TensorFlow2.0笔记16:ResNet介绍以及在CIFAR-100数据集上实战ResNet-18和ResNet-34!
| ResNet介绍以及在CIFAR-100数据集上实战ResNet-18和ResNet-34! |
文章目录
- 一、ResNet介绍
- 1.1、ResNet-34的基本结构
- 1.2、为什么叫残差?
- 1.2、tensorflow中如何实现基本的残差块
- 1.3、tensorflow中如何实现基本的残差块
- 二、ResNet实战
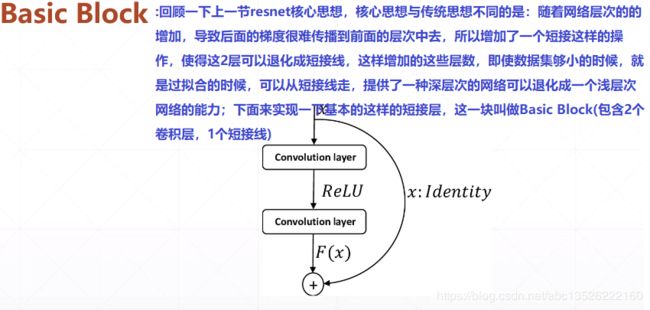
- 2.1、回顾Basic Block
- 2.2、实现Basic Block
- 2.3、实现Res Block(多个Basic Block堆叠一起组成)
- 2.4、ResNet-18中18的由来以及最终演示结果
- 2.5、ResNet-34的最终演示结果
- 2.6、Out of memory情况解决办法
- 三、需要全套课程视频+PPT+代码资源可以私聊我!
一、ResNet介绍
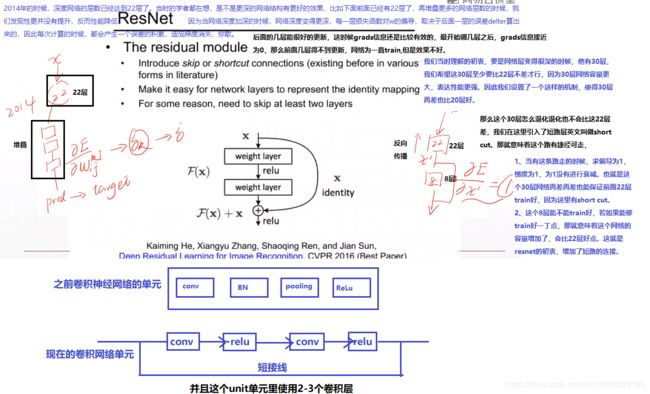
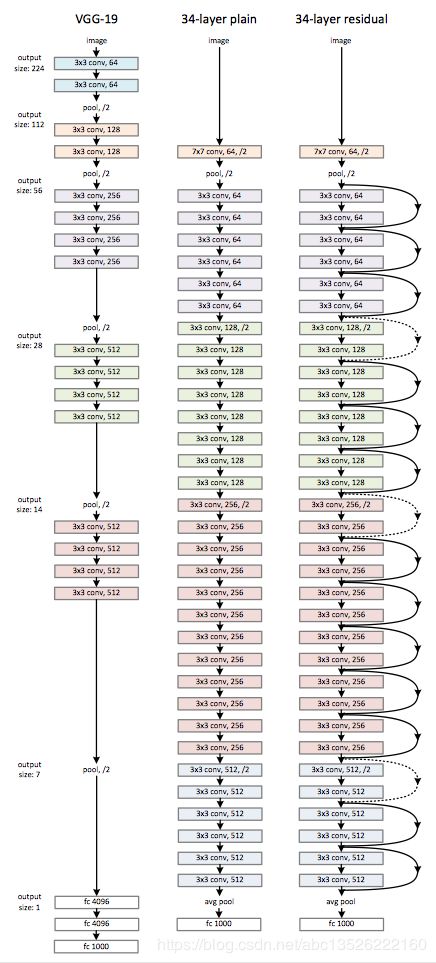
1.1、ResNet-34的基本结构
- 最左边为VGG19,也就是19层,这里画法非常有讲究的,比如左中特意留了一个空白,就意味着我们的34层通过加了一个short cut之后,至少至少也能退化到一个直连接就是VGG19
- 用的最多的比如34层,56层,152层了。
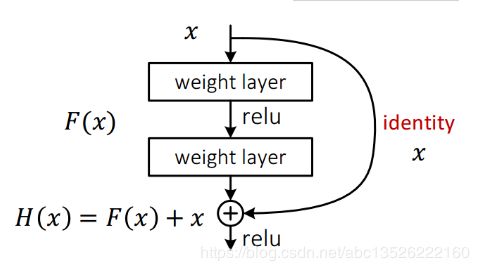
1.2、为什么叫残差?
