学了不少AI算法,竟然还不懂什么是AI项目的工程素养?
点击上方“AI派”,选择“设为星标”
最新分享,第一时间送达!

作者:Leon Wang, 现为中科院特别研究助理 (博士后),国内某软件行业领头企业 AI 部技术负责人,在 AI、数据科学和科学计算等方面相关的工程实践上积累了丰富的经验。 编辑:王老湿
大家好,从今天开始,《AI炼丹炉工程实践指南》专栏就正式开始更新了(专栏整体介绍见:算法原理稳如狗,工程落地慌得很!AI炼丹炉实践指南来啦~)。今天的内容是先和小伙伴们聊聊本专栏要讨论的核心问题 —— AI 项目的工程素养。到底什么是 AI 项目的工程素养呢?
前述
今天这篇文章是该专栏系列文章的第一篇正文,在这里我先不谈非常具体的一些技术细节,主要先谈谈我对 AI 项目相关工程素养的一些理解。后续的文章,我力争两周都有一篇发布,每篇都会谈一个 AI 相关的技术点干货文章,希望大家能喜欢。
工程素养
众所周知, AI 是目前少数能紧密联系学术界和工程界的一个领域。一方面,工程界与学术界之间的界线越来越模糊,许多工程界的专家也开始发论文,参加学术会议;同时,很多学术界的大佬也纷纷进入工程界的大厂,将自己的研究进行转换应用。由于 AI 的火热,大家都纷纷投入到 AI 领域,很多公司也开启了 “XX + AI” 的新模式, 甚至很多不那么了解 AI 的朋友认为搞 AI 非常简单,只要从 Github 拉一份代码下来就能马上搞定。
那么,是否 AI 相关工程的落地真的如此容易了吗?
按照作者的经验,AI 看起来很美好,但实际落地时的工程坑何止千百种,特别是在需要把 AI 功能做集成到自己的软件中。不知道大家有没有碰过以下几种很纠结或很困惑的情况?
从网上下来一份 AI 项目的 Python 代码后,却不知道这个项目依赖什么库才能正常运行。
依赖库安装好了,程序能运行了,但发现有很多问题,费了很久的功夫才了解手头的代码已经过时。
用 Matlab 开发了一个不错的模型,但老板想换成 C++ 来发布产品,结果你惊奇的发现自己的 C++ 代码版本的运行速度竟然还不如 Matlab的快。
课题组或部门配置了可以远程链接的 AI 服务器,但在Windows 和 Pycharm 下运指如飞的你发现,在那黑漆漆的命令窗口里,以往的流畅开发变得寸步难行。
临近软件发布版本,小组领导突然走过来,和正在勤奋写代码 的你强调,不要在发布版本的时候提交代码。
内部进行交接的时候,往往费尽心思写了自己认为非常全面详尽的文档,但负责交接的同事或同学好像没有看,还是问你很多文档上的问题,并对你的工程项目结构完全不能理解,你开始觉得交接文档并不管用。
我相信有不少刚开始学习 或应用 AI 的朋友们多少会碰到以上类似问题。我这里大概总结成几个方面:依赖环境、版本管理、工程代码基础、Linux基础和运行环境的交付等几个方面。这些方面不仅仅是初学 AI 的朋友可能会比较头疼,就是一些刚开始建立 AI 研发部门的企业,或者刚进入 AI 工程界的朋友也很容易遇到。下面我就这些方面谈谈我对此的认识。
依赖环境
了解开源软件的朋友们可能会更熟悉,大部分工程和软件经常都需要一大堆依赖库的安装才能正常运行, 使用很多开源技术的 AI 项目也是如此。这主要因为大家一直遵循着不重复造轮子的思想(特别是国外),大家每个人只专注自己一部分核心,做专做精就好。需要用到的其他不是自己研发重点的功能,只要有人实现了轮子,我们拿来使用就好。
例如,我们在安装 Tensorflow 的时候就会注意到许多其他的包也会被安装进来。在 Python 生态里面,我们可以用原生的工具 pip 来安装一个软件包;
同样,我们也可以用 anaconda 来安装。anaconda可以简单理解为一个 特殊的 Python 集成环境,他比原生 Python 增强了依赖管理能力,特别是依赖之间的版本依存管理。后面我们会有专门的篇章分析这两种安装的方式,以及各自区别。
需要特别强调的是,最重要的依赖环境信息是 AI 项目所需要的各个依赖库的名称和版本(例如,我们可以写在requirements.txt中)。
有同学可能觉得版本不重要。很多时候我们开发时,依赖库的版本并不是最终的版本,而我们实现的某个函数可能在依赖库进行更新后就会失效,如果不对依赖环境中的依赖库版本做明确的限制,很有可能就会造成软件随着依赖库更新发生问题,软件变得十分不稳定。比如,我们在工作中还遇到了opencv-python4.x 在 win7 下运行有问题的情况,为了达到软件能直接跨平台运行,需要对版本做降级,以便让软件可以直接运行在各个操作系统中。
版本管理
什么是版本管理?
