Transformer模型中重点结构详解
Transformer模型中各结构的理解
最近学习Transformer模型的时候,并且好好读了一下Google的《Attention is all you need》论文。论文地址如下: Attention is All you need。同时学习了一下其github的代码,代码地址如下:github code. 在网上查资料的过程中,还找到了一个好像也用的比较多的版本:[Transformer demo]
(https://github.com/princewen/tensorflow_practice/tree/master/basic/Basic-Transformer-Demo).
Transformer模型由Encoder和Decoder两部分组成。网络上详细讲解Transformer中各部分基础的内容也都比较多了,所以本次写博客主要还是想更细致的把模型梳理一遍,想一想各部分在模型中的功能作用,以及其意义。
包括但不限于:
1.Multi-Head Attention的意义及其作用,为什么要进行Multi-Head
2.Residual Network 和 Layer Normalizaiton在模型中的作用
3.为什么要添加Feed Forward层
4.Decoder中的Mask Mulit-Head Attention的结构
5.Decoder中最后的linear 和 softmax
这里稍微讲一下我对其中某些模型结构的可能的一点理解(如有错误,还希望大家指正)。
整体的Transformer框架的模型结构如图:
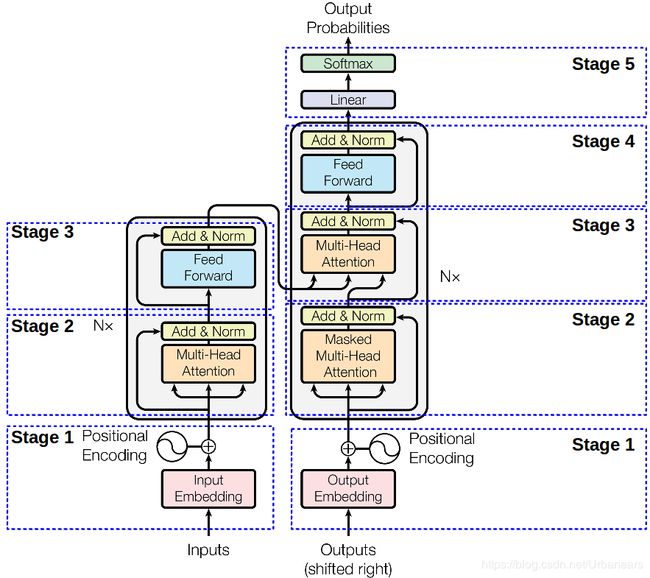
Encoder
Stage 1 - Encoder input
Encoder的输入即是原始的word embedding。由于在Transformer模型中,没有递归,也没有卷积,所以序列中每个标记的绝对(或相对)位置的信息用“位置编码”来表示,因此编码器的输入为:
*positional embeddings added + embedded inputs*
更多关于position_embedding的内容可以参考:
position embedding 和segment embedding解释?
接下来是由6个相同的层连接组成的,每一层中又包含了两个子层。其中,第一个子层是Multi-Head Attention层,该子层利用多头注意力机制,利用线性变换将Q、K、V映射到不同的子空间(论文中num_heads = 8),从而希望可以学习到单词的不同表示。例如如下图所示: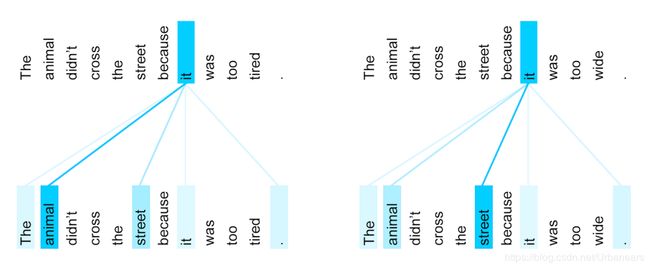
stage 2 - Multi-Head Attention
Transformer模型使用了多层注意力机制来代替了single self-attention,以此来提升模型的效果。Multi-Head Attention的效果体现在以下两个方面:
(1)扩展了模型关注不同位置的能力。如上图所示,在不同的context中,使得单词"it"关注到不同的target word。
(2)增强了Attention机制对关注句子内部单词之间作用的表达能力。相比于single self-attention, Multi-Head Attention中的each head都维持了一个自己的Q、K、V矩阵,实现不同的线性转换,这样每个head也就有了自己特殊的表达信息。
这种思想背后的原理即是,当你翻译一个单词的时候,你会基于你所问的问题的类型来对每个单词给予不同的关注程度。例如,当你在“I kick the ball”这个句子中翻译“kick”时,你可以问“Who kick”。根据答案的不同,把这个单词翻译成另一种语言可能会发生变化。或者问其他问题,比如“做了什么?”等等。
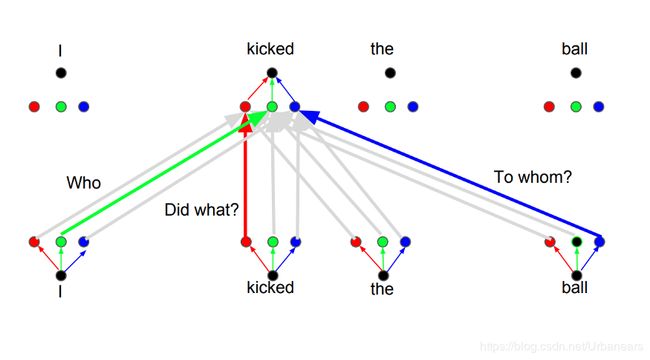

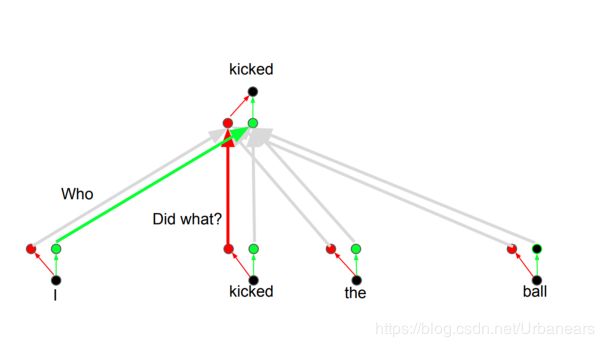
即例如你可以把所设置的每个head(论文中num_heads=8),看做是一个问题,比如Who、Did what、To whom…(假设有8个不同的问题)。而这时根据不同的问题,单词"kicked"会与不同的词进行关联,也就相当于是每个head都会产生一个独立的由该head下Q、K、V所生成的word representation. 不同的representation表达了该context中的不同单词之间的语法结构、依赖关系。比如在对单词"kicked"进行Attention时,第一个问题Who(相当于第一个head),即使得"kicked"与"I"的Attention score更高,表明"I"即是"kicked"的主语,第二个问题Did what(相当于第二个head), 即使得"kicked"与"kicked"的attention score更高,表明"kicked"即是所做的动作,第三个问题To whome(相当于第三个head),即使得"kicked"与"ball"的attention score更高,表明"ball"即是"kicked"所做的对象,宾语。