 引用本身并非一个对象。一旦定义了引用,就无法令其再绑定到另外的对象,之后每次使用这个引用都是访问它最初绑定的那个对象。指针和它存放的地址之间就没有这种限制了。和其他任何变量(只要不是引用) 一样,给指针赋值就是令它存放一个新的地址,从而指向一个新的对象。
int i = 42;
int *pi = 0; // pi被初始化,但没有指向任何对象
int *pi2 = &i; // pi2被初始化,存有i的地址
int *pi3; //如果pi3定义于块内,则pi3的值是无法确定的
pi3 = pi2; // pi3和pi2指向同一个对象i
pi2 = 0; // 现在pi2不指向任何对象了
记住赋值永远改变的是等号左侧的对象。
pi = &ival ; // pi的值被改变,现在pi指向了ival
代码的意思是 pi 赋一个新的值,也就是改变了那个存放在 pi内的地址值。
*pi = 0 ; // iva1的值被改变,指针pi并没有改变
而这一行代码是 *pi(也就是指针 pi 指向的那个对象)发生改变。
记住:记住赋值永远改变的是等号左侧的对象。
void* 是一种特殊的指针类型,可以存放任意对象的地址,但不能直接操作 void* 指针所指的对象。
double obj = 3.14, *pd = &obj;
// 正确:void*能存放任意类型对象的地址
void *pv = &obj; // obj可以是任意类型的对象
pv = pd; // pv可以存放任意类型的指针
3)理解复合类型的声明
变量包括一个 基本数据类型(base type) 和一组 声明符。
// i是一个int型的数,p是一个int型指针,r是一个int型应用
int i = 1024 , *p = &i, &r = i;
修饰只修饰自己,不是这条语句中所有变量。错误案例:
int* p1 , p2; // p1是指向int的指针, p2是int
正确案例:
int *p1, *p2; // p1和p2都是指向int的指针
等价于
int* p1; // p1是指向int的指针
int* p2; // p2是指向int的指针
指向指针的指针(Pointers to Pointers):
int ival = 1024;
int *pi = &ival; // pi指向一个int型的数
int **ppi = π // ppi指向一个int型的指针
关系如下:

指向指针的引用(References to Pointers),引用本身不是一个对象,因此不能定义指向引用的指针。但指针是对象,所以存在对指针的引用:
int i = 42;
int *p; // p是一个int型指针
int *&r = p; // r是一个对指针p的引用
r = &i; // r引用了一个指针,因此给r赋位&i就是令p指向i
*r = 0; // 解引用r得到i,也就是p指向的对象,将i的位改为0
面对一条比较复杂的指针或引用的声明语句时,从右向左阅读有助于弄清它的真实含义。
离变量名最近的符号(此例中是 &r 的符号 &)对变量的类型有最直接的影响,因此 r 是一个引用。声明符的其余部分用以确定 r 引用的类型是什么,此例中的符号 * 说明 r 引用的是一个指针。最后,声明的基本数据类型部分指出 r 引用的是一个 int 指针。
4、const限定符
在变量类型前添加关键字 const 可以创建值不能被改变的对象。const 变量必须被初始化。
const int i = get_size(); // 正确:运行时初始化
const int j = 42; // 正确:编译时初始化
const int k; // 错误:k是一个未经初始化的常量
默认情况下,const 对象被设定成仅在文件内有效。当多个文件中出现了同名的 const 变量时,其实等同于在不同文件中分别定义了独立的变量。
如果想在多个文件间共享 const 对象:
- 若
const对象的值在编译时已经确定,则应该定义在头文件中。其他源文件包含该头文件时,不会产生重复定义错误。 - 若
const对象的值直到运行时才能确定,则应该在头文件中声明,在源文件中定义。此时const变量的声明和定义前都应该添加extern关键字。
// file_1.cc定义并初始化了一个常量,该常量能被其他文件访问
extern const int bufSize = fcn();
// file_1.h头文件
extern const int bufSize; // 与file_1.cc中定义的bufSize是同一个
1)const的引用
把引用绑定在 const 对象上即为 对常量的引用(reference to const)。与普通引用不同的是,对常量的引用不能被用作修改它所绑定的对象。
const int ci = 1024;
