饮水思源--浅析深度学习框架设计中的关键技术

点击上方“深度学习大讲堂”可订阅哦!
编者按:如果把深度学习比作一座城,框架则是这座城中的水路系统,而基于拓扑图的计算恰似城中水的流动,这种流动赋予了这座城以生命。一个优雅的框架在保证城市繁荣的同时,还能让这座城市散发出独特的魅力,使它保持永恒的生命力。本文中,年仅22岁的开源框架Dragon的设计者、中科院计算所博士研究生、中科视拓实习算法研究员潘汀,将结合独立开发深度学习框架的经验,介绍框架设计中的关键技术,并给出其发展趋势的简单分析。文末将分享讲者自己设计的开源框架:Dragon。
以下是本文作者在CCML2017-深度学习Tutorial上分享的报告:


在去年的CES展会上,英伟达CEO黄仁勋,放了这样一张图,上面列了近几年学术界工业界的一些杰出框架,并称赞这些框架是当代AI发展的引擎。

虽然略有广告之嫌,但深度学习框架确实是相当重要的。这体现在以下两个方面:
从工程性上来说,无论是工业界还是学术界都需要可靠的框架来支持计算量庞大的实验;
从学术性上来说,以深度学习为主的论文每周都有大量的更新,如果没有框架:
(1)一周内不可能复现完世界上各大研究组的工作
(2) 会议的deadline截止了,实验还没有跑完
MXNet框架作者之一的李沐博士曾经开过这样的玩笑:“我们这一群曾经一起写框架的小伙伴,如今都年薪百万了。”这间接体现了框架开发和维护人才的稀缺。

放眼Github,明明已经有那么多优秀的框架了,那么为什么我们还需要自己写框架呢?

这里就有俩种不同的声音了:
第一种声音来自地平线机器人的余凯博士,他曾公开表示对以TensorFlow为主的框架产生的垄断效应而产生担忧。
与之相对的是,LSTM作者之一的Schmidhuber教授在ICML15上的观点:AI研究的代码是非常自由,我们并非一定要局限使用固定的代码来源,总有人不喜欢TensorFlow,这就是它难以垄断的根本原因。
所以,无论是否会产生框架垄断,AI研究者都必须刻苦钻研代码技术,这才是最重要的。

以上是我今天报告的主旨。下面我将从4个方面,结合独立开发框架的一些经验,介绍目前深度学习框架设计中最新的一些关键技术。


框架设计界目前有两大阵营,命令与声明式,可以根据是否使用计算图来划分它们。基于计算图的声明式框架,需要先假设完整的模型,再对模型进行一次性求解。相反,不使用计算图的命令式框架,如其名,只能逐步求解了。
下面这张表列出了两个阵营的战力对比,我们可以看到,自2012年后,绝大多数深度学习框架都选择了基于计算图的声明式求解。
这并不是什么巧合,计算图表示本身是优雅的,它携带的上下文拓扑关系允许我们结合领域知识对组合运算做进一步优化。

计算图这个概念大家现在基本是比较熟悉了,它本质就是一个有向无环图。
那么为什么这么一个简单的小小有向无环图就能用于大部分基础表达式建模呢,这里列出两种较为广泛使用的观点:
(1) 表达式计算具有拓扑先后性,这意味着图的有向遍历可以用来建模表达式。
(2) 最早来自Bengio教授在著名的《Learning deep architectures for ai》文章中的观点,也就是神经网络是天然的有向图,注意这里是可以带环的,我们可以使用一些小技巧把环去掉。
同时注意到,这篇文章也是Theano框架的开发的参考之一,它也成为第一个基于计算图的深度学习框架。

