超详细的Sqoop介绍及安装使用文档
这应该是全网目前最全的Sqoop文档了吧,小厨为大家奉献整篇内容包括:Sqoop架构、原理、安装、使用等。
目录
1 Sqoop简介
2 Sqoop原理
2.1 import原理
2.2 export原理
3 准备工作:配置数据库远程连接
4 安装Sqoop
5 Sqoop查询命令
6 Sqoop与Hdfs之间导入导出
6.1 关系型数据库导入到HDFS(以mysql为例)
6.2 HDFS导出到关系型数据库
7 Sqoop与HIve导入导出
7.1 关系型数据库导入Hive
7.2 Hive导出到关系型数据库
8 Sqoop与Hbase的导入导出
8.1 关系型数据库导入到Hbase
8.2 Hbase导出到关系型数据库
1 Sqoop简介
Sqoop可以理解为【SQL–to–Hadoop】,正如名字所示,Sqoop是一个用来将关系型数据库和Hadoop中的数据进行相互转移的工具。帮助我们完成数据的迁移和同步。比如,下面两个潜在的需求:
1、业务数据存放在关系数据库中,如果数据量达到一定规模后需要对其进行分析或同统计,单纯使用关系数据库可能会成为瓶颈,这时可以将数据从业务数据库数据导入(import)到Hadoop平台进行离线分析。
2、对大规模的数据在Hadoop平台上进行分析以后,可能需要将结果同步到关系数据库中作为业务的辅助数据,这时候需要将Hadoop平台分析后的数据导出(export)到关系数据库。
根据Sqoop官网说法,Sqoop2 目前还未开发完,不建议在生产环境使用,所以这里选的是Sqoop的稳定版 1.4.6。sqoop整体架构如下图所示:

2 Sqoop原理
2.1 import原理
使用Sqoop可以从关系型数据库中导入数据到HDFS上,在这个过程中import操作的输入是一个数据库表,Sqoop会逐行读取记录到HDFS中。import操作的输出是包含读入表的一系列HDFS文件,import操作是并行的也就是说可以启动多个map同时读取数据到HDFS,每一个map对应一个输出文件。这些文件可以是TextFile类型,也可以是Avro类型或者SequenceFile类型。
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中。同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。 比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
在import过程中还会生成一个Java类,这个类与输入的表对应,类名即表名,类变量即表字段。import过程会使用到这个Java类。
2.2 export原理
在import操作之后,就可以使用这些数据来实验export过程了。export是将数据从HDFS或者hive导出到关系型数据库中。export过程并行的读取HDFS上的文件,将每一条内容转化成一条记录,然后作为一个新行insert到关系型数据库表中。
除了import和export,Sqoop还包含一些其他的操作。比如可以使用sqoop-list-databases工具查询数据库结构,可以使用sqoop-list-tables工具查询表信息。还可以使用sqoop-eval工具执行SQL查询。
3 准备工作:配置数据库远程连接
在使用Sqoop之前,要确保关系型数据库可以允许远程IP访问,可以做如下操作:
(1)配置数据库远程连接,允许IP地址为192.168.1.102主机以用户名为sqoopuser密码为sqoopuser的身份访问数据库。
mysql>GRANT ALL PRIVILEGES ON mytest.* TO 'root'@'192.168.1.102' IDENTIFIED BY 'sqoopuser' WITH GRANT OPTION;
mysql>FLUSH PRIVILEGES;
(2)配置数据库远程连接,允许任意远程主机以用户名为sqoopuser密码为sqoopuser的身份访问数据库。
mysql>GRANT ALL PRIVILEGES ON *.* TO 'sqoopuser'@'%' IDENTIFIED BY 'sqoopuser' WITH GRANT OPTION;
mysql>FLUSH PRIVILEGES;
至此,可以开始操作sqoop的import/export 命令。
4 安装Sqoop
一、解压Sqoop安装包,解压即安装。在/usr/Sqoop文件夹下
tar -zvxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
二、修改配置文件,使环境变量生效(在使用Ambari或者CDH时,配置文件都由平台自动写入配置,不需要自行修改。本步操作针对于单机安装)
1、cd /usr/Sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz/conf
2、mv sqoop-env-template.sh sqoop-env.sh
3、如果要往HBASE里面迁移数据 需要配置 export HBASE_HOME=
还需配置zookeeper
export ZOOCFGDIR=/usr/zookeeper/zookeeper-3.4.10
4、如果要往HIVE里面迁移数据 需要配置 export HIVE_HOME=
5、如果要往hdfs里面迁移数据 需要配置
export HADOOP_COMMON_HOME=/usr/hadoop/hadoop-2.6.5 (hadoop安装目录)
export HADOOP_MAPRED_HOME= /usr/hadoop/hadoop-2.6.5 (mapreduce安装目录
6、zookeeper的配置文件 在往HBASE里迁移数据的时候需要zookeeper

