SVM笔记:Support Vector Machine
目录
1. 绪论
2. SVM算法要解决什么问题
3. 线性SVM算法的数学建模
3.1 决策面方程
3.2 分类“间隔”的计算模型
3.3 约束条件
3.4 线性SVM优化问题基本描述
4. 有约束最优化问题的数学模型
4.1 有约束优化问题的几何意象
4.2 拉格朗日乘子法
1)最优解的特点分析
2)构造拉格朗日函数
4.3 KKT条件
3.4 拉格朗日对偶:未完
1. 绪论
如果你是一名模式识别专业的研究生,又或者你是机器学习爱好者,SVM是一个你避不开的问题。如果你只是有一堆数据需要SVM帮你处理一下,那么无论是Matlab的SVM工具箱,LIBSVM还是python框架下的SciKit Learn都可以提供方便快捷的解决方案。但如果你要追求的不仅仅是会用,还希望挑战一下“理解”这个层次,那么你就需要面对一大堆你可能从来没听过的名词,比如:非线性约束条件下的最优化、KKT条件、拉格朗日对偶、最大间隔、最优下界、核函数等等。这些名词往往会跟随一大堆天书一般的公式。如果你稍微有一点数学基础,那么单个公式你可能看得明白,但是怎么从一个公式跳到另一个公式就让人十分费解了,而最让人糊涂的其实并不是公式推导,而是如果把这些公式和你脑子里空间构想联系起来。
我本人就是上述问题的受害者之一。我翻阅了很多关于SVM的书籍和资料,但没有找到一份材料能够在公式推导、理论介绍,系统分析、变量说明、代数和几何意义的解释等方面完整地对SVM加以分析和说明的。换言之,对于普通的一年级非数学专业的研究生而言,要想看懂SVM需要搜集很多资料,然后对照阅读和深入思考,才可能比较透彻地理解SVM算法。由于我本人也在东北大学教授面向一年级硕士研究生的《模式识别技术与应用》课程,因此希望能总结出一份相对完整、简单和透彻的关于SVM算法的介绍文字,以便学生能够快速准确地理解SVM算法。
以下我会分为四个步骤对最基础的线性SVM问题加以介绍,分别是1)问题原型,2)数学模型,3)最优化求解,4)几何解释。我尽可能用最简单的语言和最基本的数学知识对上述问题进行介绍,希望能对困惑于SVM算法的学生有所帮助。由于个人时间有限,只能找空闲的时间更新,速度会比较慢,请大家谅解。
2. SVM算法要解决什么问题
SVM的全称是Support Vector Machine,即支持向量机,主要用于解决模式识别领域中的数据分类问题,属于有监督学习算法的一种。SVM要解决的问题可以用一个经典的二分类问题加以描述。如图1所示,红色和蓝色的二维数据点显然是可以被一条直线分开的,在模式识别领域称为线性可分问题。然而将两类数据点分开的直线显然不止一条。图1(b)和(c)分别给出了A、B两种不同的分类方案,其中黑色实线为分界线,术语称为“决策面”。每个决策面对应了一个线性分类器。虽然在目前的数据上看,这两个分类器的分类结果是一样的,但如果考虑潜在的其他数据,则两者的分类性能是有差别的。
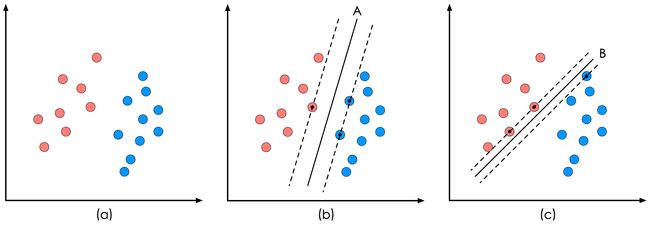
图1 二分类问题描述
SVM算法认为图1中的分类器A在性能上优于分类器B,其依据是A的分类间隔比B要大。这里涉及到第一个SVM独有的概念“分类间隔”。在保证决策面方向不变且不会出现错分样本的情况下移动决策面,会在原来的决策面两侧找到两个极限位置(越过该位置就会产生错分现象),如虚线所示。虚线的位置由决策面的方向和距离原决策面最近的几个样本的位置决定。而这两条平行虚线正中间的分界线就是在保持当前决策面方向不变的前提下的最优决策面。两条虚线之间的垂直距离就是这个最优决策面对应的分类间隔。显然每一个可能把数据集正确分开的方向都有一个最优决策面(有些方向无论如何移动决策面的位置也不可能将两类样本完全分开),而不同方向的最优决策面的分类间隔通常是不同的,那个具有“最大间隔”的决策面就是SVM要寻找的最优解。而这个真正的最优解对应的两侧虚线所穿过的样本点,就是SVM中的支持样本点,称为“支持向量”。对于图1中的数据,A决策面就是SVM寻找的最优解,而相应的三个位于虚线上的样本点在坐标系中对应的向量就叫做支持向量。