传统的深度学习框架通常是双向的执行逻辑,它们使用Layer这种粗粒度的抽象结构,前向传播时,执行一个从0开始的递增循环。反向传播时,倒过来做一个递减循环。

这种多次执行的逻辑实际上是与有向图计算思想相悖的。有向图计算倡导的是”一波流“,控制逻辑简洁、简单,而Layer级别的抽象很难做到这一点。
让我们换一个思路,把一个”层“拆解成两个符号,一个做前向,一个做反向,前向后面接着反向,这样整个计算图就避免了先后循环两次的问题。
以TensorFlow为主的框架通常并不倡导这种中间断裂执行的逻辑,这使得早期一些深度可视化工作难以复现。在这一点上,通常会有两种解决方案:
(1) MXNet的做法很简单,仍然保持前反向的双逻辑,只是分段执行图的不同部分。
(2) 我们的工作受到了Caffe(1)的启发,允许图在执行时动态引入包含/排除规则,因此可以根据需求,划分任意的部分图执行逻辑。
使用Layer这种粗粒度结构所导致的另一个问题是反向传播的贡献分析过程码农化。经典的例子是Caffe(1)中的暴力模拟做法:
(1) 首先定义一个集合,用于插入对损失有贡献的Blob。
(2) 由损失开始反向倒退,根据本层输出是否被”贡献“,判断本层是否需要反向计算
(3) 在逐层倒推的过程中,不断的更新贡献集合。
而我们的做法非常简单,借助简单图遍历染色,仍然可以在线性时间复杂度内完成贡献分析。

要支持灵活的图遍历染色,首先我们要将原本粗大笨重的Layer给分解掉。链式法则的拓扑性非常优美,它是一个经典的后入先出FIFO逻辑。
如图,我们可以直接在正向过程后,对称地展开反向过程。
在得到这样的完全展开图后,我们需要对符号结点所辖的输入输出结点,(这里我们用张量结点来描述它们),做一些约束:
首先我们定义源点和汇点,源点可以是任意是用户指定的数据输入点,而汇点,通常是以下三种:用户指定的中间求解点、目标函数结点,以及偏导数结点。
连通路是图遍历的基本需求,前向过程中的连通路可以由表达式或者神经网络结构确定,而反向过程中连通路,根据链式法则及对应符号的计算规则即可自动生成。

预先生成的大量连通路通常是冗余的,这时候就需要对朴素的计算图进行剪枝。
这张图来自去年的微软雷德蒙德研究院讲座,两位作者分别是陈天奇博士,解浚源博士,他们是MXNet框架的两位主要作者。
这里列出了常见三种计算图的优化,图的依赖性剪枝,符号融合,以及内存共享。除了符号融合外,其余两种都可以用非常简洁的代码实现,是我们本次我们讨论的重点。

图的依赖性剪枝是我们需要首先考虑的问题。前向传播过程中的剪枝较为简单,如图,假设我们同时计算两个A+B问题,输出分别为X和Y,那么最简单的做法就是由X,Y开始,沿父结点方向遍历染色,未染色结点则一定不是求解目标所依赖的。

这是完整的算法,为了实现简洁,我们只采用了深度优先遍历。

反向传播的剪枝较为复杂,首先我们来看左图,通常这是自动生成的全导关系。假设用户只需要求输出X关于输入A的偏导,输出Y关于B的偏导,从dA或dB沿着父节点遍历一定会污染到不相关的求解链式上,因为它们默认是连通的。

这个问题可以等价成寻找在各个结点上的最优子结构,与最短路不同,这里我们将依赖边数目定义为代价。朴素算法时间复杂度是指数级的,我们可以借助动态规划在线性时间复杂度内实现它。
具体来说,首先我们定义一个三状态的动规标记,记录当前结点x的访问情况。
状态0表示该结点未访问,状态1表示该结点已访问,但其子孙结点与当前指定的目标结点都不连通。最后状态2则表示其子孙结点目标结点连通。
当搜索至任意结点时,若状态为0,显然未访问,继续搜索。若状态为1,则后续结点与目标节点不连通,代表已无继续搜索必要。若状态为2,它将被后续结点依赖,我们再把其记录的已搜索的路径和后续路径进行合并。

该动规算法可以保证每个结点只被访问一次情况下,完成所有偏导关系的剪枝。

除剪枝外,另一种常见优化就是原位替换。这里考虑一种三个ReLU函数连续的极端情况,通常情况下,除了输入A之外,我们会得到B,C,这两个中间量,以及D这个最终目标量,需要开4倍的内存。但如果我们开启原位替换,结合ReLU函数的特性,不断擦写输入,最终只需要A这个量本身。

实现原位替换最简单的方式是重命名。需要先假设任意结点为祖先结点,搜索一条符合替换规则的最长链。那么该链上所有结点都可以重命名为祖先结点。
基本的替换规则适用范围并不广,这里我们提供一个较为简单的,它需要如下特定结构:
-
孩子结点数量仅为1,这是一个基础规则
-
所属符号支持替换模式,这是一个附加规则,可通过类似Caffe2的OpSchema来获取。
顺便我们来回忆一下Caffe(1)中原位替换,它需要人工设置,比较灵活。
这里使用的自动推导方式,虽然只能处理一些简单的符号,但还是很好用的。
在计算图框架的设计中,可以根据需要二选一。因为原位替换将导致图带环,导致无法剪枝。

