机器学习笔试、面试题 四
1、下面是三个散点图(A,B,C,从左到右)和和手绘的逻辑回归决策边界。
正则化项惩罚度最高的是?A A
B B
C C
D 都具有相同的正则化
正确答案是:A
解析: 因为正则化意味着更多的罚值和图A所示的较简单的决策界限。
2、下图显示了三个逻辑回归模型的AUC-ROC曲线。不同的颜色表示不同超参数值的曲线。
以下哪个AUC-ROC会给出最佳结果?
A 黄色
B 粉红色
C 黑色
D 都相同
正确答案是:A
解析: 最佳分类是曲线下区域面积最大者,而黄线在曲线下面积最大。
3、如果对相同的数据进行逻辑回归,将花费更少的时间,并给出比较相似的精度(也可能不一样),怎么办?
假设在庞大的数据集上使用Logistic回归模型。可能遇到一个问题,Logistic回归需要很长时间才能训练。A 降低学习率,减少迭代次数
B 降低学习率,增加迭代次数
C 提高学习率,增加迭代次数
D 增加学习率,减少迭代次数
正确答案是:D
解析: 如果在训练时减少迭代次数,就能花费更少的时间获得相同的精度,但需要增加学习率。
4、Logistic regression(逻辑回归)是一种监督式机器学习算法吗?A 是
B 否
正确答案是:A
解析:当然,Logistic regression是一种监督式学习算法,因为它使用真假标签进行测试。 测试模型时,监督式学习算法应具有输入变量(x)和目标变量(Y)。
5、Logistic Regression主要用于回归吗?A 是
B 否
正确答案是: B
解析:逻辑回归是一种分类算法,不要因为名称将其混淆。
6、是否能用神经网络算法设计逻辑回归算法?A 是
B 否
正确答案是:A
解析:是的,神经网络是一种通用逼近器,因此能够实现线性回归算法。
7、是否可以对三分问题应用逻辑回归算法?A 是
B 否
正确答案是:A
解析:当然可以对三分问题应用逻辑回归,只需在逻辑回归中使用One Vs all方法。
8、以下哪种方法能最佳地适应逻辑回归中的数据?A Least Square Error
B Maximum Likelihood
C Jaccard distance
D Both A and B
正确答案是: B
解析: Logistic Regression使用可能的最大似然估值来测试逻辑回归过程。
9、在逻辑回归输出与目标对比的情况下,以下评估指标中哪一项不适用?A AUC-ROC
B 准确度
C Logloss
D 均方误差
正确答案是:D
解析:因为Logistic Regression是一个分类算法,所以它的输出不能是实时值,所以均方误差不能用于评估它。
10、如下逻辑回归图显示了3种不同学习速率值的代价函数和迭代次数之间的关系(不同的颜色在不同的学习速率下显示不同的曲线)。
为了参考而保存图表后,忘记其中不同学习速率的值。现在需要曲线的倾斜率值之间的关系。
以下哪一个是正确的?
注:
1.蓝色的学习率是L1
2.红色的学习率是L2
3.绿色学习率为lL3A L1> L2> L3
B L1 = L2 = L3
C L1
D 都不是
正确答案是:C
解析: 如果学习速率低下,代价函数将缓慢下降,学习速度过高,则其代价函数会迅速下降。
1、分析逻辑回归表现的一个良好的方法是AIC,它与线性回归中的R平方相似。有关AIC,以下哪项是正确的?A 具有最小AIC值的模型更好
B 具有最大AIC值的模型更好
C 视情况而定
D 以上都不是
正确答案是:A,您的选择是:A
解析:AIC信息准则即Akaike information criterion,是衡量统计模型拟合优良性的一种标准,由于它为日本统计学家赤池弘次创立和发展的,因此又称赤池信息量准则。
考虑到AIC=2k-2In(L) ,所以一般而言,当模型复杂度提高(k增大)时,似然函数L也会增大,从而使AIC变小,但是k过大时,似然函数增速减缓,导致AIC增大,模型过于复杂容易造成过拟合现象。目标是选取AIC最小的模型,AIC不仅要提高模型拟合度(极大似然),而且引入了惩罚项,使模型参数尽可能少,有助于降低过拟合的可能性。
综上,我们一般选择逻辑回归中最少的AIC作为最佳模型。有关更多信息,请参阅此来源:www4.ncsu.edu/~shu3/Presentation/AIC.pdf
2、在训练逻辑回归之前需要对特征进行标准化。A 是
B 否
正确答案是: B
解析:逻辑回归不需要标准化。功能标准化的主要目标是帮助优化技术组合。
3、选择Logistic回归中的One-Vs-All方法中的哪个选项是真实的。A 我们需要在n类分类问题中适合n个模型
B 我们需要适合n-1个模型来分类为n个类
C 我们需要只适合1个模型来分类为n个类
D 这些都没有
正确答案是:A
解析:如果存在n个类,那么n个单独的逻辑回归必须与之相适应,其中每个类的概率由剩余类的概率之和确定。
4、使用以下哪种算法进行变量选择?A LASSO
B Ridge
C 两者
D 都不是
正确答案是:A
解析:使用Lasso的情况下,我们采用绝对罚函数,在增加Lasso中罚值后,变量的一些系数可能变为零。
5、以下是两种不同的对数模型,分别为β0和β1。
对于两种对数模型(绿色,黑色)的β0和β1值,下列哪一项是正确的?
