H2O学习笔记(六)—— Steam
Steam
Steam智能引擎是一个端对端的平台,可以将构建和部署智能应用的整个流程结合在一起。数据科学家和开发者可以协同合作,训练和部署预测模型,并将这些模型用于实时的智能应用中。
Steam可以运行在YARN上,并可以独立运行,由于我没有hadoop集群环境,所以这里用单机运行演示。
Steam是一个能够将构建和部署应用结合在一起的平台
本地机器安装和启动Steam
1.安装Steam到本地
略
2.启动 Jetty server,这个服务允许你部署模型并且运行Steam预测服务
java -jar var/master/assets/jetty-runner.jar var/master/assets/ROOT.war3.打开另外一个终端,启动web服务
./steam serve master --superuser-name=superuser --superuser-password=superuser‘–superuser-name=superuser –superuser-password=superuser’两个标签是为了创建Steam超级用户,超级用户可以创建roles, workgroups, 和users ,网络服务启动在 localhost:9000, compilation service (和jetty服务相同)启动在 localhost:8080
规约定义
Entities: 指Steam中的任何对象,包括Roles, Workgroups, Identities, Clusters, Projects, Models, and Services (engines).
Identities:指Steam中的用户
Permissions:决定操作的权限,包括Manage Clusters, View Clusters, Manage Models, View Models
Privileges:指操作entity的权限,包括Own,View,Edit等
Roles: permission的集合,role 包括Data Scientist,Operations,Manager,
Workgroups: indentities的集合,
用户管理流程
1.定义roles
2.定义Workgroups
3.添加新用户
a.创建用户的identity
b.将这个用户关联一个或多个roles
c.将这个用户关联一个或多个workgroups (可选的)
Steam示例
1.启动
启动浏览器localhost:9000,输入先前创建的用户名和密码。Steam UI如下:

左边navigation提供如下功能:
Projects: Steam 集群的所有项目
Services:Steam 部署服务,包括预处理包
Clusters:集群状态
Users:users和roles的列表
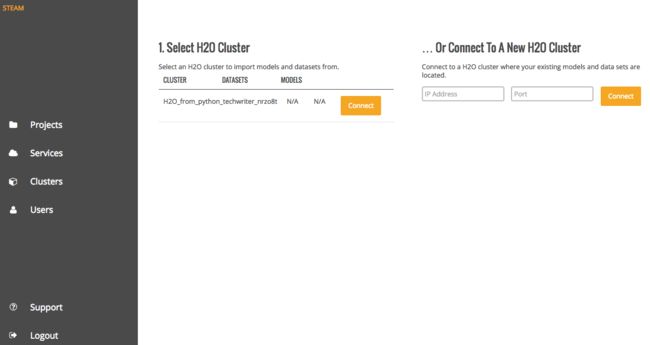
2、创建Project
(1)输入正在运行H2O服务的集群ip和端口,这里ip就是localhost,端口是54321,然后连接服务
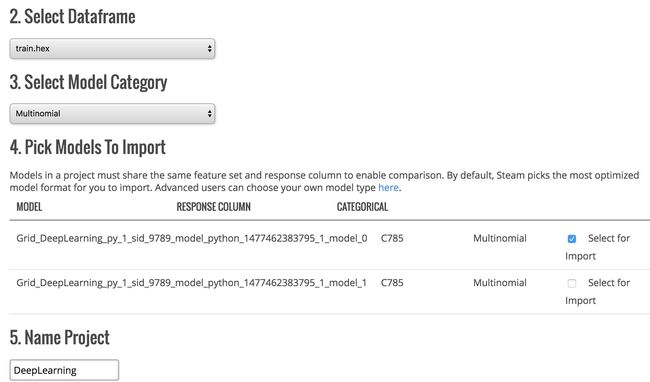
(2)选择集群中需要做预测的一个数据集,这里我选择的是MNIST数据集,选择模型种类,这是是多分类,指定一个集群中已经存在的一个模型,这里用之前训练的Deep Learning模型。
模型种类不同,则性能度量的标准也不同。
对于binomial 模型,model包括下面的一些标准:
- AUC
- Gini
- MSE
- Logloss
- ROC
对于 regression模型,有下面标准:
- MRD
- MSE
- R^2
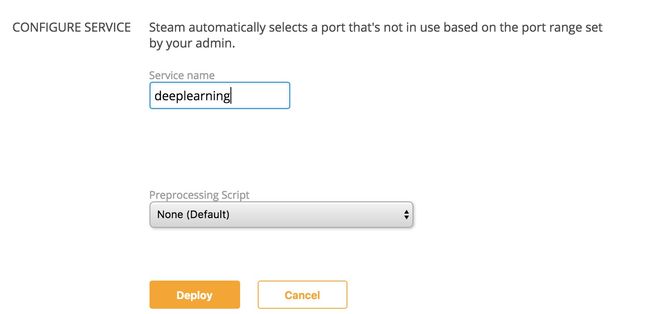
3、部署模型
输入相应的服务名称,也可以加入一些预处理脚本,然后部署
4、启动预测服务
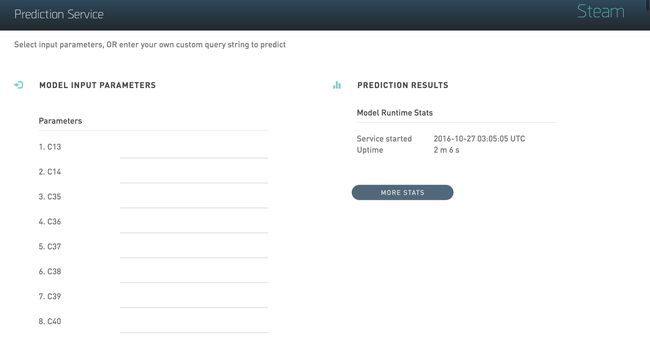
在部署结果中可以看到预测服务启动的ip和端口

打开相应的web,就可看到预测这个模型的预测服务,输入数据就可以看到相应的预测结果
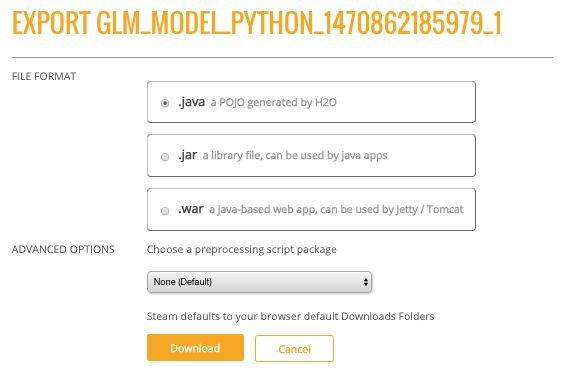
5、导出模型
Steam允许导出模型到本地,可以指定导出为 .java, .jar, or .war 文件