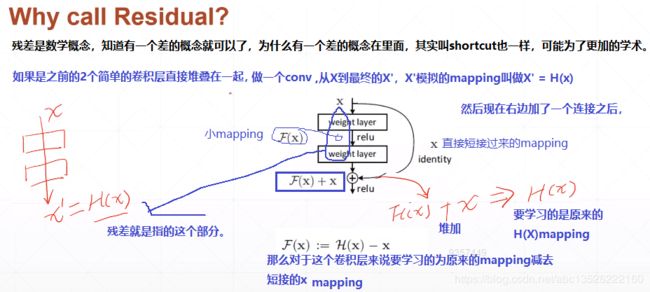
- 从下图可以看出,数据经过了两条路线,一条是常规路线,另一条则是捷径(shortcut),直接实现单位映射的直接连接的路线,这有点类似与电路中的“短路”。通过实验,这种带有shortcut的结构确实可以很好地应对退化问题。我们把网络中的一个模块的输入和输出关系看作是y=H(x),那么直接通过梯度方法求H(x)就会遇到上面提到的退化问题,如果使用了这种带shortcut的结构,那么可变参数部分的优化目标就不再是H(x),若用F(x)来代表需要优化的部分的话,则H(x)=F(x)+x,也就是F(x)=H(x)-x。因为在单位映射的假设中y=x就相当于观测值,所以F(x)就对应着残差,因而叫残差网络。为啥要这样做,因为作者认为学习残差F(X)比直接学习H(X)简单!设想下,现在根据我们只需要去学习输入和输出的差值就可以了,绝对量变为相对量(H(x)-x 就是输出相对于输入变化了多少),优化起来简单很多。
- 考虑到x的维度与F(X)维度可能不匹配情况,需进行维度匹配。这里论文中采用两种方法解决这一问题(其实是三种,但通过实验发现第三种方法会使performance急剧下降,故不采用):
- zero_padding:对恒等层进行0填充的方式将维度补充完整。这种方法不会增加额外的参数
- projection:在恒等层采用1x1的卷积核来增加维度。这种方法会增加额外的参数
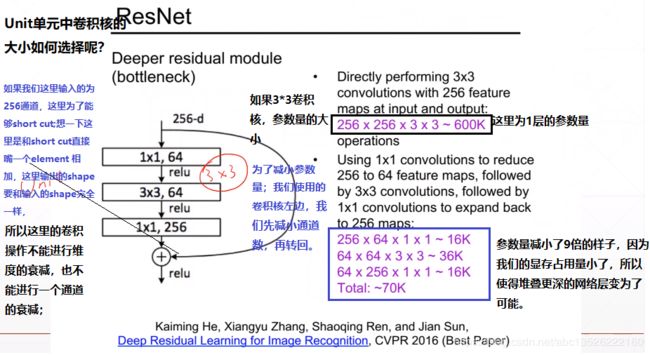
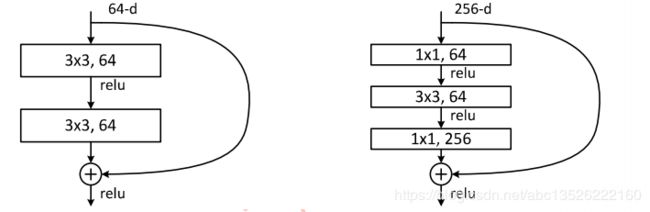
- 下图展示了两种形态的残差模块,左图是常规残差模块,有两个3×3卷积核卷积核组成,但是随着网络进一步加深,这种残差结构在实践中并不是十分有效。针对这问题,右图的“瓶颈残差模块”(bottleneck residual block)可以有更好的效果,它依次由1×1、3×3、1×1这三个卷积层堆积而成,这里的1×1的卷积能够起降维或升维的作用,从而令3×3的卷积可以在相对较低维度的输入上进行,以达到提高计算效率的目的。
1.2、tensorflow中如何实现基本的残差块
1.3、tensorflow中如何实现基本的残差块
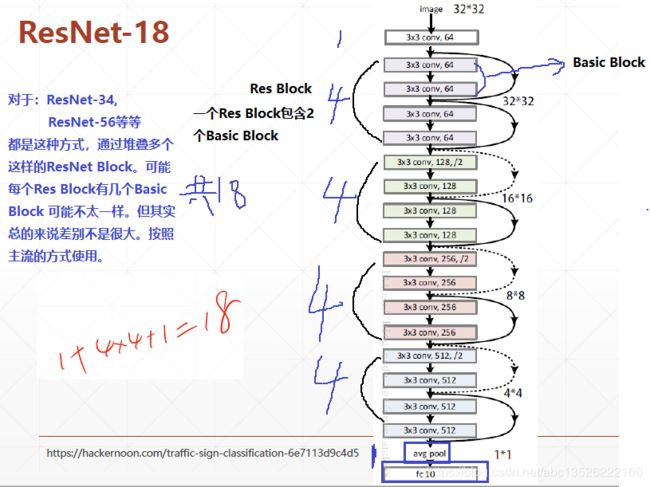
- 上面只是介绍了一个Basic Block,在ResNet里面,基本的单元并不是一个Basic Block。它是由多个Basic Block堆叠而成,堆叠成一整块叫做Res Block。
- 创建Res Block
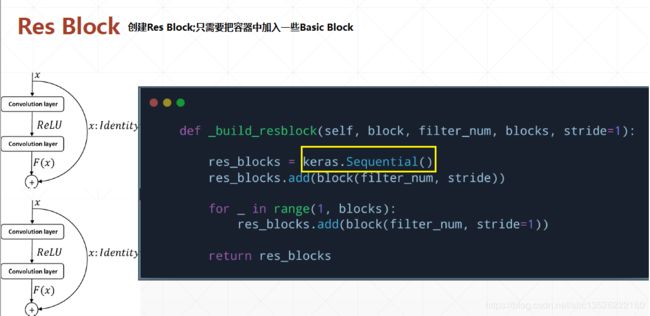
- ResNet-18是如何形成的呢?
二、ResNet实战
2.1、回顾Basic Block
2.2、实现Basic Block
import tensorflow as tf
from tensorflow.python.keras import layers, Sequential
import tensorflow.keras as keras
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
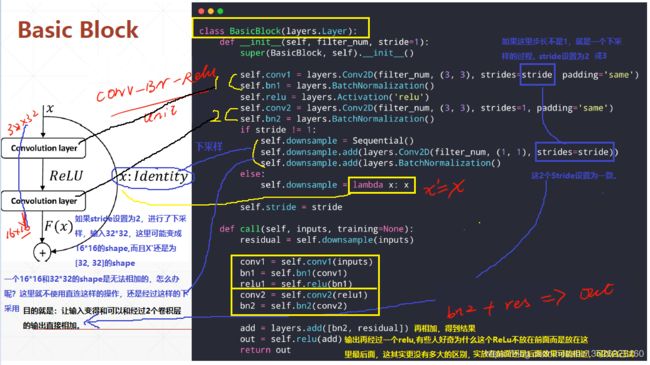
class BasicBlock(layers.Layer):
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = layers.Conv2D(filter_num, kernel_size=[3, 3], strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
#上一块如果做Stride就会有一个下采样,在这个里面就不做下采样了。这一块始终保持size一致,把stride固定为1
self.conv2 = layers.Conv2D(filter_num, kernel_size=[3, 3], stride=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1:
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, kernel_size=[1, 1], strides=stride)) #保持stride相同
else:
self.downsample = lambda x:x
def call(self, inputs, training=None):
# [b, h, w, c]
out = self.con1(inputs) #首先调用:__call()__ => call()
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
identity = self.downsample(inputs)
output = layers.add([out, identity]) #layers下面有一个add,把这2个层添加进来相加。
