CNN发展历程(AlexNet-MobileNet V3)
CNN发展历程
- 2012 AlexNet
- 2014 VGG
- 2014 GoogLeNet
- Inception v1
- Inception v2:
- Inception v3:
- Inception v4
- 2015 ResNet
- 2016 DenseNet
- 2017 MobileNet
- MobileNet V1 (2017)
- MobileNet V2 (2018)
- MobileNet V3 (2019)
2012 AlexNet
(1)与最早的卷积神经网络LeNet相比,AlexNet的层数更深,共有7层,并且使用ReLU作为非线性激活函数
(2)使用dropout对抗过拟合
(3)使用max-pooling下采样
2014 VGG
(1)与AlexNet相比,VGG的层数更深,最高达到19层,可以增强网络的非线性表达能力
(2)与AlexNet相比,VGG使用更小的卷积核。VGG大量使用3×3的卷积,将多个3×3卷积排列起来形成一个卷积序列,该卷积序列与大卷积核具有相同的感受野,并具有更少的参数
2014 GoogLeNet
GoogLeNet有很多版本,包括Inception v1,v2,v3等,后者大多是对v1的改进
Inception v1
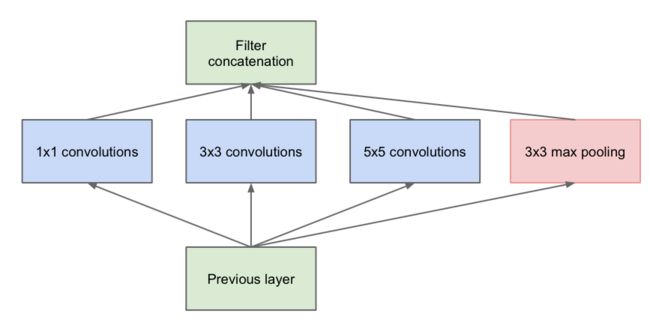
(1)Inception v1采用模块化的结构,每一模块以上一模块的输出作为输入。对输入分别进行1×1、3×3、5×5的卷积以及 3×3的max pooling后,将四路分支通过并联(Concat)融合起来。并且在3×3和5×5的卷积之前,先进行1×1的卷积进行降维,以减少计算复杂度,去除特征冗余,并且3×3max pooling后也进行1×1卷积,以提升网络非线性表达能力。
(2)Inception v1使用多种大小的卷积核,意味着多种不同大小的感受野,最后的拼接意味着多尺度特征的融合,从而提高网络表达能力。
(3)未来防止梯度消失,Inception v1除了在网络最后使用softmax之外,还在中间层使用额外的两个辅助softmax反传梯度
(4)网络的最后使用全局平均池化代替全连接,减少了参数数量

Inception v2:
(1)在v1的基础上增加了Batch Normalization
(2)使用两个3×3卷积代替5×5卷积

Inception v3:
(1)把n×n卷积分解为一个1×n卷积核一个n×1卷积,进一步缩减参数量
(2)输入图像大小由224×224放大至299×299

Inception v4
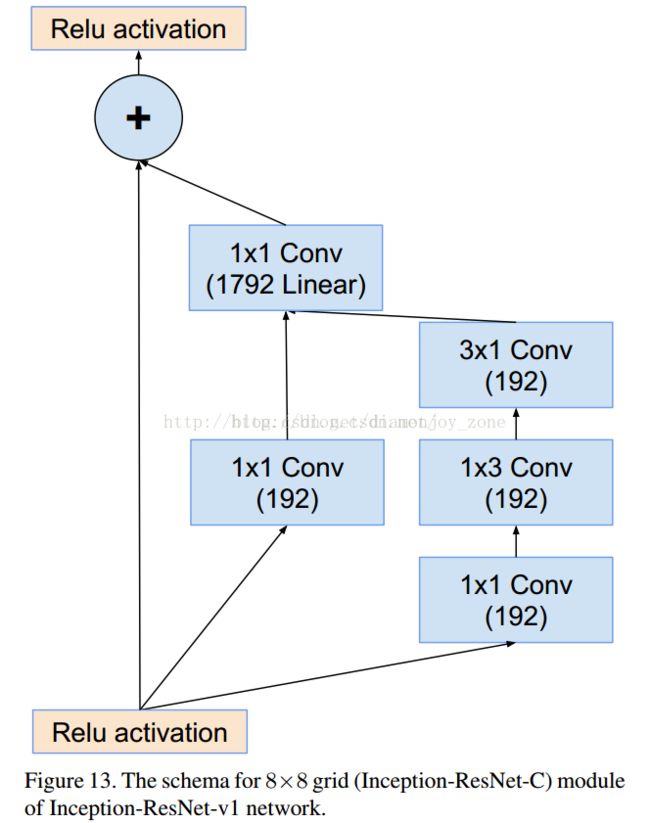
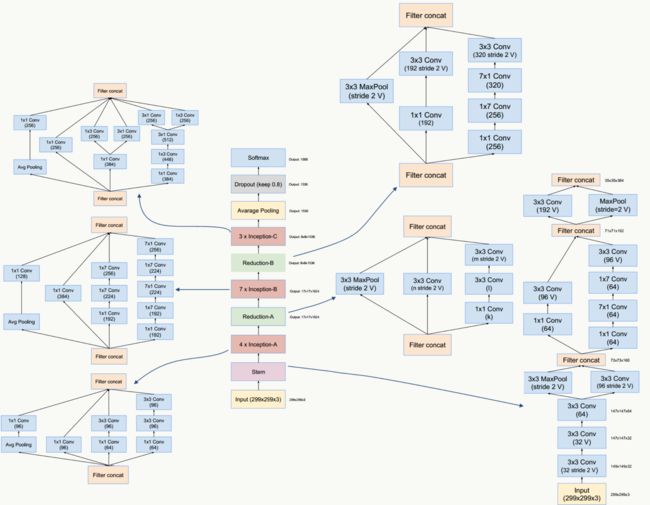
(1)研究了 Inception Module 结合 Residual Connection,结合 ResNet 可以极大地加速训练,同时极大提升性能,在构建 Inception-ResNet 网络同时,还设计了一个更深更优化的 Inception v4 模型,能达到相媲美的性能