从表面上看,我们优化的对象似乎是这个决策面的方向和位置。但实际上最优决策面的方向和位置完全取决于选择哪些样本作为支持向量。而在经过漫长的公式推导后,你最终会发现,其实与线性决策面的方向和位置直接相关的参数都会被约减掉,最终结果只取决于样本点的选择结果。
到这里,我们明确了SVM算法要解决的是一个最优分类器的设计问题。既然叫作最优分类器,其本质必然是个最优化问题。所以,接下来我们要讨论的就是如何把SVM变成用数学语言描述的最优化问题模型,这就是我们在第二部分要讲的“线性SVM算法的数学建模”。
关于“决策面”,为什么叫决策面,而不是决策线?好吧,在图1里,样本是二维空间中的点,也就是数据的维度是2,因此1维的直线可以分开它们。但是在更加一般的情况下,样本点的维度是n,则将它们分开的决策面的维度就是n-1维的超平面(可以想象一下3维空间中的点集被平面分开),所以叫“决策面”更加具有普适性,或者你可以认为直线是决策面的一个特例。
3. 线性SVM算法的数学建模
一个最优化问题通常有两个最基本的因素:
- 1)目标函数,也就是你希望什么东西的什么指标达到最好。
- 2)优化对象,你期望通过改变哪些因素来使你的目标函数达到最优。
在线性SVM算法中,目标函数显然就是那个“分类间隔”,而优化对象则是决策面。所以要对SVM问题进行数学建模,首先要对上述两个对象(“分类间隔”和“决策面”)进行数学描述。按照一般的思维习惯,我们先描述决策面。
3.1 决策面方程
(请注意,以下的描述对于线性代数及格的同学可能显得比较啰嗦,但请你们照顾一下用高数课治疗失眠的同学们。)
请你暂时不要纠结于n维空间中的n-1维超平面这种超出正常人想象力的情景。我们就老老实实地看看二维空间中的一根直线,我们从初中就开始学习的直线方程形式很简单。
![]()
现在我们做个小小的改变,让原来的轴变成轴,变成轴,于是公式(2.1)中的直线方程会变成下面的样子

公式(2.3)的向量形式可以写成
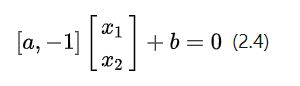
考虑到我们在等式两边乘上任何实数都不会改变等式的成立,所以我们可以写出一个更加一般的向量表达形式:
![]()
看到变量略显粗壮的身体了吗?他们是黑体,表示变量是个向量,,。一般我们提到向量的时候,都默认他们是个列向量,所以我在方括号[ ]后面加上了上标T,表示转置(我知道我真的很啰嗦,但是关于“零基础”三个字,我是认真的。),它可以帮忙把行向量竖过来变成列向量,所以在公式(2.5)里面后面的转置符号T,会把列向量又转回到行向量。这样一个行向量和一个列向量就可快快乐乐的按照矩阵乘法的方式结合,变成一个标量,然后好跟后面的标量相加后相互抵消变成0。
就着公式(2.5),我们再稍稍尝试深入一点。那就是探寻一下向量和标量的几何意义是什么。让我们回到公式(2.4),对比公式(2.5),可以发现此时的。然后再去看公式(2.2),还记得那条我们熟悉的直线方程中的a的几何意义吗?对的,那是直线的斜率。如果我们构造一个向量(可以理解为表示直线经过原点,可以表示出斜率为a的直线),它应该跟我们的公式(2.2)描述的直线平行。然后我们求一下两个向量的点积,你会惊喜地发现结果是0。我们管这种现象叫作“两个向量相互正交”。通俗点说就是两个向量相互垂直。当然,你也可以在草稿纸上自己画出这两个向量,比如让,你会发现在第一象限,与横轴夹角为60°,而在第四象限与横轴夹角为30°,所以很显然他们两者的夹角为90°。
