NLP入门(三):seq2seq之GRU对齐文本和机器翻译
首先来回顾之前用到的两种seq2seq模型(sequence to sequence)
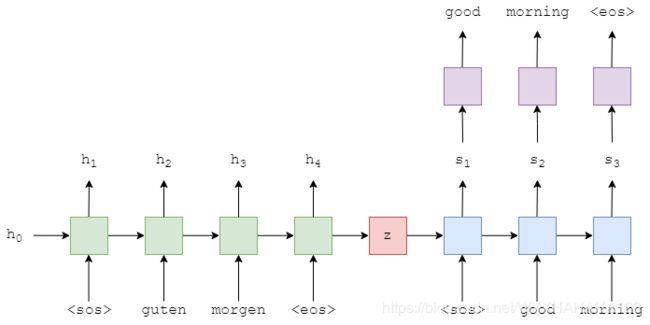
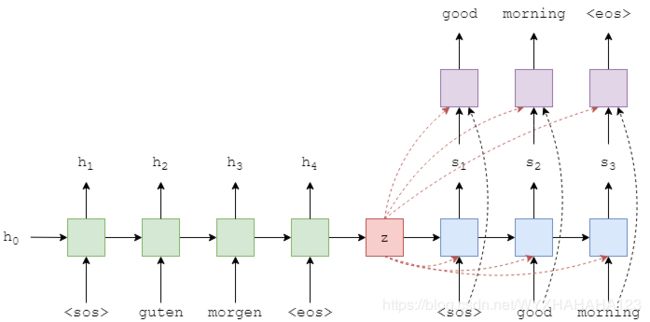
(1)和(2)编码器结构完全相同,只不过(1)使用的是单向LSTM,(2)使用的是单向的GRU,二者的重要区别在于decoder部分。看RNN的输入,要看它左边的箭头(time step时间节点)和下面的箭头(与RNN的层数相关)。
注意:编码器中时间节点t的hidden state用h(t)表示,解码器中时间节点t的hidden state用s(t)表示
(1)的解码器,当前RNN的输入包括上一时刻时间节点预测的输出单词y(t-1)和上一时间节点hidden state s(t-1),而prediction layer/线性预测层的输入为解码器当前时间节点的hidden state s(t)有关。
(2)的解码器,当前RNN的输入包括:编码器输出的context vector z,上一时刻时间节点的预测单词(或者是上一时刻时间节点的ground truth单词,由teaching force rate决定)和解码器上一层hidden state s(t-1)有关。prediction layer/线性预测层的输入为:当前时间节点的hidden state s(t),编码器的输出context vector,和上一时刻时间节点的预测单词。
但是(1)和(2)都是基于编码器输入的所有单词(input sentence sequence)中的信息都融合到了一个context vector的情况下,也就是说,这样的sequence to sequence model需要编码器输出的context vector z包含输入sentence中的所有信息。但是在解码器的具体某个时刻进行解码时,可能只需要编码器某个时间节点处的输入信息,但是它只能得到关于输入一句话的全局信息,为了使解码器在具体的某个时刻能够得到与当前时刻最为相关的信息(也就是说,要找出,编码器输入的sentence中哪个时间节点处的信息对解码出当前时间节点的单词信息量最大/最有帮助),这就需要将编码器所有时间节点处的hidden state输出(对于GRU,只有hidden state,并没有专门的cell state),然后进行加权求和,权值是与解码器当前时间节点相关联的一套数值(这个的意思是,对于解码器的每个时间节点,对于编码器所有时间节点的hidden state的加权系数是不一样的),权值即为attention vector,记作a,a的维度为编码器序列的时序长度,attention vector中每个分量的数值介于0-1之间,对于解码器的每个时间节点,a不同,但是所有时间点的权值(即向量a的所有维度)之和为1。attention vector的含义也就是:对于解码器的当前时间节点,更为关注哪个编码器时间节点的信息。用hi表示编码器第i个时间节点处的hidden state,ai表示权值系数。再次强调,在解码器的每个time step处的attention vector都是不相同的(必须是不相同的,因为解码器每个时间节点解码出来的单词需要关注编码器的信息权重是不一样的)
![]()
对于解码器的每个时间节点,将编码器每个时间节点输出的hidden state和attention vector加权求和之后,得到的w(t),t表示解码器时间节点t,将w(t)代替(2)中的context vector输入到RNN和线性预测层。(要注意的是:在解码器的第1个时间节点,输入RNN层的hidden state并不是w而是h,即编码器最后一个时间节点输出的hidden state)。