搜索原位替换结构略微费时,因为每个结点可能在多次搜索中被遍历,但单次搜索长度是有限的,范围在3~5左右,我们仍然认为它是线性的时间复杂度。

结合上面的一些技巧,我们可以完成一个自动求导的小应用。首先回忆一下Caffe(1)中模拟链式法则计算的一个小技巧:
-
各层编写一个逐元素计算梯度的函数
-
然后自顶向下依次执行即可
如何用这种计算思想山寨一个类似Theano中使用的自由求导函数呢?很简单,只需要三步:
1)生成全导关系的图定义
2)收集用户指定的所有偏导关系二元组
3)根据偏导关系及上文的反向传播剪枝算法移除不相关的计算链
这是我们的框架使用的自动求导策略,实现起来并不是困难。
如果说计算图表示及其优化是一个框架的骨架,那么内存优化就是其血肉。传统框架通常轻视,甚至忽略这一步,随着深度学习越搞越深,这些框架的发展也步履维艰。


典型的例子是Caffe(1),这个框架实际上基本没有任何内存优化,现在我们更多是拿它作为一个无优化的基准。其自身架构缺陷导致了以下两个很严重的内存问题:
第一, 卷积缓冲区的重复申请。单次GEMM卷积临时变量其实不是很大。但在深度堆叠结构里面,这就很要命了,以16层VGG16网络为例,这些重复的缓冲区累积起来大概会多占用3G显存。通常多个卷积层计算不是并发的,那么是否可以共享它们?
第二, 交叉验证过于昂贵。由于设计缺陷,训练网络和验证网络内存是完全隔离的。这就等于我们直接同时运行了2个网络。通常训练过程和验证过程不是并发的,那么是否可以共享它们?

针对C1薄弱的内存管理,C2在设计之初就引入了全新的管理结构——工作区机制。
工作区是一个全新的内存托管平台,常规的Blob的申请只能通过它来完成。每一段内存都有唯一的”键“进行实名制管理。工作区之间的内存是隔离的,这为自动并行提供可能。此外,工作区直接向Python前端暴露,规范了PyCaffe混乱的内存访问与修改。
工作区并不是什么新鲜设计,实际上就是工程领域很常见的MVC编程结构,通过它,数据和业务逻辑得到分离。用于改正在Net或者Layer开内存的这样的坏习惯。

利用工作区,可以很轻易的实现GEMM卷积的缓冲区共享。我们在测试中发现,该实现在输入图像尺寸不大的情况下,占用显存甚至比cuDNN实现还要少。

梯度回收是目前另一种普遍使用的内存优化。它利用了梯度结点优雅的特性:入度不定,出度为1,这意味着梯度是可以”阅后即焚“的。
入度不定的通常解决方案是梯度分支求和合并,C1扔在了SplitLayer中处理,C2则直接自动追加了一个求和符号。当我们合并了各分支梯度后,一个非常重要的优化是立即释放分支,否则在长时序的RNN中,会导致巨额的瞬时内存开销。
出度为1是一个巨大诱惑,这意味这我们是可以直接擦写其内存的。释放它或者留给前一层梯度计算使用都可以。回收梯度可使训练内存仅为基准的50%,而速度只下降15%~20%,这是一个非常划算的时间换空间买卖。但缺陷是全局的中间梯度都被破坏,难以进行调试。
针对这个问题,我们引入调试模式。通过检查用户是否设置调试标志位,以确定回收函数是否开启。

优雅地回收需要一些技巧。这里我们通过引入”缓冲区回收栈”来完成它。缓冲区在大多数符号设计中都是必要的,有趣的是,我们回收的梯度也可以直接用于缓冲区。
我们使用栈来存储可被使用的缓冲区,同时默认设定栈容量为3. 这个数字也很有意思,cuDNN的卷积默认会需要2个,而梯度租用也需要一个。栈的特性是后入先出,我们用它来维护临近使用缓冲区的大小稳定,避免频繁释放和顺次申请。
回收“栈”仍然也交给工作区托管,跨符号或层可共享使用。

2015年提出的ResNet是个好东西,但是跑起来却是一个灾难。首先,ResNet的极深,大量的中间输出是难以释放的,加上稍大的batchsize之后,整个网络对内存的要求极其恐怖。相比之前的没显卡就买显卡方案,我们现在得加上“买更大的显卡”选项。
优化ResNet也是非常简单的。早在1年前,Torch的Blog就给出了下面的几个方案:包括使用cuDNN版的BatchNorm,回收梯度,原位替换残差分支的加法。这些小技巧能够极大减少ResNet的门槛。