output = tf.nn.relu(output)
2.3、实现Res Block(多个Basic Block堆叠一起组成)
- 我们实现了Basic Block之后,但是Basic Block并不是resnet的基本单元,它的基本单元叫做Res Block,也就是Res Block是由多个这样的Basic Block堆叠一起组成的。
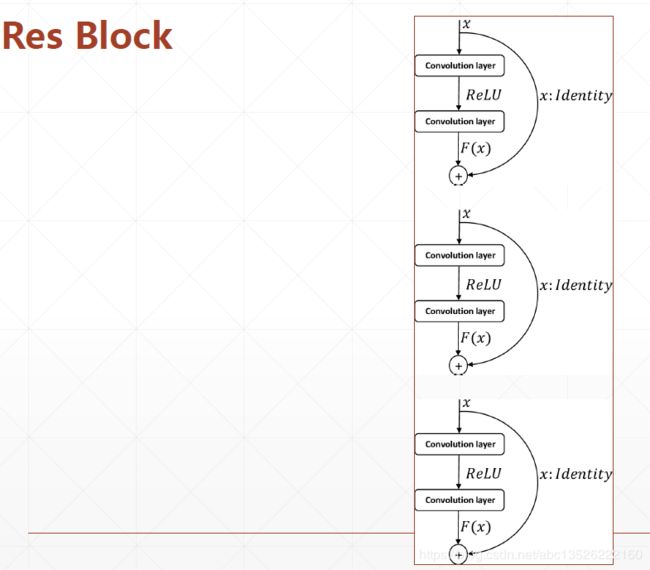
- 实现代码如下:
# Res Block 模块。继承keras.Model或者keras.Layer都可以
class ResNet(keras.Model):
# 第一个参数layer_dims:[2, 2, 2, 2] 4个Res Block,每个包含2个Basic Block
# 第二个参数num_classes:我们的全连接输出,取决于输出有多少类。
def __init__(self, layer_dims, num_classes):
super(ResNet, self).__init__()
# 预处理层;实现起来比较灵活可以加 MAXPool2D,可以没有。
self.stem = Sequential([layers.Conv2D(64, (3,3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')])
# 创建4个Res Block;注意第1项不一定以2倍形式扩张,都是比较随意的,这里都是经验值。
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# 残差网络输出output: [b, 512, h, w];长宽无法确定,上面的需要运算一下,如果这里没有办法确定的话。
# 用这个层可以自适应的确定输出。表示不管你的长和宽是多少,我会在某一个channel上面,所有的长和宽像素值加起来
# 求一个均值,比如:有512个3*3的feature map,[512, 3, 3],每个feature map为3*3,9个像素值,我做一个这样的
# average,得到一个平均的像素值是多少。下面这里处理之后得到一个512的vector,准确来说为[512, 1, 1],这个512的
# vector就可以送到先形成进行分类。
self.avgpool = layers.GlobalAveragePooling2D
# 全连接层:为了分类
self.fc = layers.Dense(num_classes)
def call(self,inputs, training=None):
# __init__中准备工作完毕;下面完成前向运算过程。
x = self.stem(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 做一个global average pooling,得到之后只会得到一个channel,不需要做reshape操作了。
# shape为 [batchsize, channel]
x = self.avgpool(x)
# [b, 100]
x = self.fc(x)
return x
# 实现 Res Block; 创建一个Res Block
def build_resblock(self, filter_num, block, stride=1):
res_blocks = Sequential()
# may down sample 也许进行下采样。
# 对于当前Res Block中的Basic Block,我们要求每个Res Block只有一次下采样的能力。
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):
res_blocks.add(BasicBlock(filter_num, stride=1,)) # 这里stride设置为1,只会在第一个Basic Block做一个下采样。
return res_blocks
2.4、ResNet-18中18的由来以及最终演示结果

补充:下面需要使用的。
- 介绍一下global average pooling ,这个概念出自于 network in network;global average pooling 与 average pooling 的差别就在 “global” 这一个字眼上。global 与 local 在字面上都是用来形容 pooling 窗口区域的。 local 是取 feature map 的一个子区域求平均值,然后滑动这个子区域; global 显然就是对整个 feature map 求平均值了。
- 主要是用来解决全连接的问题,其主要是是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量进行softmax中进行计算
- 举个例子:假如,最后的一层的数据是10个6×6的特征图,global average pooling是将每一张特征图计算所有像素点的均值,输出一个数据值。这样10 个特征图就会输出10个数据点,将这些数据点组成一个1×10的向量的话,就成为一个特征向量,就可以送入到softmax的分类中计算了;图中是:对比全连接与全局均值池化的差异