版本管理工具可以记录我们软件代码或其他纯文本文件的各种历史版本,可以支持多人协作的开发。理论上所有文件都可以用版本管理工具,但是由于效率和空间问题,尽量只管理纯文本文件。
目前,Git 无疑是版本管理工具的主流。在工程界,版本管理相对比较流行。但现在做 AI 的很多同学也在学术界,就不一定很重视这方面。可能由于组里面没有协作开发,这方面大概主要就是单分支的开发,或者用 Github 做下托管,这对于简单场景其实也够用了。
作者所经历过的工程复杂场景是另外一种比较复杂的场景。由于有一套比较复杂的软件流程,涉及到软件功能研发,测试,版本发布,持续集成等等环节,这时候就需要用到很多 Git 的工作流模型,灵活运用 Git 的分支等特性。有了合适的开发分支,也就不怕发布版本时,临时开发的代码会影响发布版本的代码稳定性。
工程代码
很多搞 AI 的朋友理论方面很稳,做试验效果也很好,程序上其实在算法层面的效率优化空间已经不大了,但为什么实际工程还碰到速度和性能问题?
我们看上面那个 Matlab 的问题,是因为 Matlab 内部集成了 mkl 高性能数学库,使得 Matlab 调用自己函数实现的一些矩阵集成运算的性能及其高。而我们自己手写 C++ 代码,即使我们自己的模型逻辑和算法优化的很好,但底层的基础线性代码计算却是用的效率很一般,甚至是学校教科书上教的那种作业式的代码去实现,自然效率提高不上去。
在这方面,我们需要做的是先搞清楚自己是研究什么的。如果不是做线性代数或计算数学的相关基础研究,或者我们计算的就是标准的矩阵运算,都还是直接调用 mkl 这类数学库来的实际。mkl 其实是英特尔实现的库,开源软件里面对应的是 lapack 和 BLAS, 后者负责基础的线性代数计算,前者相对更高层一些,调用后者一些方法,实现方程组求解等操作。除了英特尔实现的 mkl 外,开源软件最著名也是最快的是 OpenBLAS。另外,在深度学习上,我们还需要英伟达开发的 cuBLAS,顾名思义就是利用 GPU 加速矩阵计算的速度。
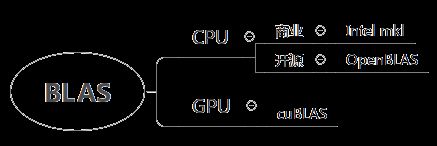
由于这些库高度的利用了硬件上和计算方法上的优化,其矩阵计算速度远超过我们普通开发者的实现。在很多如 numpy ,R 等类似 Matlab 的 数据科学和科学计算软件里,都直接基于这些库进行开发。了解了这一点,我们就不会在面向工程应用为目的时,还要用自己实现的标准矩阵代码去计算。即使需要自己实现 C++ 计算标准的矩阵计算,也应该是尽量调用这些库的函数去实现,以保证我们的算法没有性能瓶颈。
另外,我们经常在算法的伪代码中写循环,如果我们使用的是 Python 或 R 之类的高级语言,就一定不要在数据很多时,用for循环处理数据。这类功能在每种高级语言中都有相应的提升速度的方法。我们也可以考虑直接通过内嵌 C++ 代码的思路来提高速度,只要把占用 80% 计算时间的 一小块最耗时的核心代码替换为高效率的内联 C++ 代码就能达到最好的效果。我们在之后的进阶篇中会重点介绍 Python 生态中最流行的 Cython 技术。
Linux基础
我见过非常多的朋友,有大牛,也有小白,都使用 Windows 来使用作为自己的开发和工作用操作系统。这里,我只是提出自己的一个观点和建议。大牛有足够能力可以应对和解决问题,我的建议主要是对小白:学 AI 请快快掌握 Linux。几乎所有严肃认真的 AI 工程环境都是 Linux 系统,而所有 AI 的主流深度学习框架一定都支持 Linux,但在 Windows 和 Mac 上未必完全兼容,很多特性也都是有限支持。说起来,作者我也是图省事,直接从 Ubuntu 9.04 起就把 Linux 作为自己的日常操作系统,把 Windows 请进我的虚拟机里,去完成那些因为不可抗力才必须要 Windows 去完成其他杂事。这可能和大部分朋友的做法正好相反,但我这样几乎完全用 Linux 完成工作的一个最大好处就是,我在 Linux 下运行 AI 碰到的坑会少很多很多。与那些只能靠远程 Pycharm 才能干活的同事不同,我可以直接使用命令行的 Vim + OMZsh + Tmux 就实现大部分 IDE 的功能,并能做很多 Windows 不能实现的事情。
