PANet 实例分割
Path Aggregation Network for Instance Segmentation(PANet)
用于实例分割的路径聚合网络
代码:https://github.com/ShuLiu1993/PANet
CVPR2018 Spotlight paper, coco2017实例分割第一名目标检测第二名
当前实例分割最佳模型Mask-RCNN的信息传播还不够充分,低层特征到高层特征的传递路径过长,FPN中每个proposal只负责金字塔特定的一层,掩码预测只基于单一视角。
论文贡献:
- 自底向上的路径增强,为了缩短信息传播路径,同时利用低层特征的精准定位信息。
- 动态特征池化,每个proposal利用金字塔所有层的特征,为了避免proposal的随意分配。
- 全连接层融合为了给mask预测增加信息来源,capture different view。
网络整体结构如下,可以看到明显是对Mask-RCNN的改进,整体框架没有变。
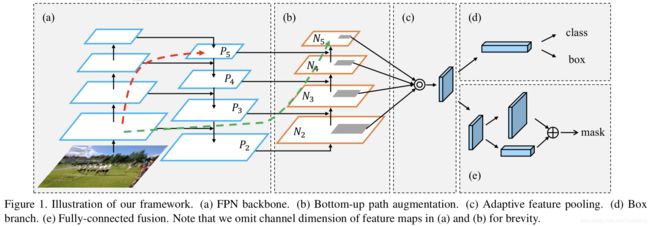
(1)自底向上路径增强
FPN是CVPR2017的Feature Pyramid Networks for Object Detection,主要是通过融合高低层特征提升目标检测的效果,尤其可以提高小尺寸目标的检测效果,不过只增强了语义信息,对定位信息没有传递,而本文就是针对这一点,在FPN的后面添加一个自底向上的金字塔。自底向上路径增强的引入主要是考虑网络浅层特征信息对于实例分割非常重要,浅层特征多是边缘形状等特征,而实例分割又是像素级别的分类。红色虚线箭头表示在FPN算法中,因为要走自底向上的过程,浅层的特征传递到顶层要经过几十甚至一百多个网络层(在FPN中,对应Figure1中那4个蓝色矩形块从下到上分别是ResNet的res2、res3、res4和res5层的输出,层数大概在几十到一百多左右),显然经过这么多层的传递,浅层特征信息丢失会比较厉害。绿色虚线箭头表示作者添加一个bottom-up path augmentation,本身这个结构不到10层,这样浅层特征经过底下原来FPN的侧面连接到P2再从P2沿着bottom-up path augmentation传递到顶层,经过的层数不到10层,能较好地保留浅层特征信息。关于自底向上路径增强的具体设计参考Figure2,最后融合得到的特征层是N2、N3、N4、N5,其中N2和P2相同,这些特征层用于后续的预测框分类、回归和mask生成。

每个构建块通过横向连接采用更高分辨率的特征图Ni和更粗糙的图Pi+1,生成新的特征图Ni+1。每个特征图Ni首先通过一个3×3,stride=2的卷积层,特征图尺寸缩减为原来的一半。然后通过横向连接添加特征图Pi+1的各个元素和下采样图。然后,将融合的特征图通过另一个3×3的卷积层进行处理,生成用于后续子网络的Ni+1。这是一个迭代过程,在P5后终止。在这些构建块中,通道数始终为256。所有卷积层后面都有一个relu[32]。然后,每个proposal的feature grid将从新的feature map(eg,N2、N3、N4、N5)中pool。
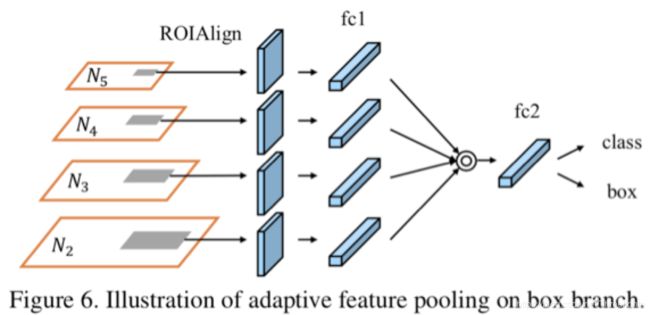
(2)动态特征池化