const int &r1 = ci; // ok: 引用及其对应的对象都是常量
r1 = 42; // error: r1是对常量的引用
int &r2 = ci; // error: 试图让一个非常量引用指向一个常量对象
大部分情况下,引用的类型要和与之绑定的对象严格匹配。但是有两个例外(第二个例外在第十五章):
第一个例外就是初始化常量引用时,允许用任意表达式作为初始值,只要该表达式的结果能转换成引用的类型即可。
int i = 42;
const int &r1 = i; // 允许将const int&绑定到一个普通int对象上
const int &r2 = 42; // ok: r1是一个常量引用
const int &r3 = r1 * 2; // ok: r3是一个常量引用
int &r4 = r1 * 2; // error: r4是一个普通的非常量引用
2)指针和const
指向常量的指针(pointer to const) 不能用于修改其所指向的对象。常量对象的地址只能使用指向常量的指针来存放,但是指向常量的指针可以指向一个非常量对象。
const double pi = 3.14; // pi是个常量,它的值不能改变
double *ptr = π // error: ptr是一个普通指针
const double *cptr = π // ok: cptr可以指向一个双精度常釜
*cptr = 42; // error: 不能给*cptr赋位
double dval = 3.14; // dval是一个双精度浮点纹,它的值可以改变
cptr = &dval; // ok: 但是不能通过cptr改变dval的值
定义语句中把 * 放在 const 之前用来说明指针本身是一个常量,常量指针(const pointer) 必须初始化,而且一旦初始化完成,指针本身的值(即存放在指针中的那个地址)就不能再改变了:
int errNumb = 0;
int *const curErr = &errNumb; // curErr将一直指向errNumb
const double pi = 3.14159;
const double *const pip = π // pip是一个指向常量对象的常量指针
指针本身是常量并不代表不能通过指针修改其所指向的对象的值,能否这样做完全依赖于其指向对象的类型。
3)顶层const
顶层 const 表示指针本身是个常量,底层 const(low-level const)表示指针所指的对象是一个常量。指针类型既可以是顶层 const 也可以是底层 const。
int i = 0;
int *const p1 = &i; // 不能改变p1的值,这是一个顶层const
const int ci = 42; // 不能改变ci的值,这是一个顶层const
const int *p2 = &ci; // 允许改变p2的值,这是一个底层const
const int *const p3 = p2; // 靠右的const是顶层const,靠左的是底层const
const int &r = ci; // 用于声明引用的const都是底层const
当执行拷贝操作时,常量是顶层 const 还是底层 const 区别明显:
- 顶层
const没有影响。拷贝操作不会改变被拷贝对象的值,因此拷入和拷出的对象是否是常量无关紧要。
i = ci; // ok: 拷贝ci的值,ci是一个顶层const,对此操作无影响
p2 = p3; // ok: p2和p3指向的对象类型相同,p3顶层const的部分不影响
- 底层const的限制不能忽视。拷入和拷出的对象必须具有相同的底层
const资格。或者两个对象的数据类型可以相互转换。一般来说,非常量可以转换成常量,反之则不行。
int *p = p3; // error: p3包含底层const的定义,而p没有
p2 = p3; // ok: p2和p3都是底层const
p2 = &i; // ok: int*能转换成const int*
int &r = ci; // error: 普通的int&不能绑定到int常量上
const int &r2 = i; // ok: const int&可以绑定到一个普通int上
4)constexpr和常量表达式
常量表达式(constant expressions) 指值不会改变并且在编译过程就能得到计算结果的表达式。显然,字面值属于常量表达式,用常量表达式初始化的const对象也是常量表达式。
一个对象是否为常量表达式由它的数据类型和初始值共同决定。
const int max_files = 20; // max_files是常量表达式
