[Python]40行代码实现公式转换成图片,手把手教你从模仿到实现
最近写公式号需要把公式转成图片,有网站能实现转换功能,但是一个一个复制过去然后保存图片太复杂。
能不能实现自动转换并保存图片呢?
这篇文章可以告诉你一个小白如何通过模仿完成一个小功能,并且遇到错误如何调试,如果你只想获得这个小程序,直接看最后就行,如果你想了解背后的思考过程那我们一步一步开始。
我的思路是这样的,已知现成的网站http://quicklatex.com/可以实现公式转图片的功能,我们只需要把公式发给这个网站然后把网站的生成的图片取回来就行了。
找一个爬取图片的教程,我找的是「静觅丨崔庆才的个人博客」
https://cuiqingcai.com/3179.html
这里有他爬取图片的代码,我只需要模仿就行。
1.模仿发送请求
import requests ##导入requests
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用requests中的get方法来获取all_url(就是:http://www.mzitu.com/all这个地址)的内容 headers为上面设置的请求头、请务必参考requests官方文档解释
print(start_html.text) ##打印出start_html (请注意,concent是二进制的数据,一般用于下载图片、视频、音频、等多媒体内容是才使用concent, 对于打印网页内容请使用text)
我只需要把网址改掉就行,使用谷歌浏览器按F12查看请求的内容
把网址改成http://quicklatex.com/latex3.f
![[Python]40行代码实现公式转换成图片,手把手教你从模仿到实现_第1张图片](http://img.e-com-net.com/image/info8/9789be24ea0045a9bbf46e0de35d1fb3.jpg)
然后模仿
import requests ##导入requests
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"}
all_url = 'http://quicklatex.com/latex3.f'
start_html = requests.post(all_url,headers=headers)
print(start_html.text)
运行一下,得到结果。
-1
http://quicklatex.com/cache3/error.png 0 0 0
Error: Nothing to show, formula is empty
可以看到,我们真的得到了一个png图的网址,虽然是错误的,提示我们缺少参数,至少证明我们的模仿有效果了。
搜索 「python3 发送post请求」,继续使用谷歌浏览器查看参数
![[Python]40行代码实现公式转换成图片,手把手教你从模仿到实现_第2张图片](http://img.e-com-net.com/image/info8/19f24deb7ba6401bb383354f028f6779.jpg)
仿造搜索结果,添加参数
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"}
all_url = 'http://quicklatex.com/latex3.f'
Para = {'formula':'$$w_c=\frac{1}{RC}$$','fsize':"35px",'remhost':'quicklatex.com','mode':'0','out':'1','fcolo':'000000'}
start_html = requests.post(all_url,headers=headers,data=Para)
print(start_html.text)
0
http://quicklatex.com/cache3/a9/ql_3442cfe9de43849f88c4f0058727a1a9_l3.png 0 587 85
完美,得到了一个png图片,在浏览器打开

发现还是不对,显示的不对,这里我想了很久,仔细分析错误图片和正确图片的区别,为什么「\f」不见了?有没有可能是把「\f」当做换页了?于是把「\frac」换成「\\frac」。
import requests ##导入requests
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"}
all_url = 'http://quicklatex.com/latex3.f'
Para = {'formula':'$$w_c=\\frac{1}{RC}$$','fsize':"35px",'remhost':'quicklatex.com','mode':'0','out':'1'}
start_html = requests.post(all_url,headers=headers,data=Para)
print(start_html.text)
终于得到了正确的图片
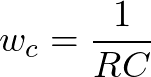
2.模仿保存图片
继续回到「静觅丨崔庆才的个人博客」看看他是怎么保存图片的。
img_url = img_Soup.find('div', class_='main-image').find('img')['src']
name = img_url[-9:-4] ##取URL 倒数第四至第九位 做图片的名字
img = requests.get(img_url, headers=headers)
f = open(name+'.jpg', 'ab')##写入多媒体文件必须要 b 这个参数!!必须要!!
f.write(img.content) ##多媒体文件要是用conctent哦!
