检测相关问题面试准备
1. OHEM (online Hard Example Mining)
OHEM(online hard example miniing)算法的核心思想是根据输入样本的损失进行筛选,筛选出hard example,表示对分类和检测影响较大的样本; 然后将筛选得到的这些样本应用在随机梯度下降中训练。在实际操作中是将原来的一个ROI Network扩充为两个ROI Network,这两个ROI Network共享参数。其中前面一个ROI Network只有前向操作,主要用于计算损失;后面一个ROI Network包括前向和后向操作,以hard example作为输入,计算损失并回传梯度。该算法主要用于Fast RCNN。
算法的优点:(1)对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强。(2)
随着数据集的增大,算法的提升更加明显(作者是通过在COCO数据集上做实验和VOC数据集做对比,因为前者的数据集更大,而且提升更明显,所以有这个结论)。
什么是难样本:有多样性和高损失的样本。重合率比较大的ROI之间的损失也比较相似。因此这里作者采用NMS(non-maximum suppresison)去除重合率较大的ROI,这里作者给的阈值是当IOU大于0.7就认为重合率较高,需去除。
在Fast RCNN上OHEM 结构

包含两个ROI network,上面一个ROI network是只读的,为所有的ROI在前向传递的时候分配空间。下面一个ROI network则同时为前向和后向分配空间。 首先,ROI经过ROI plooling层生成feature map,然后进入只读的ROI network得到所有ROI的loss;然后是hard ROI sampler结构根据损失排序选出hard example,并把这些hard example作为下面那个ROI network的输入。
实际训练的时候,每个mini-batch包含N个图像,共|R|个ROI,也就是每张图像包含|R|/N个ROI。经过hard ROI sampler筛选后得到B个hard example。作者在文中采用N=2,|R|=4000,B=128。 另外关于正负样本的选择:当一个ROI和一个ground truth的IOU大于0.5,则为正样本;当一个ROI和所有ground truth的IOU的最大值小于0.5时为负样本。
2.A-Fast-RCNN (利用GAN来生成hard example,而不是像OHEM这样选择hard example)
3. faster rcnn 和ssd 为什么用smooth L1 loss和 L2有什么区别
使用smooth L1的原因
(1) 当预测框与 ground truth 差别过大时,梯度值不至于过大;(2)当预测框与 ground truth差别很小时,梯度值足够小。


4.FPN 特征级联金字塔在检测算法中的应用
5.检测领域目前存在的问题
针对遮挡问题设计的相关loss
在如何高效准确地生成Proposals、如何获取更好的ROI features、如何加速Two-Stage检测算法以及如何改进后处理方法
如何高效的获得生成的Proposals:
R-CNN[11]:R-CNN生成Proposals的方法是传统方法Selective Search,主要思路是通过图像中的纹理、边缘、颜色等信息对图像进行自底向上的分割,然后对分割区域进行不同尺度的合并,每个生成的区域即一个候选Proposal,如下图所示。这种方法基于传统特征,速度较慢。
Faster R-CNN使用RPN网络代替了Selective Search方法,大大提高了生成Proposals的速度;
FPN:Faster R-CNN只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。FPN算法把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息,然后在不同尺度的特征层上进行预测,使得生成Proposals的效果优于只在顶层进行预测的Faster R-CNN算法。
Cascade R-CNN:Cascade R-CNN在获取Proposals的时候也采用逐步求精的策略,前一步生成的Proposals作为后一步的输入,通过控制正样本的交并比阈值不断提高Proposals的质量;
如何获取更好的ROI features:
6.单阶段检测算法的发展
yolo v1算法:
YOLO 的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。
将目标检测看成回归问题,所以采用的是均方差损失函数。但是对不同的部分采用了不同的权重值。首先区分定位误差和分类误差。对于定位误差,即边界框坐标预测误差,采用较大的权重。
实现方法:将一张图像化成s*s的网格,如果某个object 的中心落在这个网格中,这个网络就负责这个object。每个网格要预测 B 个 bounding box,每个 bounding box 除了要回归自身的位置之外,还要附带预测一个 confidence 值。 每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值,每个网格还要预测一个类别信息,记为 C 类。则 SxS个 网格,每个网格要预测 B 个 bounding box 还要预测 C 个 categories。输出就是 S x S x (5*B+C) 的一个 tensor。
网络设计:yolo的网络模型参考的是GooLeNet模型,包含24个卷积层和2个全连接层,对于卷积层和全连接层,采用Leaky ReLU激活函数。但是最后一层却采用线性激活函数。最后的输出如下图:

