大会丨IJCAI 2018:聚焦强化学习的学习效率
编者按:上个月中旬, IJCAI 2018在瑞典首府斯德哥尔摩召开,微软亚洲研究院机器学习组实习生林子钏从大会现场为我们带回了新鲜出炉的大会热点和他的参会论文分享。
7月16日至19日,人工智能顶级会议IJCAI在瑞典斯德哥尔摩郊外的国际博展馆召开。本次IJCAI大会共收到投稿3470篇,相比去年有37%的增长,最后共接收710篇,其中46%的通讯作者来自中国,华人在人工智能浪潮中的力量可见一斑。

大会论文涵盖了多个研究领域,其中数量最多的是机器学习领域,其次是计算机视觉领域。此外,机器学习应用、多实体系统(multi-agent systems)、自然语言处理等研究方向也非常热门。
大会一共选出了7篇杰出论文:
SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks (K.Wang, X.Wan)
Reasoning about Consensus when Opinions Diffuse through Majority Dynamics (V. Auletta, D. Ferraioli, G. Greco)
R-SVM+: Robust Learning with Privileged Information (X. Li, B. Du, C. Xu, Y. Zhang, L. Zhang, D. Tao)
From Conjunctive Queries to Instance Queries in Ontology-Mediated Querying (C. Feier, C. Lutz, F. Wolter)
What game are we playing? End-to-end learning in normal and extensive from games (C. K. Ling, J. Z. Kolter, F. Fang)
Commonsense Knowledge Aware Conversation Generation with Graph Attention (H. Zhou, T. Young, M. Huang, H. Zhao, J. Xu, X. Zhu)
A Degeneracy Framework for Graph Similarity (G. Nikolentzos, M. Vazirgiannis, P. Meladianos, S. Limnios)
本次会议中,我最感兴趣的一个研讨会主题是探讨如何在强化学习中更好地进行探索。
Exploration in Reinforcement Learning Workshop主页:
https://sites.google.com/view/erl-2018/home
由于该研讨会希望容纳尽可能多的研究方向,在不同思维方式的碰撞中产生一些新颖的想法,因此它接收的30篇论文涉及到无监督学习、因果推断、生成模型、贝叶斯建模、元学习、层次强化学习等各个不同方向。
我从中挑选了两篇论文为大家介绍一下。
1. Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
论文链接:https://arxiv.org/abs/1712.06560
进化策略(Evolution Strategies)是解决强化学习问题的一类黑盒优化算法,优势是并行效率高、可扩展性好。但是,面对稀疏奖励(sparse reward)的强化学习问题,如何指导ES策略进行更有效率的探索,仍然是一个颇具挑战的难题。
针对稀疏奖励的问题,目前使用神经网络的探索策略主要包括:
(1)近似计算“状态-动作”访问的次数;
(2)估计代理(agent)对于环境转换的不确定性。
这些方法只是单一地考虑个体的状态,然而,一个更好的方式是考虑代理行为的抽象。
在这篇论文中,作者定义了一个行为描述函数b(π),来刻画策略π的行为,并维护了一个行为描述库A。策略π_θ的新颖性(Novelty)可以通过计算b(π_θ)与其在A中的k近邻的平均距离得到。如下面公式所示:
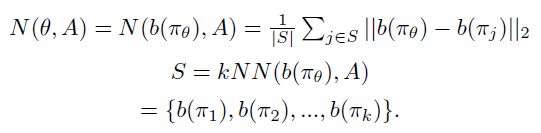
在实际实验中,作者提出将新颖性与策略rollout的实际得分f(θ)线性结合的方式:

初始时w=1,w在训练过程中逐渐下降,当代理的性能提高时,w的值也提高。
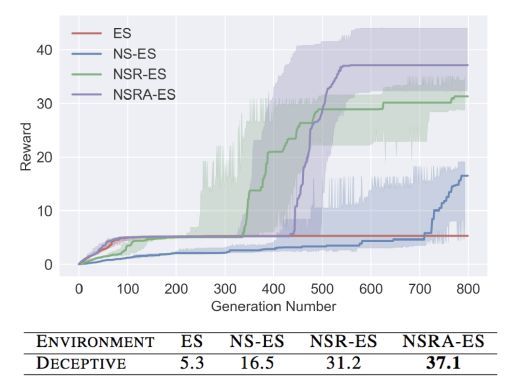
作者在Humanoid数据集上进行实验,实验中的行为描述函数b(π)定义为代理的rollout的最终位置(x, y)。
实验结果如下图所示,其中NS-ES为只使用Novelty的ES策略即w=0的方法,NSR-ES为w=0.5的方法,NSRA-ES为动态调整w的方法。实验表明,该论文提出的方法在稀疏环境上可以比ES算法进行更有效的探索。
2. Meta-Reinforcement Learning of Structured Exploration Strategies (Abhishek Gupta, Russell Mendonca, Yuxuan Liu, Pieter Abbeel and Sergey Levine)
论文链接:https://arxiv.org/abs/1802.07245
探索(Exploration)是强化学习中的一个开放性问题。现有的很多探索方法是通过给单任务设置目标函数来增加信息增益(information gain),或者状态访问奖励(state visitation bonuses)。然而现实情况中往往包含多任务的学习。那么,先验任务能否为当前的学习任务提供更加充分的探索策略呢?
在这篇文章中,作者提出了一个新的模型——具有结构化噪声的模型无关探索(MAESN, Model-Agnostic Exploration with Structured noise),从先验的任务中学习探索策略。该方法可以从先验任务中得到一个初始的策略,并获取一个隐含探索空间(latent exploration space),然后从隐含探索空间中采样,得到结构化的探索策略。通过元强化学习(Meta-Reinforcement Learning),该结构化的探索策略可以大大增加新任务的探索效率。该方法在多个机器人的任务上均表现出了良好的探索效率。
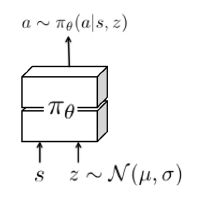
图1 带有隐含状态的策略
图中,z表示从隐含的探索空间中采样出的随机变量。Z在每个episode开始时采样一次,整个episode中保持不变,保证探索策略在一个episode中的一致性。μ, σ为训练过程中学习出的分布参数。
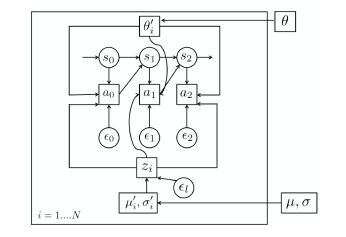