- 代码模块1:resnet.py文件:
import tensorflow as tf
from tensorflow.keras import layers, Sequential
import tensorflow.keras as keras
# Basic Block 模块。
class BasicBlock(layers.Layer):
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
#上一块如果做Stride就会有一个下采样,在这个里面就不做下采样了。这一块始终保持size一致,把stride固定为1
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1:
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:
self.downsample = lambda x:x
def call(self, inputs, training=None):
# [b, h, w, c]
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
identity = self.downsample(inputs)
output = layers.add([out, identity]) #layers下面有一个add,把这2个层添加进来相加。
output = tf.nn.relu(output)
return output
# Res Block 模块。继承keras.Model或者keras.Layer都可以
class ResNet(keras.Model):
# 第一个参数layer_dims:[2, 2, 2, 2] 4个Res Block,每个包含2个Basic Block
# 第二个参数num_classes:我们的全连接输出,取决于输出有多少类。
def __init__(self, layer_dims, num_classes=100):
super(ResNet, self).__init__()
# 预处理层;实现起来比较灵活可以加 MAXPool2D,可以没有。
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# 创建4个Res Block;注意第1项不一定以2倍形式扩张,都是比较随意的,这里都是经验值。
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
self.avgpool = layers.GlobalAveragePooling2D()
self.fc = layers.Dense(num_classes)
def call(self,inputs, training=None):
# __init__中准备工作完毕;下面完成前向运算过程。
x = self.stem(inputs)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 做一个global average pooling,得到之后只会得到一个channel,不需要做reshape操作了。
# shape为 [batchsize, channel]
x = self.avgpool(x)
# [b, 100]
x = self.fc(x)
return x
# 实现 Res Block; 创建一个Res Block
def build_resblock(self, filter_num, blocks, stride=1):
res_blocks = Sequential()
# may down sample 也许进行下采样。
# 对于当前Res Block中的Basic Block,我们要求每个Res Block只有一次下采样的能力。
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks):
res_blocks.add(BasicBlock(filter_num, stride=1)) # 这里stride设置为1,只会在第一个Basic Block做一个下采样。
return res_blocks
def resnet18():
return ResNet([2, 2, 2, 2])
# 如果我们要使用 ResNet-34 的话,那34是怎样的配置呢?只需要改一下这里就可以了。对于56,152去查一下配置
def resnet34():
return ResNet([3, 4, 6, 3]) #4个Res Block,第1个包含3个Basic Block,第2为4,第3为6,第4为3
- 代码模块2:resnet18_train.py文件:
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
from resnet import resnet18
