修改Spark源码实现MySQL update
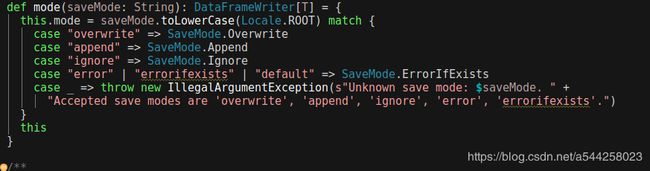
当我们在使用Spark写数据到MySQL时,通常会使用df.write.mode("xxx")...,但是当你点进mode查看源码会发现,可选项为:
overwrite:翻盖存在的数据(会删除表或清空表)
append:追加数据
ignore:忽略操作,就是啥也不干
error:抛出AnalysisException异常
现在有个需求是数据写入表时当主键Key的数据存在时更新字段,否则插入数据。以上的所有选项不能满足此功能,因此接下来打算通过修改Spark源码来实现df.write.mode("update")...的功能。
1. 下载Spark源码,本文基于Spark-2.3.2版本进行修改:https://github.com/apache/spark/tree/v2.3.2
2. 解压zip包并导入IDEA中,通过pom.xml导入,SBT相关的导入安装不用理会,本文用不到
3. 开始修改源码
a. 在spark-2.3.2/sql/core/src/main/java/org/apache/spark/sql/SaveMode.java中新增Update枚举类型,修改的地方都有注解。
package org.apache.spark.sql;
import org.apache.spark.annotation.InterfaceStability;
@InterfaceStability.Stable
public enum SaveMode {
Append,
Overwrite,
ErrorIfExists,
Ignore,
//新增Update类型
Update
}b. 修改DataFrameWriter.scala的mode方法新增update
def mode(saveMode: String): DataFrameWriter[T] = {
this.mode = saveMode.toLowerCase(Locale.ROOT) match {
case "overwrite" => SaveMode.Overwrite
case "append" => SaveMode.Append
//新增的update
case "update" => SaveMode.Update
case "ignore" => SaveMode.Ignore
case "error" | "errorifexists" | "default" => SaveMode.ErrorIfExists
case _ => throw new IllegalArgumentException(s"Unknown save mode: $saveMode. " +
"Accepted save modes are 'overwrite', 'append', 'ignore', 'error', 'errorifexists'.")
}
this
}c. 修改JdbcRelationProvider.scala的createRelation方法,增加Update同时将mode带入saveTable方法中
...
case SaveMode.Append =>
val tableSchema = JdbcUtils.getSchemaOption(conn, options)
saveTable(df, tableSchema, isCaseSensitive, options, mode)
//新增匹配Update
case SaveMode.Update =>
val tableSchema = JdbcUtils.getSchemaOption(conn, options)
saveTable(df, tableSchema, isCaseSensitive, options, mode)
case SaveMode.ErrorIfExists =>
throw new AnalysisException(
s"Table or view '${options.table}' already exists. SaveMode: ErrorIfExists.")
...d. 修改JdbcUtils.scala中的saveTable方法,将mode带入到getInsertStatement和savePartition中,修改代码过程会有红的波浪线,其实不影响
def saveTable(
df: DataFrame,
tableSchema: Option[StructType],
isCaseSensitive: Boolean,
options: JDBCOptions,
//新增mode参数
mode: SaveMode): Unit = {
val url = options.url
val table = options.table
val dialect = JdbcDialects.get(url)
val rddSchema = df.schema
val getConnection: () => Connection = createConnectionFactory(options)
val batchSize = options.batchSize
val isolationLevel = options.isolationLevel
//新增mode参数
val insertStmt = getInsertStatement(table, rddSchema, tableSchema, isCaseSensitive, dialect,
mode)
val repartitionedDF = options.numPartitions match {
case Some(n) if n <= 0 => throw new IllegalArgumentException(
s"Invalid value `$n` for parameter `${JDBCOptions.JDBC_NUM_PARTITIONS}` in table writing " +
"via JDBC. The minimum value is 1.")