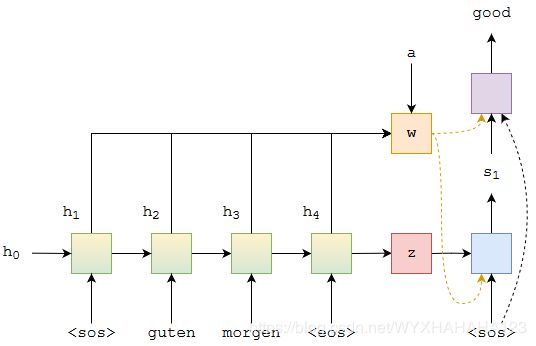
本节(NLP系列的第三小节)是基于attention的sequence to sequence model,其中,编码器使用的是双向的GRU,解码器每个时间节点的输入情况:解码器RNN输入:上一时刻解码器线性预测层的预测单词,上一时刻解码器RNN层的hidden state,经过attention vector加权求和后的w(对于当前时刻解码最为有用和corresponding的information)。解码器线性预测层的输入:w,解码器RNN当前时间节点输出的hidden state,上一时刻解码器线性预测层的预测单词。第三个小节中所描述的sequence to sequence模型实际上包含了attention机制的原始版本,即将s(t-1)作为query vector,编码器在每个时间节点输出的hidden state h(0),h(1),……h(T)作为key,然后h(0),h(1),……h(T)作为value,query vector与key之间计算的softmax概率相似度矩阵a,使用a将value进行加权求和,得到当前的w(w可以看作是编码器所有hidden state的加权求和)。这样的attention机制,编码器中的h充当了value和key的作用,并且编码器的每个h加权求和之后的w中包含h,w作为解码器每个时间节点的输入,则h的数值将会影响很多变量,这将导致h所要承载的信息太多,故而后序的key-value attention则通过对于h分别进行矩阵K和矩阵V的线性变换,得到K(H)和V(H),作为attention机制的key和value。
| output of encoder RNN | input of decoder RNN | input of linear prediction layer | |
| 原始的seq2seq(1) | 最后一个时间节点的hidden state z作为context vector | 由两部分构成:上一时刻时间节点预测的输出单词y(t-1)和上一时间节点hidden state s(t-1) | 解码器当前时间节点的hidden state s(t) |
| (2) | 最后一个时间节点的hidden state z作为context vector | 编码器输出的context vector z,上一时刻时间节点的预测单词y(t-1)和解码器上一层hidden state s(t-1) | 当前时间节点的hidden state s(t),编码器的输出context vector,和上一时刻时间节点的预测单词y(t-1) |
| 基于attention的(2) | 编码器每个时间节点的hidden state,最后一个时间节点的hidden state z(仅仅作为解码器第1个时间节点的hidden state输入) | context vector w(由解码器当前时间节点所特定的attention vector和编码器所有时间节点的hidden state加权求和),上一时刻时间节点的预测单词y(t-1)和解码器上一层hidden state s(t-1) s(-1)=z(编码器最后一层hidden state) |
context vector w,上一时刻时间节点的预测单词y(t-1)和解码器当前层hidden state s(t) |
一、编码器encoder
二、attention layer

三、解码器decoder

#coding=gbk
'''
在google浏览器的GitHub主页上加载 ipython文件的时候,总是会报错
Sorry, something went wrong. Reload?