Yolo算法将目标检测看成回归问题,所以采用的是均方差损失函数。但是对不同的部分采用了不同的权重值。首先区分定位误差和分类误差。对于定位误差,即边界框坐标预测误差,采用较大的权重。

首先是优点,Yolo采用一个CNN网络来实现检测,是单管道策略,其训练与预测都是end-to-end; Yolo算法比较简洁且速度快。第二点由于Yolo是对整张图片做卷积,所以其在检测目标有更大的视野,它不容易对背景误判;Yolo的泛化能力强,在做迁移时,模型鲁棒性高。速度快,超过实时。
缺点:首先Yolo各个单元格仅仅预测两个边界框,而且属于一个类别。对于小物体,Yolo的表现会不如人意。这方面的改进可以看SSD,其采用多尺度单元格。也可以看Faster R-CNN,其采用了anchor boxes。Yolo对于在物体的宽高比方面泛化率低,就是无法定位不寻常比例的物体。当然Yolo的定位不准确也是很大的问题。挨近的物体的检测效果不好。同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力偏弱。由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
注意:(1)由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率;
(2)虽然每个格子可以预测 B 个 bounding box,但是最终只选择只选择 IOU 最高的 bounding box 作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是 YOLO 方法的一个缺陷。
yolo v2算法:
文章提出了一种新的训练方法–联合训练算法。这种算法可以把这两种的数据集(现有分类和检测的数据集)混合到一起。使用一种分层的观点对物体进行分类,用巨量的分类数据集数据来扩充检测数据集,从而把两种不同的数据集混合起来。
联合训练算法的基本思路就是:同时在检测数据集和分类数据集上训练物体检测器(Object Detectors ),用检测数据集的数据学习物体的准确位置,用分类数据集的数据来增加分类的类别量、提升鲁棒性。
2018年的业界最佳检测算法???
YOLO9000 就是使用联合训练算法训练出来的,他拥有 9000 类的分类信息,这些分类信息学习自ImageNet分类数据集,而物体位置检测则学习自 COCO 检测数据集。
YOLO 一代有很多缺点,作者希望改进的方向是改善 recall,提升定位的准确度,同时保持分类的准确度。
具体改进:

(1)使用batch normalization
(2)high resolution classifier 448*448
(3)Convolution with anchor boxes 输入是416*416 最后通过32的下采样,得到13*13 的feature map 最后使用anchor box 这个时候精确度下降;
(4)Dimension clusters, 对gt box进行聚类,获得base size 和ratio

centroid是当前的遍历的某个bounding box 而利用1-IOU的来度量距离
(5)Direct location prediction
作者发现通过预测偏移量而不是坐标值能够简化问题,让神经网络学习起来更容易。