const int limit = max_files + 1; // limit是常量表达式
int staff_size = 27; // staff_size不是常量表达式
const int sz = get_size(); // sz 不是常量表达式
C++11允许将变量声明为constexpr类型以便由编译器来验证变量的值是否是一个常量表达式。
constexpr int mf = 20; // 20是常量表达式
constexpr int limit = mf + 1; // mf + 1是常量表达式
constexpr int sz = size(); // 只有当size是一个constexpr函数时,才是一条正确的声明语句
指针和引用都能定义成 constexpr,但是初始值受到严格限制。constexpr 指针的初始值必须是0、nullptr 或者是存储在某个固定地址中的对象。函数体内定义的普通变量一般并非存放在固定地址中,因此 constexpr 指针不能指向这样的变量。相反,函数体外定义的变量地址固定不变,可以用来初始化 constexpr 指针。
在 constexpr 声明中如果定义了一个指针,限定符 constexpr 仅对指针本身有效,与指针所指的对象无关。
const int *p = nullptr; // p是一个指向整型常量的指针
constexpr int *q = nullptr; // q是一个指向整数的常量指针
constexpr 把它所定义的对象置为了顶层 const。
与其他常量指针类似, constexpr 指针既可以指向常量也可以指向一个非常量:
constexpr int *np = nullptr; // np是一个指向整数的常量指针,其值为空
int j = 0;
constexpr int i = 42; // i的类型是整型常量
// i和j都必须定义在函数体之外
constexpr const int *p= &i; // p是常量指针,指向整型常量i
constexpr int *p1 = &j; // p1是常量指针,指向整数j
const 和 constexpr 限定的值都是常量。但 constexpr 对象的值必须在编译期间确定,而 const 对象的值可以延迟到运行期间确定。建议使用 constexpr 修饰表示数组大小的对象,因为数组的大小必须在编译期间确定且不能改变。
5、处理类型
1)类型别名
类型别名是某种类型的同义词,它让复杂的类型名字变得简单明了、易于理解和使用,还有助于程序员清楚地知道使用该类型的真实目的。有两利方法可用于定义类型别名。
传统方法是使用关键字 typedef 定义类型别名。
typedef double wages; // wages是double的同义词
typedef wages base, *p; // base是double的同义词,p是double*的同义词
C++11使用关键字 using 进行别名声明(alias declaration),作用是把等号左侧的名字规定成等号右侧类型的别名。
using SI = Sales_item; // SI是Sales item的同义词
2)auto类型说明符
C++11新增 auto 类型说明符,能让编译器自动分析表达式所属的类型。auto 定义的变量必须有初始值。
// 由val1和val2相加的结果可以推断出item的类型
auto item = val1 + val2; // item初始化为val1和val2相加的结果
使用 auto 也能在一条语句中声明多个变量。因为一条声明语句只能有一个基本数据类型,所以该语句中所有变量的初始基本数据类型都必须一样:
auto i = 0, *p = &i; // ok:i是整数、p是整型指针
auto sz = 0, pi = 3.14; // error:sz和pi的类型不一致
编译器推断出来的 auto 类型有时和初始值的类型并不完全一样,编译器会适当地改变结果类型,使其更符合初始化规则。
- 当引用被用作初始值时,真正参与初始化的其实是引用对象的值。编译器以引用对象的类型作为
auto的类型。
int i = 0, &r = i;
auto a = r; // a是一个整数(r是i的别名,而i是一个整数)
auto一般会忽略顶层const,同时底层const则会保留下来。
const int ci = i, &cr = ci;
auto b = ci; // b是一个整数(ci的顶层const特性被忽略掉了)
auto c = cr; // c是一个整数(cr是ci的别名,ci本身是一个顶层const)
auto d = &i; // d是一个整型指针(整数的地址就是指向整数的指针)
auto e = &ci; // e是一个指向整数常量的指针(对常量对象取地址是一种底层const)