解决方法如下:https://github.com/iurisegtovich/PyTherm-applied-thermodynamics/issues/11
'''
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import random
import math
import os
import time
import torch.nn.functional as F
SEED = 1
random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
SRC = Field(tokenize=tokenize_de, init_token='', eos_token='', lower=True)
TRG = Field(tokenize=tokenize_en, init_token='', eos_token='', lower=True)
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'), fields=(SRC, TRG))
SRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data), batch_size=BATCH_SIZE, device=device)
class Encoder(nn.Module):
def __init__(self,input_dim,emb_dim,enc_hid_dim,dec_hid_dim,dropout):
'''
:param input_dim: 应该等于编码器词汇表中的单词个数
:param emb_dim: 对之前的索引值进行embedding之后的特征向量维度
:param enc_hid_dim: 编码器RNN 隐藏层向量维度
:param dec_hid_dim: 解码器RNN 隐藏层向量维度
:param dropout: 以一定probability将输入tensor中的数值变成0
引入解码器的维度是因为,在本小节中编码器使用的单层bidirectional GRU,而
解码器使用的是单层单向的GRU,故而编码器输出的hidden state要转换成解码器
的s(0)即解码器第0个时间节点处的隐藏层状态输入,需要额外的参数
'''
super().__init__()
self.input_dim=input_dim
self.emb_dim=emb_dim
self.hid_dim=enc_hid_dim
self.embedding=nn.Embedding(input_dim,emb_dim)
#共有input_dim*emb_dim个可学习的参数
#nn.Embedding的输入必须是 sent length,batch size
#output shape sent length,batch size,emb_dim
#这一点在decoder部分要特别注意,要求解码器每次输入embedding的tensor必须是shape [1,batch size]
#embedding 模块中的可学习参数数量仅仅与特征向量的维度有关,与batch size大小无关
self.dropout=nn.Dropout(dropout)
#nn.Dropout的输入就是一个torch.tensor shape任意
#dropout方法的作用就是让tensor中的数值以一定的概率变成0
#nn.Dropout模块中并不包含任何learnable parameters
self.rnn=nn.GRU(emb_dim,enc_hid_dim,num_layers=1,bidirectional=True)
#现在使用的是双向的GRU
self.fc=nn.Linear(2*enc_hid_dim,dec_hid_dim)
#将双层GRU编码器输出的hidden state转换成单层解码器GRU第1个时间节点输入的hidden state
def forward(self, src):
'''
:param src: [src sent length, batch size]
:return:
'''
embedded=self.dropout(self.embedding(src))
#embedded = [src sent length, batch size, emb dim]
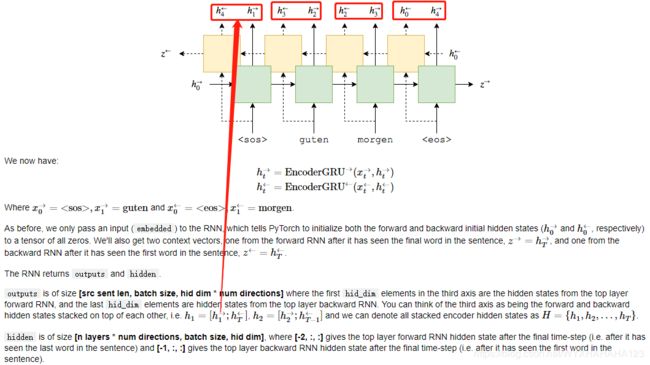
outputs,hidden = self.rnn(embedded)
#outputs = [src sent length, batch size, n_directions*hid dim]
#hidden =[n_directions, batch size, hid dim] n_directions=2
#注意:编码器中的双向GRU,其中的forward流和backwards流之间并不存在任何的信息交互
#forward流:将句子正向的每个单词输入GRU,分别得到每一个时间节点处的hidden state,h(forwward,t)和最后一层的z(forward)
#backward流:将句子reverse,再将每个单词输入(另一套参数的)GRU,分别得到每一个时间节点处的hidden state,h(backwards,t)和最后一层的z(backwards)
#只是说使用双向GRU之后,要将forward流和backward流所得到的每个时间节点处的hidden state输出
#outputs 输出的组成形式
# [h(forwward,1), h(backwards,T),h(forwward,2), h(backwards,T-1), ……h(forwward,t),h(backwards,T-t+1),h(forwward,T), h(backwards,1)]
#hidden 输出的组成形式
#[h(forwward,T), h(backwards,T)
hidden2=torch.tanh(self.fc(torch.cat((hidden[-1,:,:],hidden[-2,:,:]),dim=1)))
hidden=hidden.permute(1,0,2).contiguous().view(hidden.shape[1],-1)
#hidden = [batch size,n_directions*hid dim]
hidden=torch.tanh(self.fc(hidden))
#hidden = [batch size,dec_hid_dim] 解码器第0时刻输出的隐藏层状态 hidden state
print(torch.sum(hidden-hidden2),'my s(0) and web s(0)')
return outputs,hidden
class attention(nn.Module):
def __init__(self,enc_hid_dim,dec_hid_dim):
super().__init__()
self.attn=nn.Linear(enc_hid_dim*2+dec_hid_dim,dec_hid_dim)
self.v=nn.Parameter(torch.rand(dec_hid_dim))
def forward(self, hidden,encoder_outputs):
'''
:param hidden: 解码器在上一时刻输出的hidden state hidden = [1,batch size,dec hid dim]
为了得到当前t时刻的输入context vector(经过attention之后的),需要使用到解码器t-1时刻的hidden state
