论文阅读-Attention-based Transactional Context Embedding for Next-Item Recommendation
Paper Reading —— Attention-based Transactional Context Embedding for Next-Item Recommendation
基于注意力的事务上下文嵌入下一项推荐
Abstract
在电商交易环境中向user推荐下一个item,这样的应用非常实用但是具有挑战性。Transactional context 是指在交易记录中的observed items。
大多数现有的推荐系统,主要是考虑recently occurring items 而不是 all the ones observed in the current context,这些算法通常假设交易中的items之间存在严格的顺序,但是这并不总是起作用,a long transaction(一个比较长的交易范围)通常包含许多对下一个选择的item没有关联或者说是没有用的item信息,这往往会overwhelm一些真正相关的item的影响。
举个栗子~
让我们举一个例子来说明上述问题。
用户首先将三个项目{milk,apple,orange}放入购物车中,
然后将{bread}添加到同一购物车中。
随后,交易被确定为{milk,apple,orange,bread}。
如果我们将前三个项目作为上下文而最后一个项目作为推荐的目标,
现有方法可能会建议{vegetables},如{green salad},
因为最近的上下文项目(orange和apple)。
但是,目标物品面包的选择可能取决于第一个项目(milk)。
在这种情况下,推荐系统应该更多地关注milk而不是orange和apple,
因为milk可能与下一个选择的bread更相关。
此示例显示了下一项建议的重要性,这可能会被交易中的无关项误导。
此外,真实世界的交易数据通常仅指示那些项目与项目之间的订单
(例如,项目时间戳)共同出现在交易中。
因此,推荐具有严格订单的交易项目可能是不可能和现实的。作者提出一个推荐算法,这个算法不仅考虑当前交易中所有的observed items,而且还要用不同的relevance(相关性)对它们进行加权,以建立一个attentive context(注意力上下文),以高概率输出正确的下一个项目。模型——基于注意的事务嵌入模型(ATEM),用于上下文嵌入,以在不假定顺序的情况下对每个观察到的项目进行加权。对交易数据集的实证研究证明,ATEM在准确性和新颖性方面都显着优于最先进的方法。
Main Algorithm
问题描述与定义
推荐基于购物车序列( built onshoppingbasket-basedtransactiondata)
给定transactional dataset :
给定每个transaction :
所有交易中发生的所有项目构成整个item集 I I :
每个transaction是itemset的子集,且t里的并不是严格的交易顺序。
给定(target item)目标 is∈t i s ∈ t ,除了item is i s ,所有属于 t t 的items统称为context c c ,其中 c=is∖t c = i s ∖ t 。
特别地,attentive context意味着上下文中的项目对下一项目推荐的上下文嵌入有不同的贡献。
给定context c c ,本文的ATEM模型可以构建并训练为 item is i s 在 set t∖is t ∖ i s 出现的条件概率 P(is|c) P ( i s | c ) , 通过每次拾取每个instance作为目标项目,为每个事务t构建总共|t|个训练实例。
因此,TBRS被归结为根据给定上下文中的条件概率对所有候选项进行排名。
在预测阶段,基于上下文c的attentive embedding来计算条件概率。 这种嵌入是建立在c中包含的所有上下文项目的基础上,利用 注意力机制 (attention mechanism)来学习每个上下文项目的权重。
模型建立&模型学习
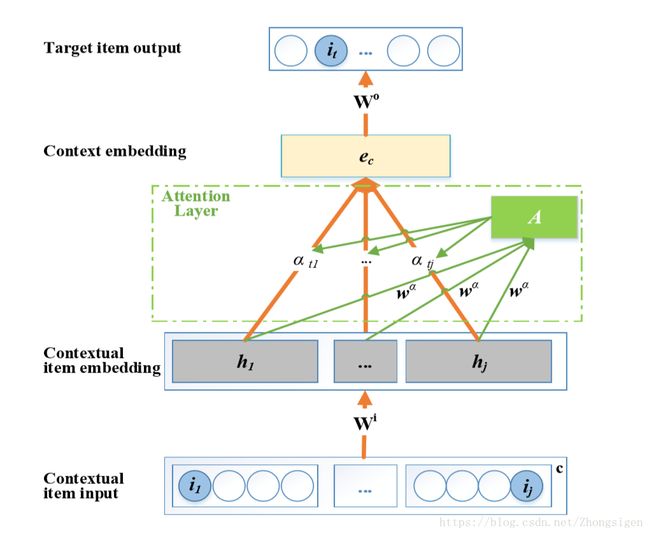
总的来说,从下到上,提出的ATEM模型包括输入层,项嵌入层,上下文嵌入层,输出层,以及项和上下文嵌入层之间的attention层,如上图所示。从输入到输出逐层解释模型的工作机制。
Item Embedding