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.random.set_seed(2345)
# 数据预处理,仅仅是类型的转换。 [-1~1]
def preprocess(x, y):
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 0.5
y = tf.cast(y, dtype=tf.int32)
return x, y
# 数据集的加载
(x, y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y) # 或者tf.squeeze(y, axis=1)把1维度的squeeze掉。
y_test = tf.squeeze(y_test) # 或者tf.squeeze(y, axis=1)把1维度的squeeze掉。
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x, y))
train_db = train_db.shuffle(1000).map(preprocess).batch(512)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.map(preprocess).batch(512)
# 我们来测试一下sample的形状。
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0])) # 值范围为[0,1]
def main():
# 输入:[b, 32, 32, 3]
model = resnet18()
model.build(input_shape=(None, 32, 32, 3))
model.summary()
optimizer = optimizers.Adam(lr=1e-3)
for epoch in range(500):
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 100]
logits = model(x)
# [b] => [b, 100]
y_onehot = tf.one_hot(y, depth=100)
# compute loss 结果维度[b]
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
# 梯度求解
grads = tape.gradient(loss, model.trainable_variables)
# 梯度更新
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 50 == 0:
print(epoch, step, 'loss:', float(loss))
# 做测试
total_num = 0
total_correct = 0
for x, y in test_db:
logits = model(x)
# 预测可能性。
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1) # 还记得吗pred类型为int64,需要转换一下。
pred = tf.cast(pred, dtype=tf.int32)
# 拿到预测值pred和真实值比较。
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct) # 转换为numpy数据
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()
- 运行结果显示:
(50000, 32, 32, 3) (50000,) (10000, 32, 32, 3) (10000,)
sample: (512, 32, 32, 3) (512,) tf.Tensor(-0.5, shape=(), dtype=float32) tf.Tensor(0.5, shape=(), dtype=float32)
Model: "res_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) multiple 2048
_________________________________________________________________
sequential_1 (Sequential) multiple 148736
_________________________________________________________________
sequential_2 (Sequential) multiple 526976
_________________________________________________________________
sequential_4 (Sequential) multiple 2102528
_________________________________________________________________
sequential_6 (Sequential) multiple 8399360