case Some(n) if n < df.rdd.getNumPartitions => df.coalesce(n)
case _ => df
}
//新增mode参数
repartitionedDF.rdd.foreachPartition(iterator => savePartition(getConnection, table, iterator,
rddSchema, insertStmt, batchSize, dialect, isolationLevel, mode)
)
}e. 修改getInsertStatement方法,判断是否为Update来返回对应的SQL语句
def getInsertStatement(
table: String,
rddSchema: StructType,
tableSchema: Option[StructType],
isCaseSensitive: Boolean,
dialect: JdbcDialect,
mode: SaveMode): String = {
val columns = if (tableSchema.isEmpty) {
rddSchema.fields.map(x => dialect.quoteIdentifier(x.name)).mkString(",")
} else {
val columnNameEquality = if (isCaseSensitive) {
org.apache.spark.sql.catalyst.analysis.caseSensitiveResolution
} else {
org.apache.spark.sql.catalyst.analysis.caseInsensitiveResolution
}
// The generated insert statement needs to follow rddSchema's column sequence and
// tableSchema's column names. When appending data into some case-sensitive DBMSs like
// PostgreSQL/Oracle, we need to respect the existing case-sensitive column names instead of
// RDD column names for user convenience.
val tableColumnNames = tableSchema.get.fieldNames
rddSchema.fields.map { col =>
val normalizedName = tableColumnNames.find(f => columnNameEquality(f, col.name)).getOrElse {
throw new AnalysisException(s"""Column "${col.name}" not found in schema $tableSchema""")
}
dialect.quoteIdentifier(normalizedName)
}.mkString(",")
}
val placeholders = rddSchema.fields.map(_ => "?").mkString(",")
//判断是否为update,是的话使用insert into ... on duplicate key update...进行更新
mode match {
case SaveMode.Update =>
val duplicateSetting: String = rddSchema.fields.map(x => dialect.quoteIdentifier(x.name))
.map(name => s"$name=?").mkString(",")
s"INSERT INTO $table ($columns) VALUES ($placeholders) ON DUPLICATE KEY UPDATE " +
s"$duplicateSetting"
case _ =>
s"INSERT INTO $table ($columns) VALUES ($placeholders)"
}
}f. 修改makeSetter方法,通过增加offset来控制位置参数
private type JDBCValueSetter = (PreparedStatement, Row, Int, Int) => Unit
private def makeSetter(
conn: Connection,
dialect: JdbcDialect,
dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int, offset: Int) =>
stmt.setInt(pos + 1, row.getInt(pos - offset))
//新增offset参数
case LongType =>
(stmt: PreparedStatement, row: Row, pos: Int, offset: Int) =>
stmt.setLong(pos + 1, row.getLong(pos - offset))
...
...g. 最后修改savePartition就ok了
...
if (supportsTransactions) {
conn.setAutoCommit(false) // Everything in the same db transaction.
conn.setTransactionIsolation(finalIsolationLevel)
}
//判断是否为Update, 是的话长度增加一倍
val isUpdateMode = mode == SaveMode.Update
val stmt = conn.prepareStatement(insertStmt)
val setters = rddSchema.fields.map(f => makeSetter(conn, dialect, f.dataType))
val nullTypes = rddSchema.fields.map(f => getJdbcType(f.dataType, dialect).jdbcNullType)
val length = rddSchema.fields.length
val numFields = if (isUpdateMode) length * 2 else length
val midField = numFields / 2
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if (isUpdateMode) {
i < midField match {
case true =>
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i, 0)
}
case false =>
if (row.isNullAt(i - midField)) {
stmt.setNull(i + 1, nullTypes(i - midField))
} else {
setters(i - midField).apply(stmt, row, i, midField)
}
}
} else {
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i, 0)
}
}
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
}
if (rowCount > 0) {
stmt.executeBatch()
}
} finally {
stmt.close()
}
if (supportsTransactions) {
conn.commit()
}
...4. 打开左侧Maven关闭test,然后点击package编译所有的项目打jar包,时间比较长,先去喝杯茶。。。
5. 在examples目录下编写测试代码,在编写前修改examples目录下的pom.xml文件(很重要),将带provided的全部注释掉
可以方便调试,在scala目录下新建MysqlUpdate进行测试如下
package org.apache.spark.examples
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object MysqlUpdate {
def main(args: Array[String]): Unit = {
val jdbcUrl = "jdbc:mysql://localhost:3306/test?user=root&password=1&useSSL=false&characterEncoding=UTF-8"
val tableName = "(select * from test) tmp"
val spark = SparkSession.builder().appName("UpdateMysql").master("local").getOrCreate()
val df: DataFrame = spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver").option("url", jdbcUrl).option("dbtable", tableName).load()
val prop: Properties = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "1")
df.write.mode("update").jdbc("jdbc:mysql://localhost:3306/test", "test1", prop)
spark.stop()
}
}6. 运行代码
参考文档:https://www.jianshu.com/p/d0bac129a04c