你现在是不是已经忘了我们讨论正交或者垂直的目的是什么了?那么请把你的思维从坐标系上抽出来,回到决策面方程上来。我是想告诉你向量跟直线 是相互垂直的,也就是说控制了直线的方向。另外,还记得小时候我们学过的那个叫做截距的名词吗?对了,就是截距,它控制了直线的位置。
然后,在本小节的末尾,我冒昧地提示一下,在n维空间中n-1维的超平面的方程形式也是公式(2.5)的样子,只不过向量的维度从原来的2维变成了n维。如果你还是想不出来超平面的样子,也很正常。那么就请你始终记住平面上它们的样子也足够了。
到这里,我们花了很多篇幅描述一个很简单的超平面方程(其实只是个直线方程),这里真正有价值的是这个控制方向的参数。接下来,你会有很长一段时间要思考它到底是个什么东西,对于SVM产生了怎样的影响。
3.2 分类“间隔”的计算模型
我们在第二章里介绍过分类间隔的定义及其直观的几何意义。间隔的大小实际上就是支持向量对应的样本点到决策面的距离的二倍,如图2所示。

图2 分类间隔计算
所以分类间隔计算似乎相当简单,无非就是点到直线的距离公式。如果你想要回忆高中老师在黑板上推导的过程,可以随便在百度文库里搜索关键词“点到直线距离推导公式”,你会得到至少6、7种推导方法。但这里,请原谅我给出一个简单的公式如下:
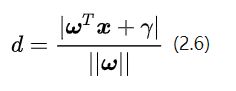
这里是向量的模,表示在空间中向量的长度,就是支持向量样本点的坐标。就是决策面方程的参数。而追求的最大化也就是寻找的最大化。看起来我们已经找到了目标函数的数学形式。但问题当然不会这么简单,我们还需要面对一连串令人头疼的麻烦。
3.3 约束条件
接着3.2节的结尾,我们讨论一下究竟还有哪些麻烦没有解决:
- 1)并不是所有的方向都存在能够实现100%正确分类的决策面,我们如何判断一条直线是否能够将所有的样本点都正确分类?
- 2)即便找到了正确的决策面方向,还要注意决策面的位置应该在间隔区域的中轴线上,所以用来确定决策面位置的截距也不能自由的优化,而是受到决策面方向和样本点分布的约束。
- 3)即便取到了合适的方向和截距,公式(2.6)里面的不是随随便便的一个样本点,而是支持向量对应的样本点。对于一个给定的决策面,我们该如何找到对应的支持向量?
以上三条麻烦的本质是“约束条件”,也就是说我们要优化的变量的取值范围受到了限制和约束。事实上约束条件一直是最优化问题里最让人头疼的东西。但既然我们已经论证了这些约束条件确实存在,就不得不用数学语言对他们进行描述。尽管上面看起来是3条约束,但SVM算法通过一些巧妙的小技巧,将这三条约束条件融合在了一个不等式里面。
我们首先考虑一个决策面是否能够将所有的样本都正确分类的约束。图2中的样本点分成两类(红色和蓝色),我们为每个样本点加上一个类别标签:

如果我们的决策面方程能够完全正确地对图2中的样本点进行分类,就会满足下面的公式
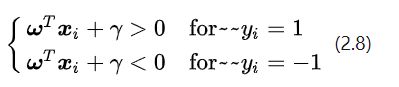
如果我们要求再高一点,假设决策面正好处于间隔区域的中轴线上,并且相应的支持向量对应的样本点到决策面的距离为d,那么公式(2.8)就可以进一步写成:
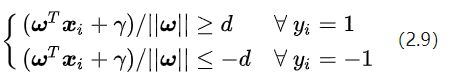
符号是“对于所有满足条件的” 的缩写。我们对公式(2.9)中的两个不等式的左右两边除上d,就可得到:

其中:
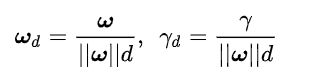
把 和就当成一条直线的方向矢量和截距。你会发现事情没有发生任何变化,因为直线和直线其实是一条直线。现在,现在让我忘记原来的直线方程参数和,我们可以把参数 和重新起个名字,就叫它们和。我们可以直接说:“对于存在分类间隔的两类样本点,我们一定可以找到一些决策面,使其对于所有的样本点均满足下面的条件:”