:param encoder_outputs:编码器输出的所有时间节点上的hidden state = [src sent length, batch size, enc hid dim*2]
:return:返回对于解码器当前节点处的attention vector = [src sent length, batch size]
'''
src_length=encoder_outputs.shape[0]
batch_size=encoder_outputs.shape[1]
encoder_outputs=encoder_outputs.permute(1,0,2)
#encoder_outputs = [batch size,src sent length,enc hid dim*2]
hidden=hidden.permute(1,0,2)
#hidden = [batch size,1, dec hid dim]
hidden=hidden.repeat(1,src_length,1)
#hidden = [batch size,src_length, dec hid dim]
energy=torch.tanh(self.attn(torch.cat((encoder_outputs,hidden),dim=2)))
'''
torch.nn.Linear的输入维度 [batch size,……,input_dim]
输出维度 [batch size,……,output_dim]
其中……表示额外的维度,也就是说nn.Linear函数支持超过two dimension的输入
只要input.shape[-1]等于nn.Linear的输入特征维度即可
'''
#energy = [batch size,src_length, dec hid dim]
# v = dec_hid_dim
v=self.v.unsqueeze(0).repeat(batch_size,1).unsqueeze(-1)
#v = [batch size, dec hid dim,1]
attention=torch.bmm(energy,v)
#attention = [batch size, src_length,1]
attention=attention.squeeze(-1)
# attention = [batch size, src_length]
return F.softmax(attention,dim=1)
class Decoder(nn.Module):
def __init__(self,output_dim,emb_dim,enc_hid_dim,dec_hid_dim,dropout,attention):
'''
:param output_dim: 解码器词汇表中的单词个数
:param emb_dim: 解码器embedding vector维度
:param dec_hid_dim: 解码器隐藏层维度
:param dropout:
'''
super().__init__()
self.output_dim=output_dim
self.emb_dim=emb_dim
self.dec_hid_dim=dec_hid_dim
self.enc_hid_dim=enc_hid_dim
self.embedding=nn.Embedding(output_dim,emb_dim)
self.dropout=nn.Dropout(dropout)
self.attention=attention
self.rcnn=nn.GRU(emb_dim+enc_hid_dim*2+dec_hid_dim,dec_hid_dim)
self.output=nn.Linear(dec_hid_dim+enc_hid_dim*2+emb_dim,output_dim)
def forward(self,hidden,encoder_outputs,input):
'''
:param hidden: [1,batch size,dec_hid_dim] s(t-1)解码器t-1时刻输出的hidden state
:param encoder_outputs: [scr sent length, batch size, 2*enc_hid_dim]
:param input:[batch size] 解码器t时刻的输入单词
:return:
'''
embedded=self.dropout(self.embedding(input.unsqueeze(0)))
#embedded = [1,batch size,emb_dim]
attention=self.attention(hidden,encoder_outputs)
#attention = [batch size, src_length]
attention=attention.unsqueeze(-1).repeat(1,1,self.enc_hid_dim*2)
#attention = [batch size, src_length,enc_hid_dim*2]
encoder_outputs=encoder_outputs.permute(1,0,2)
#encoder_outputs = [batch size,scr sent length,2*enc_hid_dim]
weighted=attention*encoder_outputs
weighted=torch.sum(weighted,dim=1)
#weighted = [batch size,2*enc_hid_dim]
#输入到GRU的信息应该是
#(1)embedded = [1,batch size,emb_dim]
#(2)hidden: [1,batch size,dec_hid_dim] s(t-1)
#(3)attention之后的context vector,weighted : [1,batch size,enc_hid_dim*2]
output,hidden = self.rcnn(torch.cat((embedded,hidden,weighted.unsqueeze(0)),dim=2))
#output = [sent length,batch size,n_layers*n_directions*hid dim]
#hidden = [n_layers*n_directions,batch size,hid dim]
#output = [1,batch size,dec_hid_dim]
#hidden = [1,batch size,dec_hid_dim]
#当只有一个时间节点时,output = hidden
print(torch.sum(output-hidden),'output-hidden time-step=1')
#送入到prediction输出层的information:
# (1)embedded = [1,batch size,emb_dim]
# (2)hidden: [1,batch size,dec_hid_dim] s(t)
# (3)attention之后的context vector,weighted : [1,batch size,enc_hid_dim*2]
pred=self.output(torch.cat((embedded.squeeze(0),hidden.squeeze(0),weighted),dim=-1))
#pred = [batch size,output_dim]
return hidden,pred
class seq2seq(nn.Module):
def __init__(self,encoder,decoder,device):
super().__init__()
self.encoder=encoder
self.decoder=decoder
self.device=device