如果希望推断出的 auto 类型是一个顶层 const,需要显式指定 const auto。
const auto f = ci; // ci的推演类型是int,f是const int
设置类型为 auto 的引用时,原来的初始化规则仍然适用,初始值中的顶层常量属性仍然保留。
auto &g = ci; // g是一个整型常量引用,绑定到ci
auto &h = 42; // error: 不能为非常量引用绑定字面值
const auto &j = 42; // ok: 可以为常量引用绑定字面值
要在一条语句中定义多个变量,切记, 符号&和*只从属于某个声明符,而非基本数据类型的一部分, 因此初始值必须是同一种类型:
auto k = ci, &l = i; // k是整数,l是整型引用
auto &m = ci, *p = &ci; // m是对整型常量的引用,p是指向整型常量的指针
// 错误:i的类型是int而&ci的类型是const int
auto &n = i,*p2 = &ci;
3)decltype类型指示符
C++11新增 decltype 类型指示符,作用是选择并返回操作数的数据类型,此过程中编译器不实际计算表达式的值。
decltype(f()) sum = x; // sum的类型就是函数f的返回类型
decltype 处理顶层 const 和引用的方式与 auto 有些不同,如果 decltype 使用的表达式是一个变量,则 decltype 返回该变量的类型(包括顶层 const 和引用)。
const int ci = 0, &cj = ci;
decltype(ci) x = 0; // x的类型是const int
decltype(cj) y = x; // y的类型是const int&, y绑定到变量x
decltype(cj) z; // error: z是一个引用,必须初始化
如果 decltype 使用的表达式不是一个变量,则 decltype 返回表达式结果对应的类型。如果表达式的内容是解引用操作,则 decltype 将得到引用类型。
// decltype的结果可以是引用类型
int i = 42, *p = &i , &r = i;
decltype (r + 0) b; // 正确:加法的结果是int,因此b是一个(未初始化的)int
decltype (*p) c; // 错误:c是int&,必须初始化
decltype 和 auto 的另一处重要区别是,decltype 的结果类型与表达式形式密切相关。注意:如果 decltype 使用的是一个不加括号的变量,则得到的结果就是该变量的类型;如果给变量加上了一层或多层括号,则 decltype 会得到引用类型,因为变量是一种可以作为赋值语句左值的特殊表达式。
// decltype的表达式如果是加上了括号的变量,结果将是引用
decltype ((i)) d; // 错误:d是int&,必须初始化
decltype (i) e; // 正确:e是一个(未初始化的)int
切记:decltype((var)) 的结果永远是引用,而 decltype(var) 的结果只有当 var 本身是一个引用时才会是引用。
6、自定义数据结构
C++11 规定可以为类的数据成员(data member)提供一个类内初始值(in-class initializer)。创建对象时,类内初始值将用于初始化数据成员,没有初始值的成员将被默认初始化。
类内初始值不能使用圆括号。
类定义的最后应该加上分号。
头文件(header file)通常包含那些只能被定义一次的实体,如类、const和constexpr变量。
头文件一旦改变,相关的源文件必须重新编译以获取更新之后的声明。
头文件保护符(header guard)依赖于预处理变量(preprocessor variable)。预处理变量有两种状态:已定义和未定义。#define指令把一个名字设定为预处理变量。#ifdef指令当且仅当变量已定义时为真,#ifndef指令当且仅当变量未定义时为真。一旦检查结果为真,则执行后续操作直至遇到#endif指令为止。
#ifndef SALES_DATA_H
#define SALES_DATA_H
#include 在高级版本的IDE环境中,可以直接使用#pragma once命令来防止头文件的重复包含。
预处理变量无视C++语言中关于作用域的规则。
整个程序中的预处理变量,包括头文件保护符必须唯一。预处理变量的名字一般均为大写。
头文件即使目前还没有被包含在任何其他头文件中,也应该设置保护符。
参考文章
- 《C++ Primer》
补充
这一章看的真的头疼,还在看,配合习题希望能好好理解这些晦涩的概念。