三、在/etc/profile文件 配置Sqoop的环境变量
1、export SQOOP_HOME=/usr/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
2、export PATH=$PATH:$SQOOP_HOME/bin
四、使配置文件生效 source /etc/profile
五、将数据库连接驱动拷贝到$SQOOP_HOME/lib里,驱动版本要保证相对较高。
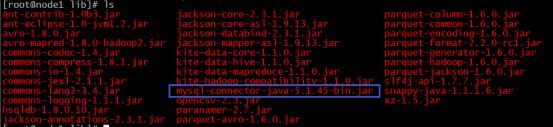
六、测试是否安装成功,sqoop version

5 Sqoop查询命令
# sqoop list-databases --connect jdbc:mysql://192.168.1.7:3306 --username sqoopuser -P
查询Windows主机的数据库 -P为了安全,提示用户输入密码

#sqoop list-tables --connect jdbc:mysql://192.168.1.7:3306/ems --username sqoopuser -password sqoopuser
将指定主机Windows系统下 ems数据库中所有数据表列出来

6 Sqoop与Hdfs之间导入导出
6.1 关系型数据库导入到HDFS(以mysql为例)
# sqoop import --connect jdbc:mysql://master:3306/demo_sqoop --username sqoopuser --password sqoopuser --table sqoop_hdfs_test
默认会有四个split 启动四个mapTask


指定输出路径、指定数据分隔符来导入关系型数据库中的表
# sqoop import --connect jdbc:mysql://master:3306/demo_sqoop --username sqoopuser --password sqoopuser --table sqoop_hdfs_test --target-dir '/sqoop/test1' --fields-terminated-by '\001'
指定MapTask数量 -m,指定之后数据结果会出现同一个文件中,避免文件分散从而导致不易查询。
#sqoop import --connect jdbc:mysql://node1:3306/demo_sqoop --username sqoopuser --password sqoopuser --table sqoop_hdfs_test --target-dir '/sqoop/test2' --fields-terminated-by '\001' -m 1
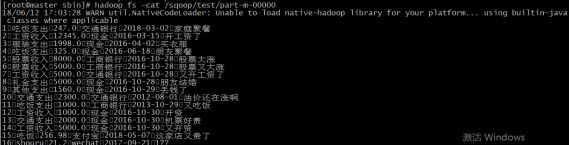
导完之后用以下命令
Hadoop fs -cat /user/root/sqoop_hdfs_test/part-m-00000

指定了输出目录、分隔符、mapTask数量生成的hdfs文件
参数解释:
--connect jdbc:mysql://node1:3306/demo_sqoop 表示远程或者本地 Mysql 服务的URI,3306是Mysql默认监听端口,demo_sqoop是要操作的数据库,若是其他数据库,如Oracle,只需修改URI和驱动即可。
--username sqoopuser表示使用用户sqoopuser连接Mysql。
--password sqoopuser表示使用用户sqoopuser的密码连接Mysql。
--table sqoop_hdfs_test 表示操作的数据表。
--target-dir '/sqoop/test2' 表示导入指定的文件夹目录/sqoop/test2
--fields-terminated-by '\001' 使用’\001’去分隔字段 计算机特殊字符
-m 1 表示启动一个MapReduce程序。不分割
增加where条件, 注意:条件必须用引号引起来
# sqoop import --connect jdbc:mysql://master:3306/demo_sqoop --username sqoopuser --password sqoopuser --table sqoop_hdfs_test --where 'id>1006' --target-dir '/sqoop/test3' --fields-terminated-by '\001' -m 1
增加query语句(使用 \ 将语句换行)
sqoop import --connect jdbc:mysql://node1:3306/demo_sqoop --username sqoopuser --password sqoopuser \
--query 'SELECT id,name,sex FROM sqoop_hdfs_test where id > 1007 AND $CONDITIONS' --split-by sqoop_hdfs_test.id --target-dir '/sqoop/test
注意:如果使用--query这个命令的时候,需要注意的是where后面的参数,AND $CONDITIONS这个参数必须加上而且存在单引号与双引号的区别,如果--query后面使用的是双引号,那么需要在$CONDITIONS前加上\即\$CONDITIONS
6.2 HDFS导出到关系型数据库
#sqoop export --connect jdbc:mysql://master:3306/demo_sqoop --username sqoopuser --password sqoopuser --export-dir '/sqoopexport/data' --table emloyee --columns id,name --fields-terminated-by ',' -m 2
参数解释:
--connect jdbc:mysql://node1:3306/demo_sqoop 表示远程或者本地 Mysql 服务的URI,3306是Mysql默认监听端口,demo_sqoop是要操作的数据库,若是其他数据库,如Oracle,只需修改URI和驱动即可。
--username sqoopuser表示使用用户sqoopuser连接Mysql。
--password sqoopuser表示使用用户sqoopuser的密码连接Mysql。
--export-dir '/sqoopexport/data' 表示需要导出HDFS数据的位置
--table myorder 表示接收数据的数据表。
-columns id,name 表示导入到myorder表里的id和name字段,也可不指定。
--fields-terminated-by ',' 表示HDFS文件内容使用','去分隔字段
-m 2 表示启动两个MapReduce程序。
 可以在关系型数据库查看结果,已经导出成功。
可以在关系型数据库查看结果,已经导出成功。
7 Sqoop与HIve导入导出
7.1 关系型数据库导入Hive
选项参数与上面到如至HDFS几乎一致,可参考上6节内容。
将mysql中sqoop_hive_test的表数据导入到Hive中
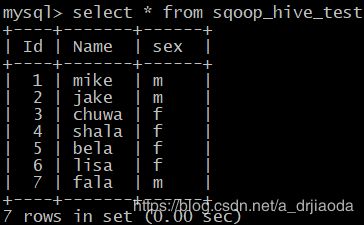
sqoop import --hive-import --connect jdbc:mysql://master:3306/demo_sqoop --username sqoopuser --password sqoopuser --table sqoop_hive_test