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 51300
=================================================================
Total params: 11,230,948
Trainable params: 11,223,140
Non-trainable params: 7,808
_________________________________________________________________
0 0 loss: 4.606736183166504
0 50 loss: 4.416693687438965
0 acc: 0.0604
1 0 loss: 4.007843971252441
1 50 loss: 3.776982307434082
1 acc: 0.1154
2 0 loss: 3.6374154090881348
2 50 loss: 3.4091014862060547
2 acc: 0.1768
3 0 loss: 3.335117816925049
3 50 loss: 3.0340826511383057
3 acc: 0.2271
4 0 loss: 3.0630342960357666
4 50 loss: 2.767192840576172
4 acc: 0.2788
5 0 loss: 2.801095485687256
5 50 loss: 2.5093324184417725
5 acc: 0.2863
6 0 loss: 2.652071237564087
6 50 loss: 2.3743672370910645
6 acc: 0.3103
7 0 loss: 2.3989481925964355
7 50 loss: 2.2451577186584473
7 acc: 0.317
8 0 loss: 2.3536462783813477
8 50 loss: 2.095005989074707
8 acc: 0.3192
9 0 loss: 2.145143985748291
9 50 loss: 1.9432967901229858
9 acc: 0.3216
10 0 loss: 2.055953025817871
10 50 loss: 1.8490103483200073
10 acc: 0.3235
11 0 loss: 1.845646858215332
11 50 loss: 1.5962769985198975
11 acc: 0.342
12 0 loss: 1.6497595310211182
12 50 loss: 1.5217297077178955
12 acc: 0.332
13 0 loss: 1.470338225364685
13 50 loss: 1.4912822246551514
13 acc: 0.3124
14 0 loss: 1.3743737936019897
14 50 loss: 1.2206969261169434
14 acc: 0.3074
15 0 loss: 1.3610031604766846
15 50 loss: 0.9420070052146912
15 acc: 0.3254
16 0 loss: 1.078605055809021
16 50 loss: 1.003871202468872
16 acc: 0.3174
17 0 loss: 1.0461890697479248
17 50 loss: 0.8586055040359497
17 acc: 0.3215
18 0 loss: 0.8623021841049194
18 50 loss: 0.6324957609176636
18 acc: 0.3169
19 0 loss: 0.9003666639328003
19 50 loss: 0.6545089483261108
19 acc: 0.3014
20 0 loss: 0.7230895757675171
20 50 loss: 0.41668233275413513
20 acc: 0.3162
21 0 loss: 0.4999226927757263
21 50 loss: 0.4038138687610626
21 acc: 0.3192
22 0 loss: 0.5035152435302734
22 50 loss: 0.36830756068229675
22 acc: 0.3115
23 0 loss: 0.5791099071502686
23 50 loss: 0.4304996728897095
23 acc: 0.3208
24 0 loss: 0.38201427459716797
24 50 loss: 0.23830433189868927
24 acc: 0.3356
25 0 loss: 0.21569305658340454
25 50 loss: 0.2295464128255844
25 acc: 0.3327