给输入层提供上下文项集 c c ,底部的输入单元构成一个独热编码矢量,其中只有位置 ij,(ij∈c) i j , ( i j ∈ c ) 的所在单元被设置为1而所有其他单元被设置为0。每个独热编码vector长 |I| | I | context c c 一共有 |t| | t | 个独热编码构成。
由稀疏的单热矢量传递的信息是有限的。 在ATEM中,我们创建了一个嵌入机制,将这些向量映射到项嵌入层中的信息性和低维向量表示,其中K维实值向量
Motivation
推荐系统(RS)发挥着重要作用,特别是在商业领域。然而,大多数现有的RS理论面临各种问题,例如倾向于重复与用户可能已经选择的类似的项目。
在现实数据场景中,用户可能更喜欢新颖且与手头上现有的不同的项目。为了解决这个问题,需要在交易上下文中进行新的推荐,即在交易中已经选择的内容中挖掘。一方面,分析基于RS交易序列,通过分析交易间耦合关系,产生更合理和可靠的新交易建议,例如下一个购物车(basket)和下一项目(item)建议。这些与基于user profile和item profile构建的典型RS方法完全不同。
然而,当一个items集合被放入一个transaction时,仍然不清楚应该下一个项目应该推荐什么。这产生了通过分析事务内依赖性来推荐事务上下文下的下一项的需要。
(transactional context:用于推荐下一个项目的上下文是指对应的项目相关交易,例如,由多个所选项目组成的购物篮记录)
Related
了解transaction context中items之间的相关性和转换非常具有挑战性。在TBRS中,一个普遍的挑战是建立一个注意力(attention)的背景,以高概率输出真正的下一个选择。
一些现有方法旨在通过将transaction as the context来生成推荐。然而,大多数现有TBRS利用具有排序假设的部分上下文。
顺序模式挖掘(2012)用于使用具有严格顺序假设的items之间的关联来预测下一项。但是,上下文中的项可能是任意的,这可能无法匹配任何已挖掘的模式。
马尔可夫链(MC)(2012)是建模顺序数据的另一种方法。然而,MC只捕获从一个项目到下一个项目的转换,而不是从上下文序列中捕获,即,它只能捕获第一次转换。
最近,基于矩阵隐式因子分解(MF)的方法(2016)将转移概率的矩阵从然而,由于现实世界中的幂律分布数据,MF很容易受到稀疏性问题的困扰(2016)。
受Deep Learning的巨大成功的启发(2015),应用深度递归神经网络(RNN)来模拟顺序数据的事务,但由复杂结构引起的高计算成本阻止了其应用于大数据。
此外,MC,MF和RNN最初是为具有严格自然顺序的时间序列数据而设计的,因此它们不具有无序的交易。
(例如,或面包是否首先放入购物车中没有区别。另外,现有方法不能有效地加权上下文中的项目,即更多地关注那些相关项目。这种注意区分非常重要,特别是对于长期交易而言,这些交易往往包含许多与下一个选择无关的项目。)
最近,受心理认知方案的启发,注意机制在上下文学习相关方面显示出惊人的潜力。 通过搜索图像中与答案相关的区域,呈现用于图像问题回答的堆叠注意网络(SAN)。 另一个新模型在人类关注的指导下学习句子表征(Shaonan,Jiajun和Chengqing 2017)。 鉴于CV和NLP中的上下文学习注意机制的巨大成功,我们结合了一些想法并提出ATEM来模拟下一个项目推荐的注意上下文。
Contribution
本文通过提出一种基于注意力的交易嵌入模型(ATEM)来解决需求。 ATEM通过识别与下一个选择具有高度相关性的上下文项,在交易中的所有观察项目的嵌入(Embedding)上构建了一个关注的上下文(attention context)。构建了一个浅宽的广泛网络(wide-in-wide-out network)(Goth 2016),以减少时间和空间成本。具体而言,作者将注意机制(Shaonan,Jiajun和Chengqing 2017)纳入浅层网络,以在没有严格排序假设的情况下在事务中构建所有观察项目(observed items)的注意上下文(attention context)。由于注意机制,所提出的模型能够更多地关注更相关的items,而更少关注不太相关的items。因此,ATEM更有效,更强大,可以预测具有较少约束的事务中的下一个item。这项工作的主要贡献如下:
基于注意力的模型学习一种注意力的上下文嵌入,强化了相关项目但忽略了与下一个选择无关的项目。 我们的方法不涉及对事务中项目的严格排序假设。
浅宽的宽广网络实现了ATEM,它对于大量项目的学习和预测更有效和高效。
实证研究表明
ATEM在准确性和新颖性方面明显优于两个真实数据集上的最新TBRS;
通过比较有无注意机制的方法,注意机制对TBRS产生显着差异。