def forward(self, src,trg,teaching_force_rate):
'''
:param src: [src sent len, batch size]
:param trg: [trg sent len, batch size]
:param teaching_force_rate: 0.75
:return: prediction
'''
outputs, hidden=self.encoder(src)
# outputs = [src sent length, batch size, 2*enc hid dim]
# hidden = [batch size, dec hid dim]
input=trg[0,:]
hidden=hidden.unsqueeze(0)
#input = [batch size]
#hidden = [1, batch size, dec hid dim]
predictions=torch.zeros((trg.shape[0],trg.shape[1],self.decoder.output_dim))
# predictions = [trg sent len, batch size, output_dim]
for t in range(1,trg.shape[0]):
hidden,pred=self.decoder(hidden, outputs, input)
# hidden: [1,batch size,dec_hid_dim]
# pred = [batch size,output_dim]
# pytorch中的unsqueeze和squeeze操作都不是in-place的
predictions[t, :, :] = pred
pred=torch.max(pred,dim=1)[1]#pred=[batch size]
teaching_force=random.random()>teaching_force_rate
input=trg[t,:] if teaching_force else pred
return predictions
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
ENC_HID_DIM = 512
DEC_HID_DIM = 512
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
attn = attention(ENC_HID_DIM, DEC_HID_DIM)
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)
model = seq2seq(enc, dec, device).to(device)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
optimizer = optim.Adam(model.parameters())
pad_idx = TRG.vocab.stoi['']
criterion = nn.CrossEntropyLoss(ignore_index=pad_idx)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
# trg = [trg sent len, batch size]
# output = [trg sent len, batch size, output dim]
output = output[1:].view(-1, output.shape[-1])
trg = trg[1:].view(-1)
# trg = [(trg sent len - 1) * batch size]
# output = [(trg sent len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) # turn off teacher forcing
# trg = [trg sent len, batch size]
# output = [trg sent len, batch size, output dim]
output = output[1:].view(-1, output.shape[-1])
trg = trg[1:].view(-1)
# trg = [(trg sent len - 1) * batch size]
# output = [(trg sent len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 10
CLIP = 1
SAVE_DIR = 'models'
MODEL_SAVE_PATH = os.path.join(SAVE_DIR, 'tut3_model.pt')
best_valid_loss = float('inf')
if not os.path.isdir(f'{SAVE_DIR}'):
os.makedirs(f'{SAVE_DIR}')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), MODEL_SAVE_PATH)
print(f'Epoch: {epoch + 1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
The model has 21,305,349 trainable parameters
Epoch: 01 | Time: 16m 13s
Train Loss: 4.285 | Train PPL: 72.626
Val. Loss: 2.764 | Val. PPL: 15.871
Epoch: 02 | Time: 16m 10s
Train Loss: 3.132 | Train PPL: 22.911
Val. Loss: 2.318 | Val. PPL: 10.151
Epoch: 03 | Time: 16m 34s
Train Loss: 2.681 | Train PPL: 14.593
Val. Loss: 2.151 | Val. PPL: 8.594
Epoch: 04 | Time: 16m 2s
Train Loss: 2.399 | Train PPL: 11.008
Val. Loss: 2.073 | Val. PPL: 7.950
Epoch: 05 | Time: 18m 25s
Train Loss: 2.195 | Train PPL: 8.979
Val. Loss: 2.038 | Val. PPL: 7.678
Epoch: 06 | Time: 20m 3s
Train Loss: 2.057 | Train PPL: 7.826
Val. Loss: 2.007 | Val. PPL: 7.437
Epoch: 07 | Time: 21m 3s
Train Loss: 1.909 | Train PPL: 6.746
Val. Loss: 1.998 | Val. PPL: 7.372
Epoch: 08 | Time: 20m 50s
Train Loss: 1.814 | Train PPL: 6.133
Val. Loss: 1.994 | Val. PPL: 7.343
Epoch: 09 | Time: 20m 28s
Train Loss: 1.717 | Train PPL: 5.565
Val. Loss: 2.014 | Val. PPL: 7.492
Epoch: 10 | Time: 21m 1s
Train Loss: 1.653 | Train PPL: 5.224
Val. Loss: 1.999 | Val. PPL: 7.383