26 0 loss: 0.1231858879327774
26 50 loss: 0.20612354576587677
26 acc: 0.3323
27 0 loss: 0.1556326150894165
27 50 loss: 0.15461283922195435
27 acc: 0.3345
28 0 loss: 0.09280207753181458
28 50 loss: 0.05414274334907532
28 acc: 0.334
29 0 loss: 0.05890154093503952
29 50 loss: 0.08330313116312027
29 acc: 0.3374
30 0 loss: 0.06374034285545349
30 50 loss: 0.0645279586315155
30 acc: 0.3507
31 0 loss: 0.06771121919155121
31 50 loss: 0.03828241676092148
31 acc: 0.3435
32 0 loss: 0.05325049161911011
32 50 loss: 0.06898440420627594
32 acc: 0.3472
33 0 loss: 0.052143510431051254
33 50 loss: 0.07428835332393646
33 acc: 0.3515
34 0 loss: 0.05063686892390251
34 50 loss: 0.041026901453733444
34 acc: 0.3461
35 0 loss: 0.09660334885120392
35 50 loss: 0.10083606839179993
35 acc: 0.3467
36 0 loss: 0.0585043728351593
36 50 loss: 0.04725605621933937
36 acc: 0.3479
37 0 loss: 0.05428542569279671
37 50 loss: 0.0645551085472107
37 acc: 0.3429
38 0 loss: 0.04979332536458969
38 50 loss: 0.028766361996531487
38 acc: 0.3448
39 0 loss: 0.06059214845299721
39 50 loss: 0.03867074102163315
39 acc: 0.352
40 0 loss: 0.04751269519329071
40 50 loss: 0.05410218983888626
40 acc: 0.3406
41 0 loss: 0.07864020764827728
41 50 loss: 0.06852877885103226
41 acc: 0.3527
42 0 loss: 0.04342082887887955
42 50 loss: 0.0316157229244709
42 acc: 0.3542
43 0 loss: 0.08915773034095764
43 50 loss: 0.061082299798727036
43 acc: 0.3551
44 0 loss: 0.06201590225100517
44 50 loss: 0.07863974571228027
44 acc: 0.3527
45 0 loss: 0.06855347752571106
45 50 loss: 0.06905807554721832
45 acc: 0.3551
46 0 loss: 0.046435438096523285
46 50 loss: 0.06059195101261139
46 acc: 0.3474
47 0 loss: 0.03513294830918312
47 50 loss: 0.048817235976457596
47 acc: 0.3509
48 0 loss: 0.04353480041027069
48 50 loss: 0.03148560971021652
48 acc: 0.3473
49 0 loss: 0.05442756786942482
49 50 loss: 0.03871474415063858
49 acc: 0.3467
- 500个epoch测试结果如下:

注意: 对于ResNet-152的参数配置可以参考:ResNet-152
2.5、ResNet-34的最终演示结果
- 只需要简单修改resnet18_train.py文件,修改的如下:
from resnet import resnet34- 主函数第一句改为:
model = resnet34() - 把
epoch的大小修改为100 - 把
batchsize修改为256;根据自己的电脑配置进行修改。本人是在Titan Xp服务器上测试。
- 测试结果如下:
2.6、Out of memory情况解决办法

三、需要全套课程视频+PPT+代码资源可以私聊我!
- 方式1:CSDN私信我!
- 方式2:QQ邮箱:[email protected]或者直接加我QQ!