以此类推。即对每个词都学习了num_heads个不同的representation(当然正如论文中所说,每个head下的representation的维度为d_model / num_heads,因为后续还要拼接成d_model的大小),学习到了该词在context中对其他词的依赖关系(相比于single self-attention则只能学习一次),更好的学习到了每个单词的representation,从而提升了模型Attention机制的表达能力。
Layer Normalization & Residual Network
Multi-Head Attention层后跟了一个Layer Normalizaiton用来对Attention输出的新的word representation进行标准化处理,以及一个Residual Network。
详细的残差网络的结构特点在这里就不详细介绍了,有兴趣的可以参考以下链接:
残差网络(Deep Residual Learning for Image Recognition)
resnet(残差网络)的F(x)究竟长什么样子?
详解残差网络
这里采用了Residual Network的作用我认为是利用了残差网络可以当层数加深时仍然能进行很好的训练一个特性。因为在模型结构中,首先每个层都重复6次,且每个层都有两个子层,这就总共相当于有了12层。同时,Multi-Head Attention层和Feed Forward层内部又都有自己的结构,比如Feed Forward层就有两层的fully-connection layers。所以为了使当模型中的层数较深时仍然能得到较好的训练效果,使得梯度不至于在层数加深时产生消失,所以添加了Residual Network.
而添加Layer Normalizaiton处理的作用则是对数据进行标准化处理,方便后续在Feed Forward中的ReLU激活函数对数据进行非线性处理。通过Normalizaition将数据标准化到ReLU激活函数的作用区域,可以使得激活函数更好的发挥作用(实际应用中也是在ReLU激活函数前往往会加入batch normalizaiton或者layer normalizaiton)。
关于layer normalizaiton和batch normalizaiton之间的作用方式和区别可以参考:
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结
【AI数学】Batch-Normalization详细解析
stage 3 - Feed Forward
而在Multi-Head Attention层之后还添加了一层Feed Forward层。Feed Forward层是一个两层的fully-connection层,中间隐藏层的单元个数为d_ff = 2048。这里在学习到representation之后,还要再加入一个Feed Forward的作用我的想法是:
注意到在Multi-Head Attention的内部结构中,我们进行的主要都是矩阵乘法(scaled Dot-Product Attention),即进行的都是线性变换。而线性变换的学习能力是不如非线性变化的强的,所以Multi-Head Attention的输出尽管利用了Attention机制,学习到了每个word的新representation表达,但是这种representation的表达能力可能并不强,我们仍然希望可以通过激活函数的方式,来强化representation的表达能力。比如context:The animal didn’t cross the road because it was too tired,利用激活函数,我们希望使得通过Attention层计算出的representation中,单词"it"的representation中,数值较大的部分则进行加强,数值较小的部分则进行抑制,从而使得相关的部分表达效果更好。(这也是神经网络中激活函数的作用,即进行非线性映射,加强大的部分,抑制小的部分)。我觉得这也是为什么在Attention层后加了一个Layer Normalizaiton层,通过对representation进行标准化处理,将数据移动到激活函数的作用区域,可以使得ReLU激活函数更好的发挥作用。同时在fully-connection中,先将数据映射到高维空间再映射到低维空间的过程,可以学习到更加抽象的特征,即该Feed Forward层使得单词的representation的表达能力更强,更加能够表示单词与context中其他单词之间的作用关系。