Dimension clusters和Direct location prediction,使 YOLO 比其他使用 Anchor Box 的版本提高了近5%。
(6)Fine-Grained Features
YOLO 采取了不同的方法,YOLO 加上了一个 Passthrough Layer 来取得之前的某个 26*26 分辨率的层的特征(利用FPN的思想,集合低层语义的feature map),这个 Passthrough layer 能够把高分辨率特征与低分辨率特征联系在一起,联系起来的方法是把相邻的特征堆积在不同的 Channel 之中,这一方法类似与 Resnet 的 Identity Mapping,从而把 26*26*512 变成 13*13*2048。YOLO 中的检测器位于扩展后(expanded )的特征图的上方,所以他能取得细粒度的特征信息,这提升了 YOLO 1% 的性能。
(7)Multi-Scale Training
OLOv2 每迭代几次都会改变网络参数。每 10 个 Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是 32,所以不同的尺寸大小也选择为 32 的倍数 {320,352…..608},最小 320*320,最大 608*608,网络会自动改变尺寸,并继续训练的过程。
(8)更快
YOLO 使用的是 GoogLeNet 架构,比 VGG-16 快,YOLO 完成一次前向过程只用 85.2 亿次运算,而 VGG-16 要 306.9 亿次,但是 YOLO 精度稍低于 VGG-16。Draknet19 YOLO v2 基于一个新的分类模型,有点类似于 VGG, 在 ImageNet 上达到 72.9% top-1 精确度,91.2% top-5 精确度。
(9)更强
在训练的过程中,当网络遇到一个来自检测数据集的图片与标记信息,那么就把这些数据用完整的 YOLO v2 loss 功能反向传播这个图片。当网络遇到一个来自分类数据集的图片和分类标记信息,只用整个结构中分类部分的 loss 功能反向传播这个图片。
分类数据集是一种多标签的模型来混合数据集
(10)Hierarchical classification, Datasets combination with wordtree
WordNet 的结构是一个直接图表(directed graph),而不是树型结构。因为语言是复杂的,狗这个词既属于‘犬科’又属于‘家畜’两类,而‘犬科’和‘家畜’两类在 WordNet 中则是同义词,所以不能用树形结构。
(11)Joint classification and detection
作者的目的是:训练一个 Extremely Large Scale 检测器, 训练的时候使用 WordTree 混合了 COCO 检测数据集与 ImageNet 中的 Top9000 类,混合后的数据集对应的 WordTree 有 9418 个类。另一方面,由于 ImageNet 数据集太大了,作者为了平衡一下两个数据集之间的数据量,通过过采样(oversampling) COCO 数据集中的数据,使 COCO 数据集与 ImageNet 数据集之间的数据量比例达到 1:4。
YOLO9000 的训练基于 YOLO v2 的构架,但是使用 3 priors 而不是 5 来限制输出的大小。当网络遇到检测数据集中的图片时则正常地反方向传播,当遇到分类数据集图片的时候,只使用分类的 loss 功能进行反向传播。同时作者假设 IOU 最少为 0.3。最后根据这些假设进行反向传播。
yolo v3算法:
YOLOv3 在 Pascal Titan X 上处理 608x608 图像速度可以达到 20FPS,在 COCO test-dev 上 [email protected] 达到 57.9%,与RetinaNet(FocalLoss论文所提出的单阶段网络)的结果相近,并且速度快 4 倍.

YOLOv3 在实现相同准确度下要显著地比其它检测方法快。时间都是在采用 M40 或 Titan X 等相同 GPU 下测量的。
改进之处:
1.多尺度预测 (类FPN)
2.更好的基础分类网络(类ResNet)和分类器 darknet-53,见下图
3.分类器-类别预测:
推荐:https://blog.csdn.net/guleileo/article/details/80581858
https://blog.csdn.net/m0_37192554/article/details/81092514
https://blog.csdn.net/zxyhhjs2017/article/details/83013297
SSD 算法:
SSD 将输出一系列 离散化(discretization) 的 bounding boxes,这些 bounding boxes 是在 不同层次(layers) 上的 feature maps 上生成的,并且有着不同的 aspect ratio。
SSD 相比较于其他单结构模型(YOLO),SSD 取得更高的精度,即是是在输入图像较小的情况下。如输入 300×300 大小的 PASCAL VOC 2007 test 图像,在 Titan X 上,SSD 以 58 帧的速率,同时取得了 72.1% 的 mAP。SSD 在保证精度的同时,其速度要比用 region proposals 的方法要快很多。如果输入的图像是 500×500,SSD 则取得了75.1% 的 mAP,比目前最 state-of-art 的 Faster R-CNN 要好很多。
本文提出的实时检测方法,消除了中间的 bounding boxes、pixel or feature resampling 的过程;本文做了一些提升性的工作,既保证了速度,也保证了检测精度。
贡献点:
提出了新的物体检测方法:SSD,比原先最快的 YOLO: You Only Look Once 方法,还要快,还要精确。保证速度的同时,其结果的 mAP 可与使用 region proposals 技术的方法(如 Faster R-CNN)相媲美。
SSD 方法的核心就是 predict object(物体),以及其 归属类别的 score(得分);同时,在 feature map 上使用小的卷积核,去 predict 一系列 bounding boxes 的 box offsets。
本文中为了得到高精度的检测结果,在不同层次的 feature maps 上去 predict object、box offsets,同时,还得到不同 aspect ratio 的 predictions。
本文的这些改进设计,能够在当输入分辨率较低的图像时,保证检测的精度。同时,这个整体 end-to-end 的设计,训练也变得简单。在检测速度、检测精度之间取得较好的 trade-off。
本文提出的模型(model)在不同的数据集上,如 PASCAL VOC、MS COCO、ILSVRC, 都进行了测试。在检测时间(timing)、检测精度(accuracy)上,均与目前物体检测领域 state-of-art 的检测方法进行了比较。
SSD 模型的最开始部分,本文称作 base network,是用于图像分类的标准架构。在 base network 之后,本文添加了额外辅助的网络结构:
-
在基础网络结构后,添加了额外的卷积层,这些卷积层的大小是逐层递减的,可以在多尺度下进行 predictions。
推荐 :https://blog.csdn.net/u010167269/article/details/52563573
RetinaNet 算法:
https://blog.csdn.net/JNingWei/article/details/80038594
7.两阶段检测算法的发展
spp net 算法:
之前算法的局限:需要固定大小的图像输入,不同尺寸的图像需要经过crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度;从生理学角度出发,人眼看到一个图片时,大脑会首先认为这是一个整体,而不会进行crop和warp,所以更有可能的是,我们的大脑通过搜集一些浅层的信息,在更深层才识别出这些任意形状的目标。固定长度的约束仅限于全连接层。