将它们全部应用之后,ResNet就显得非常亲民了。很有意思的是,MXNet和TensorFlow的结果和这个是非常接近的。

更进一步的内存优化,这里我们称之为极限内存优化,目前并没有被多数框架采用。其主要思想是丢弃前向计算中的中间结果,在反向传播需要时,重新计算它们。比如经典的卷积+BN+ReLU结构,由于BN和ReLU算的比较快,直接擦写其中间结果也是可行的。几天前在arXiv放出DenseNet显存优化就使用该方案。
广义上来看,这涉及到一个时间空间均衡问题。我们可以贪心地保留时空比较高的结果。具体一些细节可以参考MXNet的memonger库,及在arXiv上对应的论文。
有了骨架和血肉,我们还得给框架注入新的智慧。


目前框架设计的一个争论点是,梯度的求解函数到底放哪?以C1,MXNet为主的框架主张放在同符号类中,以forward和backward区别。以C2,TensorFlow为主的框架则主张放在异符号类中,不区别。
那么为什么要分离出梯度计算过程呢?这里列出我的几点思考:
第一, 部分符号根本不存在梯度求解
第二, 自定义符号可能需要终止梯度(如RCNN中的PythonLayer)
第三, 强制终止梯度(如TensorFlow中的梯度停止算符)
第四, 最重要的是,这样可以提供最完整的链式求导编程体验。

我们可以从Caffe2全新的符号设计中观察到,原本捆绑式的输入/参数结构被移除,取而代之的是算符及其操作数,这极大的规整了原先混乱且含糊的计算表示。

这是一个卷积层拆解的简单例子,对于每个算符而言,输入即是常量,输出即是变量,多余的表示不存在,也自然不可能被用到,更不可能被用错。

通常前向计算中会产生一些中间资源,当前反向计算分离时,如何传递它们便成了一个新的问题。为此,我们引入锚点机制,在前反向符号间建立用于哈希的锚点,这些锚点可用于直接从工作区中拉取已计算资源。与Caffe2直接将其混入操作数相比,我们的方法既维持了符号编程接口的简洁,又模拟了与Caffe1近似的编程体验。
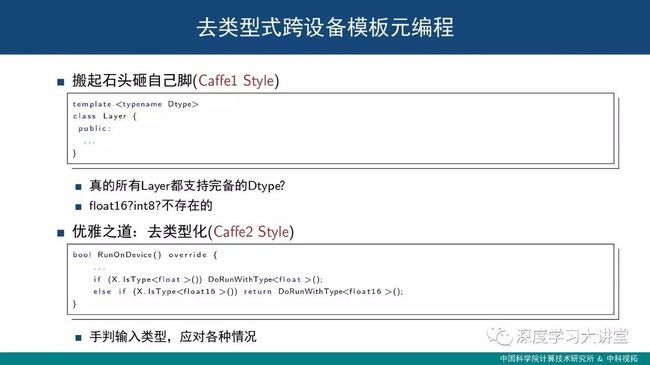
几年前,我们很难想象深度学习竟可以适应半精及更低的精度,带类型的模板元编程曾经是众多框架争相模仿的设计,如今,计算设备对不同算符支持类型趋于多样化,再看带类型模板,不得不说完全是搬起石头砸自己的脚。
如果追踪Caffe2最近更新的代码,可以发现部分算符已经完全移除了类型模板,替换成了一个简单的if语句。随着明年Volta GPU架构开放更多的半精度编程接口,这种趋势将会愈演愈烈。

与之相反的,将设备用于模板逐渐成为诸多框架广泛采用的设计。符号对设备的支持通常是稳定的、全面的,利用模板,我们可以免除上图那样蹩脚的函数命名。

早期的框架都是清一色的C语言编程接口,C语言是编译语言,尽管它十分适合设计内核,但在应用和扩展上,通常捉襟见肘。与之相对的,Python,非常灵活的脚本语言,我们知道它的库不仅多的用不完,速度还快。那么为何不将两者结合起来,用C语言写纯净的计算内核,而用Python搞应用呢?
这种想法最早见于Caffe(1)中的PythonLayer,大家都觉得好用,所以现在基本是个框架都支持这种特性了。

交叉语言的引入,意味着内核将会在C语言端和Python端跳跃执行。基于此的经典案例就是用于语义分割的FCN以及用于目标检测的RCNN。我们的工作还发现,Python端非常适合用来做多进程的数据缓冲,为此,我们在内核中移除了所有数据库及OpenCV代码,仍然可以满足ImageNet分布式训练的IO需求。
从符号层面,我们已经看到现有框架在设计上已经各种“撞车”了。


这些框架大多都需要繁琐的编译配置,但功能基本是相似的。接口设计的不同导致学习成本和配置成本很高。
Keras框架似乎可以解决这个问题,但真的看起来这么简单吗?

