NAACL 2019 | 用异构表示法连接语言和知识的神经网络关系抽取模型
知识库(Knowledge Base)包含大量真实世界的结构化信息,被广泛用于各种自然语言处理任务,例如语义搜索与智能问答。在关系抽取(Relation Extraction)模型中,加入知识库嵌入信息(Knowledge Base Embeddings),可以提高模型效果。尽管关系抽取与知识库嵌入关系密切,但很少有尝试系统地统一这两个模型,本文建立一个框架,统一这两个模型的学习过程,并在关系抽取中达到了最优的效果。

论文地址:
https://arxiv.org/pdf/1903.10126.pdf
代码地址:
https://github.com/billy-inn/HRERE
引言
构建知识库是一个永无止境的工作,需要不停地收集新的知识以及更新旧的知识。这促使了关系提取任务的工作,该任务的目标是为连接一对实体的短语分配知识库中对应的关系,这也可用于知识库的更新。关系抽取的最新技术是使用远程监督构建的大型语料库上进行训练的神经网络模型。在此基础上,本文提出一种新颖的模型将关系抽取与知识库嵌入相结合。
数据集
本次的数据集采用New York Times corpus,有53种关系,包括特殊关系NA,表示头尾实体没有关系。 训练集包含522,611个句子,281,270个实体对和18,252个关系事实;测试集包含172,448个句子,96,678个实体对和1,950个关系事实。对齐NYT语料库提到的Freebase关系,2005-2006年的数据作为训练数据,2007年的数据作为测试数据。知识库选取Freebase中出现次数最多的三百万个实体。
模型
本文模型主要包含两部分,语言表示与知识表示,分别从句子、实体层面进行关系预测,并最终由交叉熵损失函数表示这两种模型的差异性,并和语言表示以及知识表示的损失函数联合训练,进行模型参数的优化。
语言表示
输入端:使用预训练的词向量(Word Embeddings),以及随机初始化的位置向量,将每个词投影到( d w d_w dw+ d p d_p dp)向量空间,其中 d w d_w dw为词向量, d p d_p dp为位置向量。
句子编码器:对每个句子,对其进行双向LSTM变换得到其编码表示。
多层注意力机制模型:在词级别与句子级别均使用注意力机制,选择最有价值的词与句子。获取学习的句子表示 s L s_L sL,添加一层softmax,计算关系r的条件概率p(r|S; Θ ( L ) \Theta^{(L)} Θ(L))。
知识表示
参考Trouillon, Théo, Welbl J , Riedel S , et al. Complex Embeddings for Simple Link Prediction[J]. 2016.训练过程及得分函数\phi计算方法,获取头实体、关系、尾实体的向量表示e_h、w_r、e_t,利用得分函数与知识表示,获取每个关系r的条件概率:
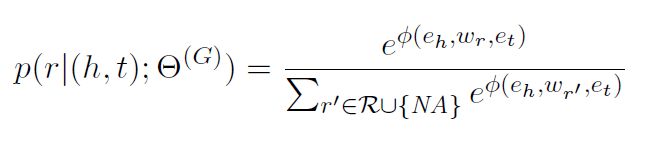
其中,R为关系集合, Θ ( G ) \Theta^{(G)} Θ(G)为参数。
连接件
本文试图以一种优雅的方式,在关系抽取中将语言表示与知识表示连接起来。因此在上图中,使用各自的损失函数,引导语言表示与知识表示的学习过程。同时使用第三个损失函数,将这些模型的预测联系起来,从而将参数推向一致。
语言表示与知识表示的交叉熵损失函数分别如下:
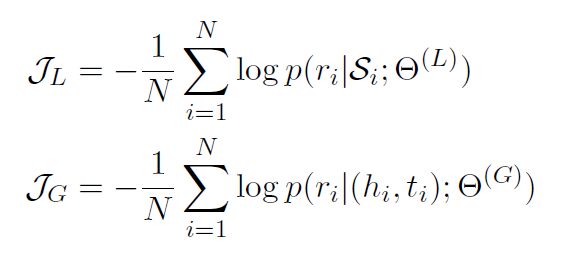
N代表训练集总数,最后使用第三种交叉熵损失函数来衡量这两种分布的差异性,以此来连接两种模型,损失函数如下:

此处:
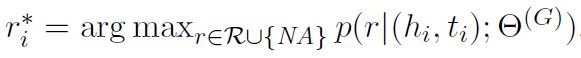
模型学习
由上述三个损失函数,构成模型的联合优化函数:
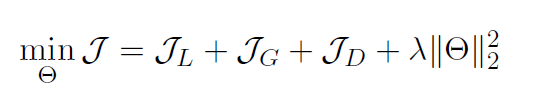
其中:
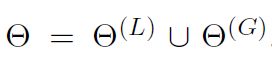
知识表示模型会在知识库中首先被独立地训练,并作为联合学习模型的初始化参数。 Θ ( L ) \Theta^{(L)} Θ(L)、 Θ ( G ) \Theta^{(G)} Θ(G)分别有不同的学习率lr_1、lr_2。
关系预测
使用p(r|S; Θ ( L ) \Theta^{(L)} Θ(L))、p(r|(h,t); Θ ( G ) \Theta^{(G)} Θ(G))的加权平均来计算条件概率p(r|(h,t),S; Θ \Theta Θ)。
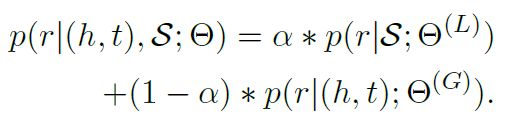
α \alpha α为相关权重,预测关系 r ^ \hat{r} r^为:
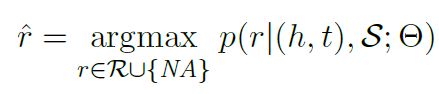
模型参数
模型参数设置如下:

实验结果
HRERE、Weston、CNN+ATT、PCNN + ATT模型实验结果对比,可见本文提出的HRERE模型效果明显好于其他三种模型。
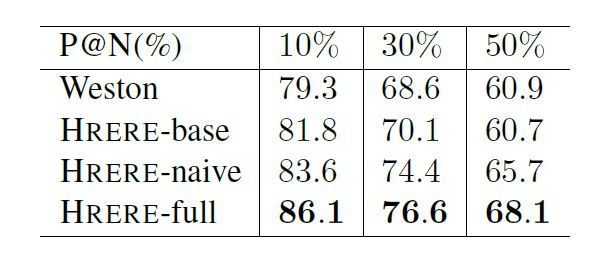
HRERE模型又具体分为三种,HRERE-base仅仅只考虑语言表示模型部分,HRERE-naive考虑语言表示与知识表示模型,HRERE-full考虑语言表示与知识表示模型以及两者的相似性差异。HRERE-full模型效果明显好于HRERE-base、HRERE-naive模型效果。
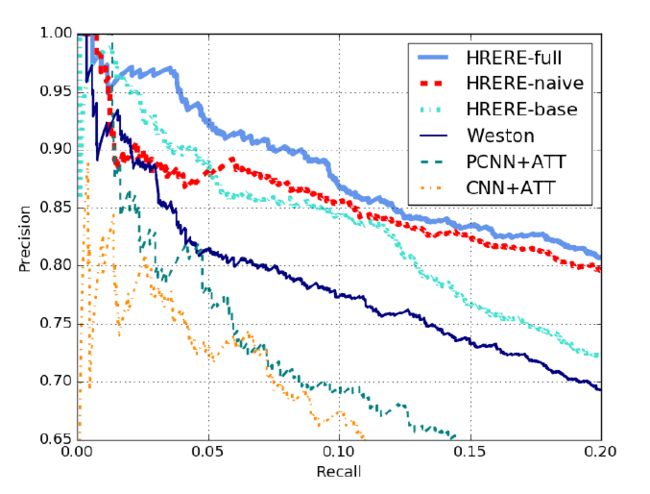
HRERE模型效果整体优于Weston模型的效果,同时考虑考虑语言表示与知识表示模型以及两者的相似性差异的HRERE-full模型效果最优。共同学习异构表示带来了以前独立学习的方法所无法实现的相互促进效果,连接异构表示可以增加模型的健壮性。
结论
本文提出了一种优雅的神经网络模型,用于联合学习来自文本和现有知识库中的事实的异构表示。与以往独立学习两个不同表示并使用简单方案集成每个模型预测的工作相反,本文引入了一个新颖的框架,使用优雅的损失函数,允许在训练期间无缝地学习异构表示之间的正确连接。实验结果表明本文提出的模型优于以往的异构表示的策略,并优于以往的关系抽取模型,仔细观察可知,本文的模型能够使两个单独的模型效果相互增强。

扫码识别关注,获取更多论文解读