f.close()
模仿他取出网址
import requests ##导入requests
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"}
all_url = 'http://quicklatex.com/latex3.f'
Para = {'formula':'$$w_c=\\frac{1}{RC}$$','fsize':"35px",'remhost':'quicklatex.com','mode':'0','out':'1'}
start_html = requests.post(all_url,headers=headers,data=Para)
print(start_html.text)
start_html.text[3:-9]#取出图片的网址
img = requests.get(img_url, headers=headers)
f = open(name+'.png', 'ab')
f.write(img.content)
f.close()
终于保存了一张正确图片,接下来,我们只需要把公式用列表保存起来,然后循环即可。
现在的问题是如何让「\frac」自动变成「\\frac」,其实这个问题的本质是怎么替换字符串里的字符,通过搜索可以知道,字符串可以用replace替换
Gs=[
'$$w_c=\frac{1}{RC}$$',#0
'$$f_c=\frac{1}{2\pi*RC}$$',#1
'$$s=\frac{1-z^{-1}}{T}$$',#2
'$$H(z)=\frac{Y(z)}{X(z)}=\frac{1}{RC{\frac{1-z^{-1}}{T}+1}}=\frac{T}{RC(1-Z^{-1})+T}$$',#3
'$$X(z)=Y(z)+\frac{RC(1-Z^{-1})+T}{T}$$',#4
'$$X(z)=\frac{RC}{T}Y(z)-\frac{RC}{T}Y(z)(Z^{-1})+Y(z)$$',#5
'$$X(n)=(1+\frac{RC}{T})Y(n)-\frac{RC}{T}Y(n-1)$$',#6
'$$Y(n)=(\frac{1}{1+\frac{RC}{T}})X(n)+(\frac{\frac{RC}{T}}{1+\frac{RC}{T}})X(n-1)$$',#7
'$$Y(n)=\frac{T}{RC+T}X(n)+\frac{RC}{RC+T}Y(n-1)$$',#8
'$$A=\frac{T}{RC+T}$$',#9
'$$Y(n)=A*X(n)+(1-A)Y(n-1)$$',#10
'$$A=(\frac{1}{1+(\frac{1}{2\pi*T})})$$',#11
'$$f_c=\frac{1}{2\pi*RC}$$',#12
'$$RC=\frac{1}{2\pi*f_c}$$',#13
'$$A=\frac{T}{RC+T}$$',#14
'$$A=\frac{T}{\frac{1}{2\pi*f_c}+T}=\frac{1}{1+(\frac{1}{2\pi*Tf_c})}$$'#15
]
for i in range(len(Gs)):
Gs[i]=Gs[i].replace("\frac","\\frac")#自动替换
恭喜到这里我们完成了整个思路。
3.调试Bug
运行之后多次后发现所有的图片都对,只有7号图片是错的。
![[Python]40行代码实现公式转换成图片,手把手教你从模仿到实现_第3张图片](http://img.e-com-net.com/image/info8/56904e5f7bd441199d12444c2b4e72ea.jpg)
这是为什么?不要着急,有问题是正常的,慢慢调试就行。
调试最重要的核心是缩小范围然后确定问题的位置。
到底是第7个 位置的问题,还是第七个 公式的问题?
于是我把第七个公式移动到第一个位置,然后运行,发现错误变成第1个位置了。
![[Python]40行代码实现公式转换成图片,手把手教你从模仿到实现_第4张图片](http://img.e-com-net.com/image/info8/6349068d6d7c4e9d924b0ed2060dda8d.jpg)
那么可以肯定就是第七个公式的问题了。
把第七个公式单独拿出来测试,去掉循环,发现确实是它的问题,可是直接把start_html.text里的网址复制出来,用浏览器打开是没问题的。
继续缩小范围,是 提取网址的过程有问题还是 保存图片的过程有问题,把网址拿出来测试保存,发现没问题。
那就是生成的网址有问题,把对的网址和生成的网址进行对比,
#提取的网址
img_url=start_html.text[3:-9]
#正确的网址
a='http://quicklatex.com/cache3/46/ql_2f56ac4793fdb196ad7153bc3dc88746_l3.png'
print(len(img_url),len(a),type(img_url[1]),type(a))
print(img_url)
print(a)
print(img_url==a)
运行结果,发现虽然看起来一模一样,但是生成的网址多了一位,应该是多了一个空格,问题找到了我们换一个方式来取出正确的网址就行。

得到的start_html.text完整输出为:
0
http://quicklatex.com/cache3/a9/ql_2f56aC4793fdb196ad7153bC3dC8876_l3.png 0 587 85
其实是这样的一个字符串
start_html.text='0\r\nhttp://quicklatex.com/cache3/a9/ql_2f56aC4793fdb196ad7153bC3dC8876_l3.png 0 587 85'
问题的关键是如何把字符串拆分提取出其中的网址,字符串里有空格还有换行符,那就先用空格替换掉换行符,然后以空格来拆分,这样得到的网址就是完全正确的。