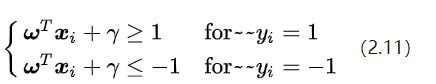
公式(2.11)可以认为是SVM优化问题的约束条件的基本描述。
3.4 线性SVM优化问题基本描述
公式(2.11)里面的情况什么时候会发生呢,参考一下公式(2.9)就会知道,只有当是决策面所对应的支持向量样本点时,等于1或-1的情况才会出现。这一点给了我们另一个简化目标函数的启发。回头看看公式(2.6),你会发现等式右边分子部分的绝对值符号内部的表达式正好跟公式(2.11)中不等式左边的表达式完全一致,无论原来这些表达式是1或者-1,其绝对值都是1。所以对于这些支持向量样本点有:
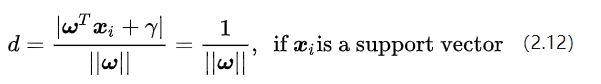
公式(2.12)的几何意义就是,支持向量样本点到决策面方程的距离就是。我们原来的任务是找到一组参数使得分类间隔最大化,根据公式(2.12)就可以转变为的最小化问题,也等效于的最小化问题。我们之所以要在上加上平方和1/2的系数,是为了以后进行最优化的过程中对目标函数求导时比较方便,但这绝不影响最优化问题最后的解。
另外我们还可以尝试将公式(2.11)给出的约束条件进一步在形式上精练,把类别标签和两个不等式左边相乘,形成统一的表述:

好了,到这里我们可以给出线性SVM最优化问题的数学描述了:
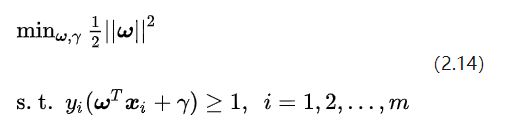
这里m是样本点的总个数,缩写s. t. 表示“Subject to”,是“服从某某条件”的意思。公式(2.14)描述的是一个典型的不等式约束条件下的二次型函数优化问题,同时也是支持向量机的基本数学模型。(此时此刻,你也许会回头看3.3节我们提出的三个约束问题,思考它们在公式2.14的约束条件中是否已经得到了充分的体现。但我不建议你现在就这么做,因为2.14采用了一种比较含蓄的方式表示这些约束条件,所以你即便现在不理解也没关系,后面随着推导的深入,这些问题会一点点露出真容。)
接下来,我们将在第三章讨论大多数同学比较陌生的问题:如何利用最优化技术求解公式(2.14)描述的问题。哪些令人望而生畏的术语,凸二次优化、拉格朗日对偶、KKT条件、鞍点等等,大多出现在这个部分。全面理解和熟练掌握这些概念当然不容易,但如果你的目的主要是了解这些技术如何在SVM问题进行应用的,那么阅读过下面一章后,你有很大的机会可以比较直观地理解这些问题。
(*一点小建议,读到这里,你可以试着在纸上随便画一些点,然后尝试用SVM的思想手动画线将两类不同的点分开。你会发现大多数情况下,你会先画一条可以成功分开两类样本点的直线,然后你会在你的脑海中想象去旋转这条线,旋转到某个角度,你就会下意识的停下来,因为如果再旋转下去,就找不到能够成功将两类点分开的直线了。这个过程就是对直线方向的优化过程。对于有些问题,你会发现SVM的最优解往往出现在不能再旋转下去的边界位置,这就是约束条件的边界,对比我们提到的等式约束条件,你会对代数公式与几何想象之间的关系得到一些相对直观的印象。)
4. 有约束最优化问题的数学模型
(Hi,好久不见)就像我们在第三部分结尾时提到的,SVM问题是一个不等式约束条件下的优化问题。绝大多数模式识别教材在讨论这个问题时都会在附录中加上优化算法的简介,虽然有些写得未免太简略,但看总比不看强,所以这时候如果你手头有一本模式识别教材,不妨翻到后面找找看。结合附录看我下面写的内容,也许会有帮助。
我们先解释一下我们下面讲解的思路以及重点关注哪些问题:
- 1)有约束优化问题的几何意象:闭上眼睛你看到什么?
- 2)拉格朗日乘子法:约束条件怎么跑到目标函数里面去了?
- 3)KKT条件:约束条件是不等式该怎么办?
- 4)拉格朗日对偶:最小化问题怎么变成了最大化问题?