Adaptive Feature Pooling主要做的还是特征融合。在Faster RCNN系列的目标检测或语义分割算法中,RPN(Region Proposal Network)得到的ROI需要经过ROI Pooling或ROI Align提取ROI特征,这一步操作中每个ROI所基于的特征都是单层特征(FPN也是如此),比如ResNet网络中常用的res5的输出。而adaptive feature pooling则是将单层特征也换成多层特征,也就是说RPN网络得到的每个ROI都要分别在N2、N3、N4、N5层特征做ROI Align操作,这样每个ROI就提取到4个不同的特征图fc1,然后将4个不同的特征图融合(element-max or sum)在一起就得到最终特征fc2,后续的分类和框回归都是基于fc2进行。
现在分析不同级别的特征与自适应特征池的比例。使用max操作来融合不同级别的功能。根据它们最初在FPN中分配的级别将proposal分为四类。对于每组proposal,我们计算从不同级别选择的特征比例。
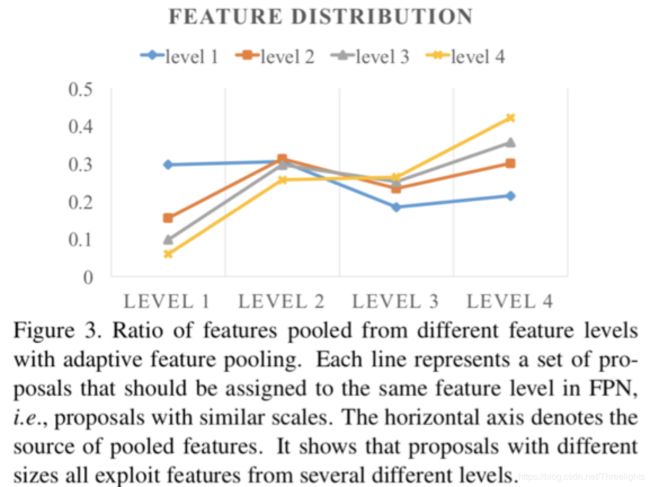
Figure3中有4条曲线,对应FPN网络中基于4层特征做预测,每一层都会经过RPN网络得到ROI,所以这4条曲线就对应4个ROI集合。横坐标则表示每个ROI集合所提取的不同层特征的占比。比如蓝色曲线代表level1,是尺度比较小的ROI集合,这一类型的ROI所提取的特征仅有30%是来自于level1的特征,剩下的70%都来自其他level的特征,leve2、leve3、leve4曲线也是同理,这说明原来RPN网络的做法并不是最佳的。因此就有了特征融合的思考,也就是每个ROI提取不同层的特征并做融合, 这一观察表明,多个层面上的特征一起有助于准确预测。
(3)全连接层融合
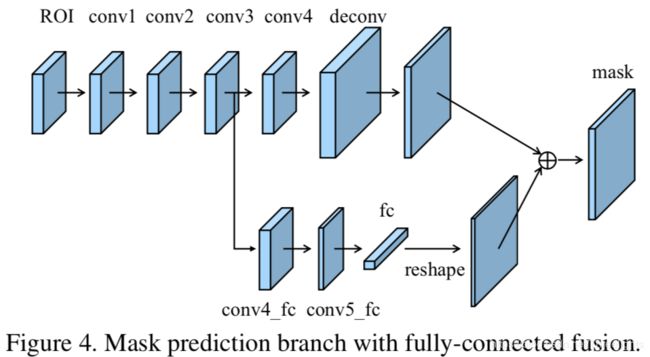
全连接层具有不同于CNN的结构,CNN产生的特征图上每个像素点来自同一个卷积核,也就是常说的参数共享,另外,卷积核的大小往往为3*3,5*5,7*7,也就是说采集的是局部的信息。
主要是在原来的mask支路(Figure4上面那条支路,也就是传统的FCN结构)上增加了下面那条支路做融合。增加的这条支路包含2个3*3的卷积层(其中第二个为了降低计算量将通道缩减为原来的一半),然后接一个全连接层,再经过reshape操作得到维度和上面支路相同的前背景mask(28*28),也就是说下面这条支路做的是前景和背景的二分类,因此输出维度类似文中说到的28*28*1。上面这条支路,也就是传统的FCN结构将输出针对每个类别的二分类mask,因此输出的通道就是类别的数量,输出维度类似28*28*K,K表示类别数。最终,这两条支路的输出mask做融合得到最终的结果。可以看出这里增加了关于每个像素点的前背景分类支路,通过融合这部分特征得到更加精确的分割结果。
实验结果:

Table1是PANet和Mask RCNN、FCIS算法(COCO2016实例分割算法冠军)在COCO数据集上的分割效果对比
AP是指average precision,平均精确率,即多类预测的时候每一类的precision取平均,类似地还有AR,平均召回率。AP50,AP75指的是取detector的IoU阈值大于0.5,大于0.75。数值越高,精确率越低,表明越难。APS、APM和APL表示三个度量不同尺度对象的性能。