图2 更新流程图与更新公式
作者结合了变分推断和元学习来更新参数,训练目标是使策略参数(θ)能够学会利用隐含变量(μ, σ),在新任务上进行快速有效的探索。其中,每个任务具有单独的隐含分布μ_i, σ_i,任务之间共享策略参数。
每一步迭代中包含“内部”更新与“外部”更新两部分。在“内部”更新时,作者根据(5)(6)(7)式针对每个任务τ_i,分别对θ, μ, σ进行更新得到θ_i, μ_i, σ_i。在“外部”更新时,作者利用(3)(4)对所有任务进行奖励优化和KL散度优化。经过这两步更新,策略参数能学会利用隐含分布来优化所有任务,进而获取在所有任务上的最佳隐含探索空间。
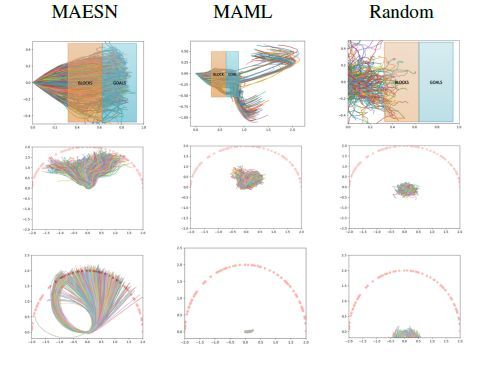
图3 MAESN在新任务上的探索行为,明显展现出了比其他方法更加充分、全面的探索
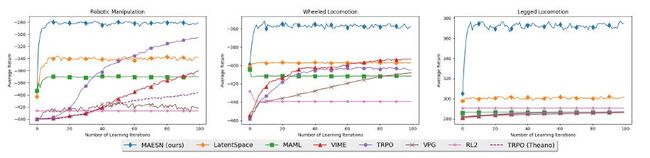
图4 MAESN展现出了比其他方法更快的学习效率
下面介绍一下我在IJCAI 2018发表的成果 :情节记忆深度Q网络。
样本效率(sample efficiency)是深度强化学习中一个基础问题。举个简单的例子,为了训练机器人打Atari视频游戏,深度Q网络(Deep Q-Networks)需要跟游戏环境进行上亿次的交互,才能学习到比较好的策略,训练时间为6~9天。相比起来我们人类几分钟就能学会玩一个游戏。因此目前的深度强化学习的样本效率是非常低的。
因此,为了提高深度强化学习的学习效率,我们提出了“情节记忆深度Q网络”(Episodic Memory Deep Q-Networks, EMDQN),在深度Q网络的训练过程中,不断把历史最优情节(episode)储存到记忆当中,并不断地取出进行训练。整体架构图如下所示:
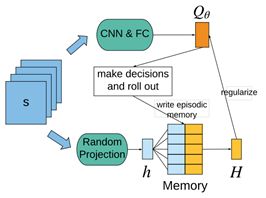
我们为代理定义了两个训练目标,一个是one-step bootstrapped target,S(s, a);另一个是episodic memory target,H(s, a),并通过L2-loss函数同时优化这两个训练目标。
![]()
![]()
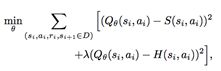
实验表明,我们的方法可以大大提高DQN的样本效率,在Atari游戏上进行更高效的学习。

感兴趣的读者可以访问我们的论文和开源代码:
论文地址:
https://www.ijcai.org/proceedings/2018/0337.pdf
开源代码:
https://github.com/LinZichuan/emdqn
作者简介:

林子钏,清华大学计算机系在读博士生,目前为微软亚洲研究院机器学习组实习生,研究方向为深度强化学习。
你也许还想看:
● ICML 2018 | 模型层面的对偶学习
● ICML 2018 | 训练可解释、可压缩、高准确率的LSTM
● 大会丨青年科研工作者眼中的ICML 2018
![]()
感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:[email protected]。