整个过程的数学公式表达为:其中max即代表了ReLU激活函数
FFN(x) = max(0, xW1 + b1)W2 + b2
Decoder
接下来分析一下Decoder中的模型结构。Decoder不仅处理以前生成的其他单词,而且处理编码器生成的最终表示形式。
stage 1 - decoder_input
每一时刻Decoder的输出都会作为下一时刻的输入,这与Seq2Seq模型中解码器的部分差不多。输入是输出的embedding 表示,偏移一个位置,以确保位置i的预测只依赖于i之前(小于)i 的位置。
stage 2 - Mask Multi-Head Attention
在Decoder模型中的大部分结构与Encoder中的想法类似,主要要注意的一个是Mask Multi-Head Attention。
Mask Multi-Head Attention的结构主要基于的思想就是,由于在解码器中,我们仍然是按序列化的方式来进行(而不像编码器中可以以并行的形式对句子中的所有单词进行Attention计算),即同Seq2Seq模型中解码器部分一样需要一个单词一个单词的进行输入,即我们只有在某一时刻预测出了某一单词后,才能继续预测后面的词。所以根据这种思想,在预测输出的sentence中,某一单词只能跟其之前的单词产生联系(因为当预测到某一单词时,其后的单词还是未知的)。所以在利用Attention score对矩阵V中单词的token进行加权求和时,Attention score只能是一个下三角的矩阵。这一点在模型代码中可以比较好的进行分析理解。综合来说就是,这里的masked decoder self attention, 就是为了防止当前的生成的单词对未来的单词产生依赖性。
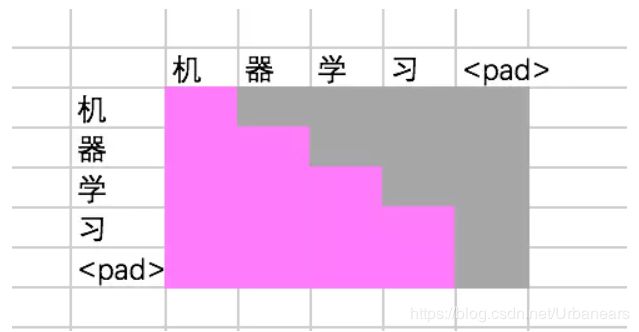
stage 3 - Multi-Head Attention
Mask Multi-Head Attention层之后是一个Multi-Head Attention层。该层与Encoder的输出相连,其中K、V矩阵由Encoder的输出提供,Q由Mask Multi-Head Attention的输出提供。这里的Attention思想与传统的Seq2Seq模型解码器部分的Attention思想类似。即将解码器的输入与编码器中编码好的每个单词的representation计算Attention score,然后计算Attention score与V的矩阵乘法,从而得到编码器中编码单词在解码器中待翻译单词中的表达。Transformer模仿了经典的注意机制,其中encoder-decoder的注意层queries来自于之前的解码器层,(memory) keys和values来自编码器的输出。因此,解码器中的每个位置都可以参加输入序列中的所有位置。
这里,对流程中各矩阵维度的变化举例为:假设此时decoder_input的输入单词为2个,则下三角的Attention score的矩阵为shape:(2,2),与V相乘后的输出维度为shape:(2,d_model)。然后输入到Multi-Head Attention中作为矩阵Q,此时编码器的输出维度为shape : (n, d_model)并作为矩阵K、V。在Multi-Head Attention中,Q*K转置的维度为shape : (2,n).结果再与矩阵V相乘得到的维度为shape (2, d_model).即可得到这两个单词的表达。
接下来仍然是一个Feed Forward全连接层,与Encoder中的相同。
stage 5 - Linear & Softmax
Decoder最后是一个线性变换和softmax层。解码组件最后会输出一个实数向量。我们如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数(相当于做vocaburary_size大小的分类)。接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。

整个Transformer中的Encoder和Decoder的模型结构大致就是这样组成的。其模型内除了主要的Attention部分,还添加了诸如Residual Network、Layer Normalizaition、Feed Forward部分来使模型得到更好的效果,所以在学习论文的过程中,也是对这些方面的内容进行了一定时间的学习,也是需要理解到添加这些部分的意义才能更好的理解Transformer模型在运行时候的机制。
整体的运行流程如下图所示:
在看完论文之后,针对论文中一些细节和疑惑的地方,对Transformer的源码进行了一定的分析,来学习整个构建模型的过程以及Transformer模型的实现细节。后续会再进行补充。
源码部分的内容有兴趣的可以查看Attention is all you need 源码解析