SPP-Net在最后一个卷积层后,接入了金字塔池化层,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出。
总结而言,当网络输入的是一张任意大小的图片,这个时候我们可以一直进行卷积、池化,直到网络的倒数几层的时候,也就是我们即将与全连接层连接的时候,就要使用金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的意义(多尺度特征提取出固定大小的特征向量)。
8.详述RPN网络结构,为什么要使用3*3卷积,不实用5*5卷积,写出实现的代码
第一层是固定的3x3卷积,对所有的9个anchor来说是一样的。这个3x3卷积的感受野,映射到原图上,就是228x228的区域(VGG网络)。只有在第2层的2个1x1卷积,是分别针对不同anchor的,它们的输出通道串起来就是2k和4k这个数量了。所以,anchor的scale和ratio都只是跟1x1卷积的输出通道相关的,参数是学出来的,但输入的3x3卷积特征都是一样的。
9.详细了解cascade rcnn 网络结构,损失函数怎么在级联网络中传递,级联的结构是否共用一个feature map层
参考:https://zhuanlan.zhihu.com/p/45036212
10.怎么减少fp,特别是在一张没有gt的图像出框,怎么避免出框(产生的框都是fp)
11.了解目前检测领域的最新算法
CornerNet:Detecting Objects as Paired Keypoints
提出了一种新的目标检测方法,使用单个卷积神经网络将目标边界框检测为一对关键点(即边界框的左上角和右下角);我们消除了现有的one stage检测器设计中对一组anchors的需要;还引入了corner pooling,这是一种新型的池化层,可以帮助网络更好地定位边界框的角点。CornerNet在MS COCO上实现了42.1%的AP,优于所有现有的one stage检测器。
使用anchor box的缺点:(1)需要一组庞大的anchor boxes 在DSSD中有超过4万,在RetinaNet中有超过10万的anchor box,结果,只有一小部分anchor boxes与ground truth重叠; 这在正负样本之间造成了巨大的不平衡,减慢了训练速度以及检测的精度;(2)anchor box需要一组庞大的超参数(例如 box数量,大小以及宽高比)
cornernet是首个基于关键点的目标检测算法,它的优点是:避免了设计anchor boxes的复杂操作
本文采用的方法:
将一个目标物体检测为一对关键点——边界框的左上角和右下角。使用单个卷积网络来预测同一物体类别的所有实例的左上角的热图,所有右下角的热图,以及每个检测到的角点的嵌入向量(嵌入用于对属于同一目标的一对角点进行分组——训练网络以预测它们的类似嵌入)
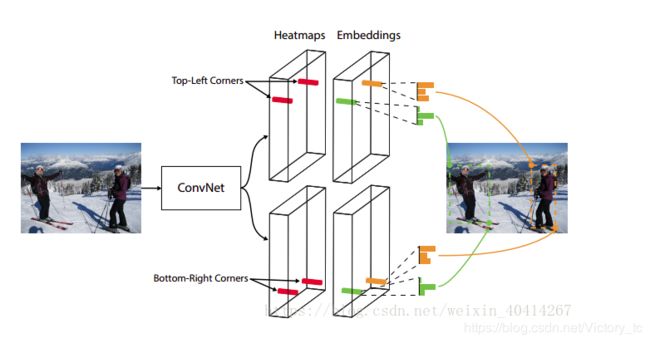
corner pooling:包含两个特征图; 在每个像素位置,它最大池化从第一个特征映射到右侧的所有特征向量,最大池化从第二个特征映射下面的所有特征向量,然后将两个池化结果一起添加。
为什么预测角点更加容易:首先,盒子的中心可能更难以定位,因为它取决于目标的所有4个边,而定位角取决于2边,因此更容易,甚至更多的corner pooling,它编码一些明确的关于角点定义的先验信息。 其次,角点提供了一种更有效的方式来密集地离散边界框的空间。
本文是第一个将目标检测任务定义为同时检测和分组角点的任务。另一个新颖之处在于corner pooling layer,它有助于更好定位角点。本文还对沙漏结构进行了显著地修改,并添加了新的focal loss的变体,以帮助更好地训练网络。
使用沙漏网络[28]作为CornerNet的骨干网络。 沙漏网络之后是两个预测模块。 一个模块用于左上角,而另一个模块用于右下角。 每个模块都有自己的corner pooling模块,在预测热图、嵌入和偏移之前,池化来自沙漏网络的特征。 与许多其他物体探测器不同,我们不使用不同尺度的特征来检测不同大小的物体。 我们只将两个模块应用于沙漏网络的输出。