仔细分析这个封装框架,就会发现它是没有自己内核的,仅仅依靠自身引入的新接口来将执行引导至多个内核上。这是一个很严重的问题,因为相同的调用,在多个内核上的结果可能是不同的,我们并不能保证TensorFlow的执行结果和Theano执行结果完全一致。
此外,它的封装层次过于复杂,调试非常困难,既不适合学术界,也不适合工业界。

为了消除多个框架之间的分歧,另一种可行方案就是中间表示。早在20年前,这个思想就已经在编译器界流行,于2000年诞生的LLVM项目,就成功利用中间表示,将跨语言的多个编译器整合至共同的编译方案中。
20年后,再看我们这些深度学习框架,也大量使用了类似的中间表示,是不是有种殊途同归的感觉?
中间表示带来的优势是明显的,从硬件层面来说,有望在跨计算设备上实现计算内核的自动生成,并且更紧地结合编译器做一些上下文的优化。从软件层面来说,中间表示可用于表示拓扑连接,与工厂模式结合后,便形成了今天大多数框架都采用的组件化符号编程。

对计算图做虚拟化,便得到了计算图虚拟机。这是一个很有意思的工作,以我们的SeetaDragon框架为例,既不需要安装上述框架,也不用担心混合使用它们的冲突。
对于研究者来说,最贴心的,莫不是使用最熟悉的框架来编程了。当模型被快速建立后,将会转换成内核执行的确定中间表示,对于开发者而言,定位到内核上确定的调试点并不困难。由中间表示发布或是部署这些代码,模块间的代码冗余可以得到控制,几乎没有移植成本。
基于计算图虚拟机,便可将这三者天然结合在一起。 除我们之外,同期还有一些的近似工作,比如,DMLC深盟基于MXNet的NNVM,Intel基于Nervana的NervanaGraph,脸书的Caffe2结合PyTorch的双子星框架战略。

这是一张由我们内核互通三个框架后的架构图,Bengio教授曾以组合子函数构建新函数来类比深度神经网络,如果将其倒过来,用神经网络来类比子函数构建新函数,子框架构建新框架,似乎也是合理的。既然深度优势可以让模型大量减少参数,那么也同样可以减少虚拟机中各框架间的代码重叠度。

超越计算图后,虚拟化也可以延伸至符号设计上,但这将更多地涉及设备和编译器。未来的几年内,我们可以预见更多在符号虚拟化上的工作,框架的设计难度,也将随之超出个人可以维护的范畴。

希望以上内容,能够对大家在学习框架过程中有所帮助。编写一个自己使用的框架,也许只需要一个月,但维护和扩充它可能需要数年。报告中没有涉及的三点:架构精简、算符扩充、以及分布式训练,都需要投入更多的时间去研究。
需要强调的是,无论框架如何演化,如何利用它们做出有用的工作,才是最重要的。但也不能完全不关心它们的发展,在这一点上,MXNet主要作者,解浚源博士在知乎上的回答则发人深省:无论你想做深度学习还是深度学习系统,都需要同时了解两方面的知识,否则很难做出在实践中有用的成果。

我们的工作已经在Github上放出:https://github.com/neopenx/Dragon
Dragon是一个非常轻量的计算图虚拟机框架,欢迎大家贡献PR。
致谢:

本文主编袁基睿,诚挚感谢李珊如对本文进行了细致的整理工作。

该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
作者信息:
作者简介:

潘汀,中科院计算所2017级博士生,导师山世光研究员。主要研究兴趣为目标检测技术与深度学习框架设计,目前独立开发与维护基于计算图的多重虚拟化深度学习框架Dragon。
往期精彩回顾
VALSE2017系列之八: 物体识别与物体知识表征的认知神经基础
Seeta看AI:从大数据驱动到x数据驱动
VALSE2017系列之七:视觉与语言领域年度进展概述
人脸检测与识别年度进展概述
视频行为识别年度进展

欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:[email protected],想了解更多可以访问,www.seetatech.com
![]()

中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站