如果你也经常使用 Linux,我相信你肯定会更理解为什么 Python ,R 甚至 Octave 等等的注释符号都是#,为什么脚本头行里有一行 Shebang(#!),windows的路径写法为什么还需要转义才能使用。这一切的习惯和约定,都和 Linux 下是一脉相承的,但很多都与 Windows 下的习惯和约定不同。所以,我认为 Linux 肯定是 AI 必须的工程基础。我们这个专栏也会拿出比较多的篇幅围绕相关主题为大家介绍和讲解相关工具的使用。
工程目录结构
AI 项目比其他工程项目复杂的多,在具备其他工程项目的复杂性外,还需要数据、训练、预测和上线多个环节。如何有条理的组织好一个 AI 项目结构,让自己和其他人更容易清晰快速理解和掌握项目的开发,就变得非常有意义。一般, AI 项目需要至少有说明文档、示例代码文件夹、数据文件夹、文档文件夹、安装脚本、源代码文件夹、根据项目定制的.gitignore, 持续集成的配置文件、 测试框架用的配置文件、依赖安装文件(夹)
和 Docker 容器安装文件夹。我在后面的进阶篇中会专门为大家介绍常见的 AI 项目目录结构,以及这些常用文件和文件夹在开源项目中常用命名的习惯。使用这些约定俗成的名称和结构,能进一步让自己和同事快速掌握项目组成,快速完成交接或协作开发的磨合。
运行环境的交付
上面谈到了依赖环境的管理,我们可以通过技术,快速的一键安装相同版本的依赖库。但在下面的情况下依然会出现比较大的麻烦。假设一个 AI 项目用到了 tensorflow 1.10.x, 但目前由于官方小组更新很快,老版本已经被清理掉,我们已经无法直接用pip install tensorflow==1.10.* 来安装这个版本。如何在交付项目时,方便的连同依赖库直接进行交付?
可能很多朋友都想到了答案,就是 Docker。通过 Docker 这种集装箱架构思想,我们就可以很方便的把 AI 工程里用到各个依赖库都打到镜像中,使用者可以直接拉取做好的镜像,拿来使用。由于原生的 Docker 不能直接访问主机的 NVIDIA GPU 资源,在做深度学习时,我们还需要使用英伟达开发的nvidia-docker。
回头再看那个交接的例子,因为负责交接的同事经常有自己很多事情需要处理,不大可能和我们理想中一样,仔仔细细看你写好的文档。因此,如果能借助 Dockerfile 这种可执行可重现的环境部署文件去代替那一堆充满各种细节的文档,也是节省了大家相互的时间。
另外,指的一提的是,虽然微软不断努力让 Windows 支持 Docker, 但毫无疑问的是, Docker 最好的运行环境只有 Linux。因为 Docker 项目就是基于 Linux 内核功能开发形成。因此, Docker 也是更进一步佐证,为什么我劝你直接学用 Linux。
总结
写到这里,让我们简单总结一下今天提到的几个方面和建议。
AI 项目工程需要做好依赖环境管理,可以通过工具链自动查找,下载和安装依赖
AI 项目文件夹有合理的组织结构,能让用户一目了然各部分文件。
AI 项目需要掌握 Linux 和其他相关工具。
AI 项目应尽量提供 Docker 镜像以保证工程上的重现性。
AI 项目编程应使用合适的工程代码技术,以保证计算效率
另一方面,AI项目离不开模型部署上线的一个环节。但这部分涉及内容比较繁多,因为篇幅问题,本专栏会有涉及但暂不作为重点内容。如果以后有机会,想单独作为一个议题讨论。
AI项目整个流程复杂,已经有mlflow等工具记录实验过程的超参数,模型性能指标和模型文件。全流程工具可以帮助我们更有条理的管理多个实验,一目了然知晓各种参数的模型表现,有条不紊地对比各个实验。
当然,除了上述内容外,AI 落地的坑还有和研究和理论本身的缺陷,造成研究的不可重复性,比如某算法的泛化性很差,或者算法本身很敏感,易受干扰,从而造成落地应用时的各种难题。但这些方面内容有很多与实际具体业务联系紧密,很难有普适性,同时也会占用大量篇幅,不作为本专栏讲述的主要内容。
下一篇文章,我将为大家介绍今天文章提到的工程基础之一 Linux 命令基础,我会从 AI 或数据科学方面,介绍和总结常用的 Linux 命令基础,让大家可以花比较少的时间先对最常用到的知识有个了解。
交流学习
最后要说的是针对这个专栏,成立了专门的读者交流群,我会在群里与大家一起来探讨学习这个专栏过程中遇到的问题。
加入方式:扫描下方的微信二维码,添加微信好友,之后统一邀请你加入交流群。添加好友时一定要备注:AI炼丹炉。

(完)