#空格 替换 换行符
img_url=start_html.text.replace("\r\n"," ")
#以空格为标志进行分割
img_url=img_url.split(' ')
#取出列表里的第二个数,就是正确的网址
img_url=img_url[1]
运行可以得到
['0', 'http://quicklatex.com/cache3/a9/ql_2f56aC4793fdb196ad7153bC3dC8876_l3.png', '0', '587', '85']
这个列表的第二个数就是绝对正确的网址。
4.调好的程序
解决了以上所有问题,这是最终程序,把公式按顺序复制到程序里,然后程序就可以自动按顺序保存图片。
import requests ##导入requests
import random
import time
#m每个\frac要变成\\frac
Gs=[
'$$w_c=\frac{1}{RC}$$',#0
'$$f_c=\frac{1}{2\pi*RC}$$',#1
'$$s=\frac{1-z^{-1}}{T}$$',#2
'$$H(z)=\frac{Y(z)}{X(z)}=\frac{1}{RC{\frac{1-z^{-1}}{T}+1}}=\frac{T}{RC(1-Z^{-1})+T}$$',#3
'$$X(z)=Y(z)+\frac{RC(1-Z^{-1})+T}{T}$$',#4
'$$X(z)=\frac{RC}{T}Y(z)-\frac{RC}{T}Y(z)(Z^{-1})+Y(z)$$',#5
'$$X(n)=(1+\frac{RC}{T})Y(n)-\frac{RC}{T}Y(n-1)$$',#6
'$$Y(n)=(\frac{1}{1+\frac{RC}{T}})X(n)+(\frac{\frac{RC}{T}}{1+\frac{RC}{T}})X(n-1)$$',#7
'$$Y(n)=\frac{T}{RC+T}X(n)+\frac{RC}{RC+T}Y(n-1)$$',#8
'$$A=\frac{T}{RC+T}$$',#9
'$$Y(n)=A*X(n)+(1-A)Y(n-1)$$',#10
'$$A=(\frac{1}{1+(\frac{1}{2\pi*T})})$$',#11
'$$f_c=\frac{1}{2\pi*RC}$$',#12
'$$RC=\frac{1}{2\pi*f_c}$$',#13
'$$A=\frac{T}{RC+T}$$',#14
'$$A=\frac{T}{\frac{1}{2\pi*f_c}+T}=\frac{1}{1+(\frac{1}{2\pi*Tf_c})}$$'#15
]
for i in range(len(Gs)):
Gs[i]=Gs[i].replace("\frac","\\frac")#添加转义字符
for i in range(len(Gs)):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://quicklatex.com/latex3.f' ##开始的URL地址
Para = {'formula':Gs[i],'fsize':"35px",'remhost':'quicklatex.com','mode':'0','out':'1','fcolo':'000000'}
start_html = requests.post(all_url,headers=headers,data=Para) ##使用requests中的get方法来获取all_url(就是这个地址)的内容 headers为上面设置的请求头、请务必参考requests官方文档解释
img_url=start_html.text.replace("\r\n"," ")
img_url=img_url.split(' ')
img_url=img_url[1] ##取URL 倒数第四至第九位 做图片的名字
time.sleep(0.1)
img = requests.get(img_url, headers=headers)
print(i,img,img_url)
f = open('g'+str(i)+'.png', 'wb')##写入多媒体文件必须要 b 这个参数!!必须要!!
f.write(img.content) ##多媒体文件要是用conctent哦!
f.close()
print("转换完成")
![[Python]40行代码实现公式转换成图片,手把手教你从模仿到实现_第5张图片](http://img.e-com-net.com/image/info8/a3cc84697ed048909c156f77a6298371.jpg)
以上是我做这个程序的全部思路和实践过程,这个思路也是我目前常用的学习方法,我觉得可以很快入门,实现一些小功能。
我也是个小白只知道一点Python基础,这个程序是我边查资料编写用了6个小时,我觉得入门就是这样,你有一个目的,然后去解决这个目的前的所有问题就行了。
如果你学了一点基础知识,陷入了迷茫期,觉的不知道如何继续深入,不妨反过来,找个目的,然后去做,你就会知道自己的欠缺,然后就有学习的方向。 通过实践你会发现基础的重要性,好几个问题的根本其实列表的基本操作,这样实践和理论相结合,可以保持学习的热情。
5.后续改进
还有一些问题,例如访问过于频繁,会失败。
后续还有可以改进的地方,让程序自己从md文件里找到公式,然后按顺序转换成图片并保存。
加上GUI让操作更直观,使用更方便。
如果你有好的学习方法欢迎联系我交流,如果我的学习方法对你有帮助非常荣幸。
关注我的微信公众号,回复【公式图片】即可获取本文代码,同时欢迎加我的个人微信交流学习方法。
![[Python]40行代码实现公式转换成图片,手把手教你从模仿到实现_第6张图片](http://img.e-com-net.com/image/info8/05883022ab28483092f249c23c758c0f.jpg)