CenterNet :Keypoint Triplets for Object Detection
不存在后处理是CenterNet类似网络一个巨大特点,也是一个非常好的优点,现有的目标检测方法在nms阶段就得浪费大量的时间。
cornernet使用了corner pooling操作定位关键点,而这个操作是基于bounding box的边界查找最值点,不能感知bounding box内部的语义信息,所以容易有误识别
参考博客:https://blog.csdn.net/diligent_321/article/details/89736598
12. 怎么提高单阶段模型的精度,怎么提高两阶段模型的速度。
13.手写box regression 推导和NMS算法
14.L1损失和L2损失的比较,以及对应正则化的比较,以及L0损失是什么,L1损失为什么可以提取稀疏的特征
15.openpose 的实现原理,PIFPAF的实现原理
16. onestage 与 two stage类别不平衡问题
什么是“类别不平衡”呢?
详细来说,检测算法在早期会生成一大波的bbox。而一幅常规的图片中,顶多就那么几个object。这意味着,绝大多数的bbox属于background。
“类别不平衡”又如何会导致检测精度低呢?
因为bbox数量爆炸。
正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就低了。
那为什么two-stage系就可以避免这个问题呢?
因为two-stage系有RPN罩着。
第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于前景类bbox,但是至少数量差距已经不像最初生成的anchor那样夸张了。就等于是 从 “类别 极 不平衡” 变成了 “类别 较 不平衡” 。
不过,其实two-stage系的detector也不能完全避免这个问题,只能说是在很大程度上减轻了“类别不平衡”对检测精度所造成的影响。
接着到了第二个stage时,分类器登场,在初筛过后的bbox上进行难度小得多的第二波分类(这次是细分类)。这样一来,分类器得到了较好的训练,最终的检测精度自然就高啦。但是经过这么两个stage一倒腾,操作复杂,检测速度就被严重拖慢了。
那为什么one-stage系无法避免该问题呢?
因为one stage系的detector直接在首波生成的“类别极不平衡”的bbox中就进行难度极大的细分类,意图直接输出bbox和标签(分类结果)。而原有交叉熵损失(CE)作为分类任务的损失函数,无法抗衡“类别极不平衡”,容易导致分类器训练失败。因此,one-stage detector虽然保住了检测速度,却丧失了检测精度。
17.D-RFCN + SNIP
18.faster rcnn的RPN具体是怎么做的?为什么使用anchor,不实用会怎么样?为什么是3种尺度,3种比例?faster rcnn 损失函数
19.anchor free的检测算法