我们使用ResNet-50对多尺度图像进行训练并在单幅图像上进行测试的PANet已经胜过Mask R-CNN和2016年的冠军,其中后者使用了更大的模型集合和测试技巧[23, 33, 10, 15, 39, 62]。经过训练和测试,图像比例尺800与Mask R-CNN相同,我们的方法在相同的初始模型下比单独模型的最先进的Mask R-CNN具有近3点的性能差距。
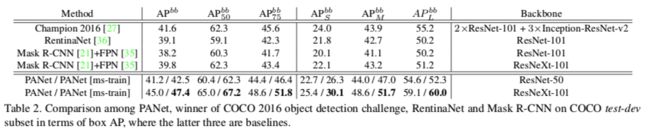
Table2是PANet和Mask RCNN、FCIS、RentinaNet算法在COCO测试开发子集中的框AP的检测效果对比(主网络为ResNeXt-101时,单模型效果达到45算很高了)。
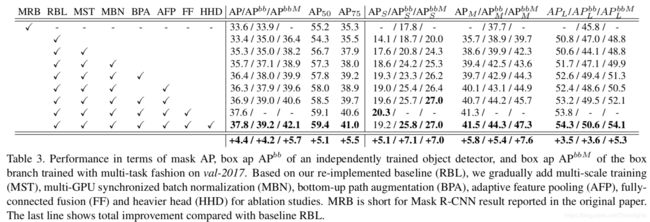
Table3是关于文章中提到的几个优化点带来的效果对比。其中MRB是原始报告中Mask-RCNN的简称;RBL是baseline,本文复现的mask R-CNN;MST是多尺度训练;MBN是多GPU同步批量规范化;BPA是自上而下路径增强;AFP是自适应特征池;FF是完全特征融合;HHD是较大的头部。最后一行显示与基线RBL相比的总体改善。
Table 4 自适应特征融合的消融研究
文中对自适应特征融合进行消融研究,以找到融合操作的位置和最合适的融合操作。我们把它放在ROIAlign和fc1之间,用“fu.fc1fc2”表示,或者用“fc1fu.fc2”表示在fc1和fc2之间。掩码预测分支也使用类似的设置。对于特征融合,测试MAX和SUM操作。
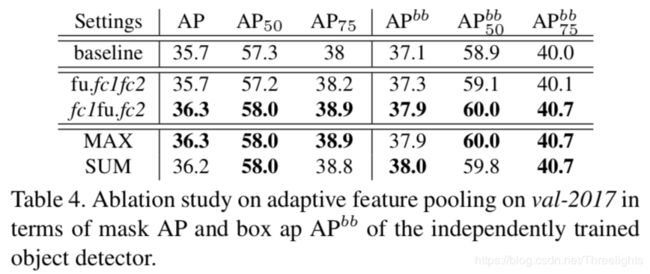
所以使用max作为融合操作,并在框架的fc1后使用融合操作。
Table 5 完全连接融合的消融研究

用不同的方式来调查性能,以实例化增强的fc分支。考虑两个方面,即开始新分支的层次以及融合新分支和FCN预测的方式。尝试分别从conv2,conv3和conv4创建新路径。“max”,“sum”和“product”操作用于融合。我们将复现的Mask R-CNN的自底向上路径增强和自适应特征池作为基准。相应的结果显示在表5中。结果表明,从conv3开始凝视融合产生了最好的结果。
Table6和Table7是关于在COCO实例分割和目标检测比赛上的结果。
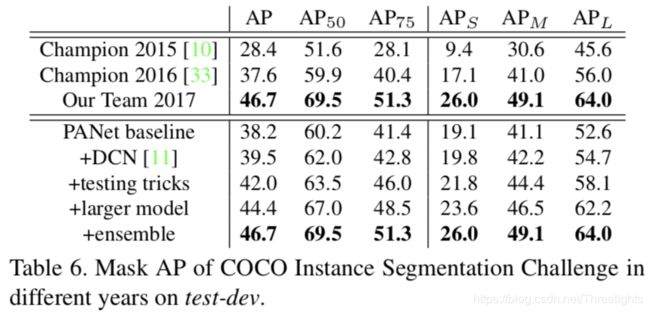
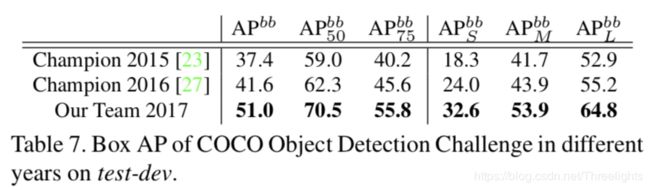
如表6和表7所示,与去年冠军相比,我们在实例分割方面提高了了9.1%,相对24%的改善。而对于物体检测,提高了9.4%,相对提高了23%。其中,DCN为Deformable convolutional networks(可变形的卷积)。
结果和消融研究
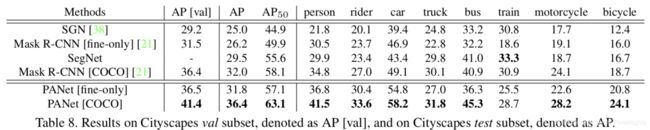
我们的方法受到“纯粹”数据的训练,其“面向全新”数据的面值优于Mask R-CNN 5.6个点。通过对COCO进行预训练,我们以4.4分的优势优于Mask R-CNN。可视化结果如图5.
图5.每行中的图像分别是我们的COCO test-dev,Cityscapes测试和MVD测试模型的可视化结果。