7.2 Hive导出到关系型数据库
sqoop export --connect jdbc:mysql://master:3306/demo_sqoop --username sqoopuser --password sqoopuser --table sqoop_hive_export --export-dir /apps/hive/warehouse/sqoop_export_test2 --input-fields-terminated-by '\001'
注意:sqoop导出是根据分隔符去分隔字段值。hive默认的分隔符是‘\001’,sqoop默认的分隔符是',',因此必须指定,否则会报错。
参数解释:
--connect jdbc:mysql://node1:3306/demo_sqoop 表示远程或者本地 Mysql 服务的URI,3306是Mysql默认监听端口,demo_sqoop是要操作的数据库,若是其他数据库,如Oracle,只需修改URI即可。
--username sqoopuser表示使用用户sqoopuser连接Mysql。
--password sqoopuser表示使用用户sqoopuser的密码连接Mysql。
--table sqoop_hive_export 表示操作的要导入的数据表。
--export-dir /apps/hive/warehouse/sqoop_export_test2 导哪个文件夹下面的文件
--input-fields-terminated-by '\001' hive默认的分隔符是‘\001’,sqoop默认的分隔符是','因此需要按照hive的默认去定向指定。
8 Sqoop与Hbase的导入导出
8.1 关系型数据库导入到Hbase
导入:
sqoop import --connect jdbc:mysql://master:3306/demo_sqoop --table sqoop_hbase_import --hbase-table sqoop_import_test --column-family perInfo --hbase-row-key id --hbase-create-table --username sqoopuser --password sqoopuser
参数解释:
--connect jdbc:mysql://node1:3306/demo_sqoop 表示远程或者本地 Mysql 服务的URI,3306是Mysql默认监听端口,demo_sqoop是要操作的数据库,若是其他数据库,如Oracle,只需修改URI即可
--table sqoop_hbase_import 表示导出demo_sqoop数据库的sqoop_hbase_import表。
--hbase-table sqoop_import_test 表示在HBase中建立表sqoop_import_test。
--column-family perInfo 表示在表sqoop_import_test中建立列族perInfo。
--hbase-row-key id 表示表sqoop_import_test的row-key是sqoop_hbase_import表的id字段。
--hbase-create-table 表示在HBase中建立表。
--username sqoopuser表示使用用户sqoopuser连接Mysql。
8.2 Hbase导出到关系型数据库
目前sqoop没有办法把数据直接从Hbase导出到mysql。必须要通过Hive建立2个表,一个外部表是基于这个Hbase表的,另一个是单纯的基于hdfs的hive原生表,然后把外部表的数据导入到原生表(临时),然后通过hive将临时表里面的数据导出到mysql
导出顺序:hbase→hive外部表→hive内部表→sqoop导出→mysql
1、创建hive外部表 (将hbase的表结构与内容映射过去)
CREATE EXTERNALTABLE h_employee(key int, id int, name string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key, info:id,info:name")
TBLPROPERTIES ("hbase.table.name" = "employee");
2、创建外部表
REATE TABLE h_employee_export(key INT, id INT, name STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054';
3、将基于Hbase的外部表导入到新表里面 h_employee_export(原生Hive表)
insert overwrite table h_employee_export select * from h_employe;
4、执行sqoop 导入到已创建好的mysql表里
#sqoop export --connect jdbc:mysql://node1:3306/demo_sqoop --username sqoopuser --password sqoopuser --table employee --export-dir /apps/hive/warehouse/db_hive.db/h_employee_export
声明:大家在百度文库中找到那篇《Sqoop 安装使用文档》,也是本人上传。只是今天才腾出时间,将之前的工作记录都整理了一遍,放入CSDN中。