2015 ResNet
(1)ResNet的最大特点是网络层数大大加深,由前面的十几层可以加深至50层(ResNet-50)101层(Reset-101)甚至上千层
(2)ResNet提出residual结构,使用跳层连接对抗过拟合,residual结构进行特征汇聚时使用相加操作(Eltwise-sum)
(3)ResNet也使用1×1卷积进行降维,使用全局平均池化代替全连接,减小参数量和计算复杂度
2016 DenseNet
(1)DenseNet使用模块化结构,网络可以分为多个denseblock,denseblock之间使用transition layer相连,transition layer对dense block的输出进行处理,防止网络过于庞大
(2)denseblock内,每层都以前面所有层的输出作为输出,以防止梯度消失,加强特征传递,更有效地利用特征
(3)DenseNet与ResNet相比,二者在特征融合时存在不同,DenseNet使用Concat操作,ResNet使用Eltwise操作
2017 MobileNet
MobileNet V1 (2017)
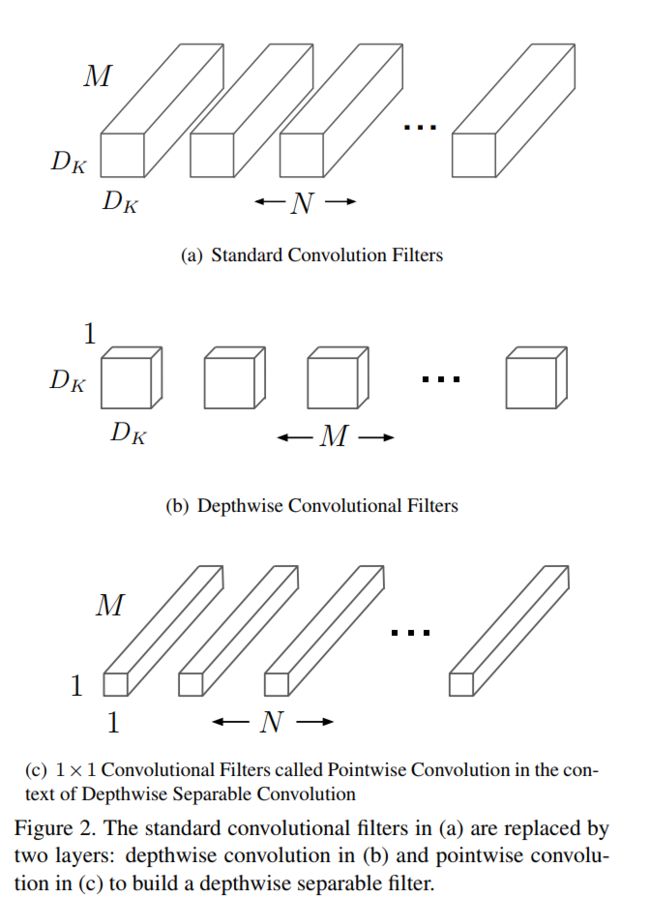
(1)MobileNets基于一种流线型结构使用深度可分离卷积来构造轻型权重深度神经网络,核心部件就是深度可分离卷积
(2)MobileNet是一种基于深度可分离卷积的模型,深度可分离卷积是一种将标准卷积分解成深度卷积以及一个1x1的卷积即逐点卷积
(3)深度卷积针对每个单个输入通道应用单个滤波器进行滤波,然后逐点卷积应用1x1的卷积操作来结合所有深度卷积得到的输出
(4)对深度卷积,它的卷积核厚度不是输入张量的通道数,而是1,输出通道就是卷积核数目。经典卷积的卷积核厚度默认是图片的通道数
(5)可分离卷积tf内置函数:tf.layers.separable_conv2d
- 因此传统卷积需要计算量

DF : 输出图像尺寸,与输入图像尺寸相同(输出图像的尺寸代表一个卷积核(3维的,包含通道)对输入图像进行的卷积次数)
DK : 卷积核的大小(二维)
M : 输入图像的通道数,即为卷积核的通道数
N : 输出图像的通道数,即为卷积核的个数 - Pointwise Convolution需要计算量:

需要的总计算量为:

- 与传统卷积计算量相比
公式计算:


MobileNet V2 (2018)
(1)Mobilenet V2实在Mobilenet V1的基础上发展而来,V2 主要引入了两个改动:Linear Bottleneck 和 Inverted Residual Blocks。两个改动分别对应V1和Resnet
(2)MobileNetV1遗留的问题
- 结构问题:
MobileNet V1 的结构其实非常简单,论文里是一个非常复古的直筒结构,类似于VGG一样。这种结构的性价比其实不高,后续一系列的 ResNet, DenseNet 等结构已经证明通过复用图像特征,使用 Concat/Eltwise+ 等操作进行融合,能极大提升网络的性价比。 - Depthwise Convolution的潜在问题:
Depthwise Conv确实是大大降低了计算量,而且N×N Depthwise +1×1PointWise的结构在性能上也能接近N×N Conv。在实际使用的时候,我们发现Depthwise部分的kernel比较容易训废掉:训练完之后发现Depthwise训出来的kernel有不少是空的。当时我们认为,Depthwise每个kernel dim相对于普通Conv要小得多,过小的kernel_dim, 加上ReLU的激活影响下,使得神经元输出很容易变为0,所以就学废了。ReLU对于0的输出的梯度为0,所以一旦陷入0输出,就没法恢复了。我们还发现,这个问题在定点化低精度训练的时候会进一步放大。
(3) 对比 MobileNet V1 与 V2 的微结构

- 相同点
都采用 Depth-wise (DW) 卷积搭配 Point-wise (PW) 卷积的方式来提特征。这两个操作合起来也被称为 Depth-wise Separable Convolution,之前在 Xception 中被广泛使用。
- 不同点:Linear Bottleneck
- V2 在 DW 卷积之前新加了一个 PW 卷积。这么做是因为 DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以如果上一层给的通道数本身很少的话,DW 也只能很委屈的在低维空间提特征,因此效果不够好。现在 V2 为了改善这个问题,给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数 t = 6,这样不管输入通道数是多是少,经过第一个 PW 升维之后,DW 都是在相对的更高维进行着辛勤工作的。
- V2 去掉了第二个 PW 的激活函数。论文作者称其为 Linear Bottleneck。这么做的原因,是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个 PW 的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用 ReLU6 了
(4) 对比 ResNet 与 MobileNet V2 的微结构

- 相同点
MobileNet V2 借鉴 ResNet,都采用了1x1-3x3-1x1 的模式。
MobileNet V2 借鉴 ResNet,同样使用 Shortcut 将输出与输入相加 - 不同处
ResNet 使用 标准卷积 提特征,MobileNet 始终使用 DW卷积 提特征
ResNet是:压缩”→“卷积提特征”→“扩张”,MobileNetV2则是Inverted residuals,即:“扩张”→“卷积提特征”→ “压缩”
论文作者将 MobileNet V2 的结构称为 Inverted Residual Block。这么做也是因为使用DW卷积而作的适配,希望特征提取能够在高维进行。
MobileNet V3 (2019)
论文地址:https://arxiv.org/pdf/1905.02244.pdf
(1)具体的内容可以看论文,这里我只是重点说明其中的激活函数改进(swish/h-swish)和网络结构改进(bneck)
(2)激活函数:作者发现一种新出的激活函数swish x 能有效改进网络精度




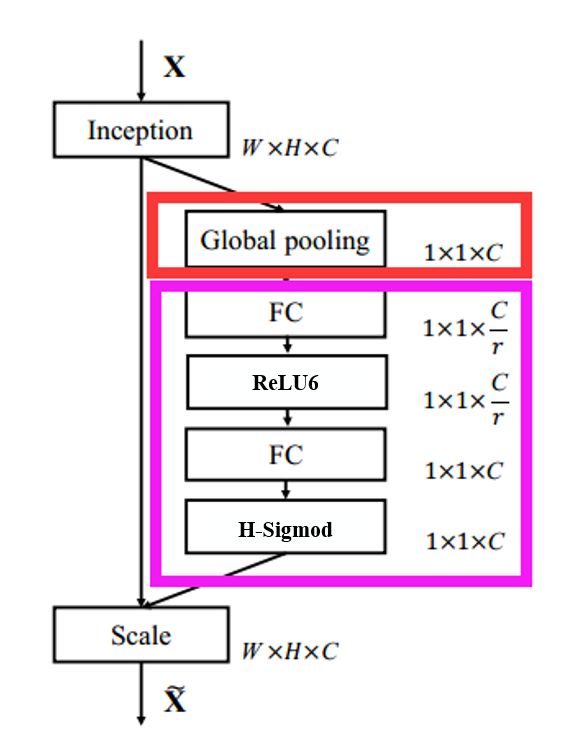
Squeeze excitation layer是引入基于squeeze and excitation结构的轻量级注意力模型SENet

论文:《Squeeze-and-Excitation Networks》
论文链接:https://arxiv.org/abs/1709.01507