- 5)实例演示:拉格朗日对偶函数到底啥样子?
- 6)SVM优化算法的实现:数学讲了辣么多,到底要怎么用啊?
4.1 有约束优化问题的几何意象
约束条件一般分为等式约束和不等式约束两种,前者表示为(注意这里的跟第三章里面的样本x没有任何关系,只是一种通用的表示);后者表示为(你可能会问为什么不是,别着急,到KKT那里你就明白了)。
假设(就是这个向量一共有d个标量组成),则的几何意象就是d维空间中的d-1维曲面,如果函数是线性的,则是个d-1维的超平面。那么有约束优化问题就要求在这个d-1维的曲面或者超平面上找到能使得目标函数最小的点,这个d-1维的曲面就是“可行解区域”。
对于不等式约束条件,,则可行解区域从d-1维曲面扩展成为d维空间的一个子集。我们可以从d=2的二维空间进行对比理解。等式约束对应的可行解空间就是一条线;不等式约束对应的则是这条线以及线的某一侧对应的区域,就像下面这幅图的样子(图中的目标函数等高线其实就是等值线,在同一条等值线上的点对应的目标函数值相同)。
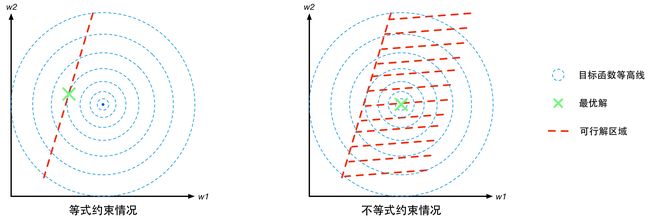
图3 有约束优化问题的几何意象图
4.2 拉格朗日乘子法
尽管在4.1节我们已经想象出有约束优化问题的几何意象。可是如何利用代数方法找到这个被约束了的最优解呢?这就需要用到拉格朗日乘子法。
首先定义原始目标函数,拉格朗日乘子法的基本思想是把约束条件转化为新的目标函数的一部分(关于的意义我们一会儿再解释),从而使有约束优化问题变成我们习惯的无约束优化问题。那么该如何去改造原来的目标函数使得新的目标函数的最优解恰好就在可行解区域中呢?这需要我们去分析可行解区域中最优解的特点。
1)最优解的特点分析
这里比较有代表性的是等式约束条件(不等式约束条件的情况我们在KKT条件里再讲)我们观察一下图3中的红色虚线(可行解空间)和蓝色虚线(目标函数的等值线),发现这个被约束的最优解恰好在二者相切的位置。这是个偶然吗?我可以负责任地说:“NO!它们温柔的相遇,是三生的宿命。”为了解释这个相遇,我们先介绍梯度的概念。梯度可以直观的认为是函数的变化量,可以描述为包含变化方向和变化幅度的一个向量。然后我们给出一个推论:
推论1:“在那个宿命的相遇点(也就是等式约束条件下的优化问题的最优解),原始目标函数的梯度向量必然与约束条件的切线方向垂直。”
关于推论1的粗浅的论证如下:
如果梯度矢量不垂直于在点的切线方向,就会在的切线方向上存在不等于0的分量,也就是说在相遇点附近,还在沿着变化。这意味在上这一点的附近一定有一个点的函数值比更小,那么就不会是那个约束条件下的最优解了。所以,梯度向量必然与约束条件的切线方向垂直。(有些难理解)
推论2:“函数的梯度方向也必然与函数自身等值线切线方向垂直。”
推论2的粗浅论证:与推论1 的论证基本相同,如果的梯度方向不垂直于该点等值线的切线方向,就会在等值线上有变化,这条线也就不能称之为等值线了。
根据推论1和推论2,函数的梯度方向在点同时垂直于约束条件和自身的等值线的切线方向,也就是说函数的等值线与约束条件曲线在点具有相同(或相反)的法线方向,所以它们在该点也必然相切。
让我们再进一步,约束条件也可以被视为函数的一条等值线。按照推论2中“函数的梯度方向必然与自身的等值线切线方向垂直”的说法,函数在点的梯度矢量也与的切线方向垂直。
到此我们可以将目标函数和约束条件视为两个具有平等地位的函数,并得到推论3:
推论3:“函数与函数的等值线在最优解点处相切,即两者在点的梯度方向相同或相反”,
于是我们可以写出公式(3.1),用来描述最优解的一个特性:
(3.1)
这里增加了一个新变量,用来描述两个梯度矢量的长度比例。那么是不是有了公式(3.1)就能确定的具体数值了呢?显然不行!从代数解方程的角度看,公式(3.1)相当于d个方程(假设是d维向量,函数的梯度就是d个偏导数组成的向量,所以公式(2.15)实际上是1个d维矢量方程,等价于d个标量方程),而未知数除了的d个分量以外,还有1个。所以相当于用d个方程求解d+1个未知量,应有无穷多组解;从几何角度看,在任意曲线(k为值域范围内的任意实数)上都能至少找到一个满足公式(3.1)的点,也就是可以找到无穷多个这样的相切点。所以我们还需要增加一点限制,使得无穷多个解变成一个解。好在这个限制是现成的,那就是:
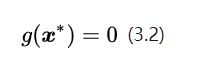
把公式(3.1)和(3.2)放在一起,我们有d+1个方程,解d+1个未知数,方程有唯一解,这样就能找到这个最优点了。
2)构造拉格朗日函数
虽然根据公式(3.1)和(3.2),已经可以求出等式约束条件下的最优解了,但为了在数学上更加便捷和优雅一点,我们按照本节初提到的思想,构造一个拉格朗日函数,将有约束优化问题转为无约束优化问题。拉格朗日函数具体形式如下:
(3.3)
新的拉格朗日目标函数有两个自变量,根据我们熟悉的求解无约束优化问题的思路,将公式(3.3)分别对求导,令结果等于零,就可以建立两个方程。同学们可以自己试一下,很容易就能发现这两个由导数等于0构造出来的方程正好就是公式(3.1)和(3.2)。说明新构造的拉格朗日目标函数的优化问题完全等价于原来的等式约束条件下的优化问题。
至此,我们说明白了“为什么构造拉格朗日目标函数可以实现等式约束条件下的目标优化问题的求解”。可是,我们回头看一下公式(2.14),也就是我们的SVM优化问题的数学表达。囧,约束条件是不等式啊!怎么办呢?
4.3 KKT条件
对于不等式约束条件的情况,如图4所示,最优解所在的位置有两种可能,或者在边界曲线上或者在可行解区域内部满足不等式的地方。
第一种情况:最优解在边界上,就相当于约束条件就是。参考图4,注意此时目标函数的最优解在可行解区域外面,所以函数在最优解附近的变化趋势是“在可行解区域内侧较大而在区域外侧较小”,与之对应的是函数在可行解区域内小于0,在区域外大于零,所以在最优解附近的变化趋势是内部较小而外部较大。这意味着目标函数的梯度方向与约束条件函数的梯度方向相反。因此根据公式(3.1),可以推断出参数.
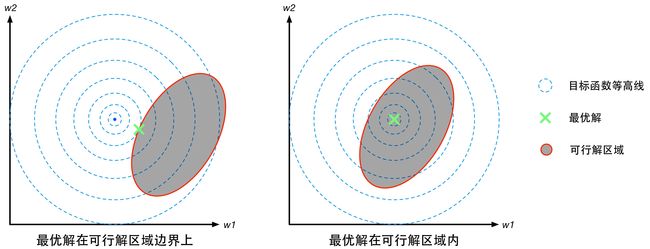
图4:不等式约束条件下最优解位置分布的两种情况
第二种情况:如果在区域内,则相当于约束条件没有起作用,因此公式(3.3)的拉格朗日函数中的参数。整合这两种情况,可以写出一个约束条件的统一表达,如公式(3.4)所示。
(3.4)
其中第一个式子是约束条件本身。第二个式子是对拉格朗日乘子的描述。第三个式子是第一种情况和第二种情况的整合:在第一种情况里,;在第二种情况下,。所以无论哪一种情况都有。公式(3.4)就称为Karush-Kuhn-Tucker条件,简称KKT条件。
推导除了KKT条件,感觉有点奇怪。因为本来问题的约束条件就是一个,怎么这个KKT条件又多弄出来两条,这不是让问题变得更复杂了吗?这里我们要适当的解释一下:
1)KKT条件是对最优解的约束,而原始问题中的约束条件是对可行解的约束。
2)KKT条件的推导对于后面马上要介绍的拉格朗日对偶问题的推导很重要。
3.4 拉格朗日对偶:未完
参考:https://zhuanlan.zhihu.com/p/24638007