注: Y =β0+β1* X。其中β0是截距,β1是系数。A 绿色的β1大于黑色
B 绿色的β1小于黑色
C 两种颜色的β1相同
D 不能说
正确答案是: B
解析:β0和β1:β0= 0,β1= 1为X1颜色(黑色),β0= 0,β1= -1为X4颜色(绿色)
6、逻辑回归的以下模型:P(y = 1 | x,w)= g(w0 + w1x)其中g(z)是逻辑函数。在上述等式中,通过改变参数w可以得到的P(y = 1 | x; w)被视为x的函数。A (0,inf)
B (-inf,0)
C (0,1)
D (-inf,inf)
正确答案是:C
解析:对于从-∞到+∞的实数范围内的x的值。逻辑函数将给出(0,1)的输出。
7、下面是三个散点图(A,B,C,从左到右)和和手绘的逻辑回归决策边界。
上图中哪一个显示了决策边界过度拟合训练数据?A A
B B
C C
D 这些都没有
正确答案是:C
解析:由于在图3中,决策边界不平滑,表明其过度拟合数据
8、逻辑回归的以下模型:P(y = 1 | x,w)= g(w0 + w1x)其中g(z)是逻辑函数。
在上述等式中,通过改变参数w可以得到的P(y = 1 | x; w)被视为x的函数。
在上面的问题中,你认为哪个函数会产生(0,1)之间的p?A 逻辑函数
B 对数似然函数
C 两者的复合函数
D 都不会
正确答案是:A
解析:对于从-∞到+∞的实数范围内的x的值。逻辑函数将给出(0,1)的输出。
9、下面是三个散点图(A,B,C,从左到右)和和手绘的逻辑回归决策边界。
根据可视化后的结果,能得出什么结论?
1.与第二和第三图相比,第一幅图中的训练误差最大。
2.该回归问题的最佳模型是最后(第三个)图,因为它具有最小的训练误差(零)。
3.第二个模型比第一个和第三个更强,它在不可见数据中表现最好。
4.与第一种和第二种相比,第三种模型过度拟合了。
5.所有的模型执行起来都一样,因为没有看到测试数据。A 1和3
B 1和3
C 1,3和4
D 5
10、下面是三个散点图(A,B,C,从左到右)和和手绘的逻辑回归决策边界。
假设上述决策边界是针对不同的正则化(regularization)值生成的。那么其中哪一个显示最大正则化?A A
B B
C C
D 都具有相同的正则化
正确答案是:A
解析: 因为正则化意味着更多的罚值和图A所示的较简单的决策界限。
1、下图显示了三个逻辑回归模型的AUC-ROC曲线。不同的颜色表示不同超参数值的曲线。以下哪个AUC-ROC会给出最佳结果?
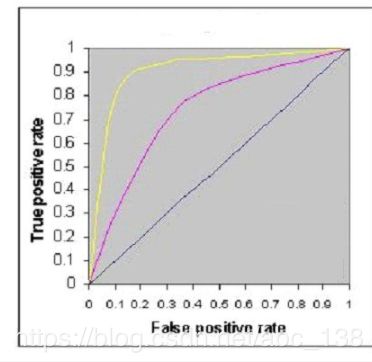
A 黄色
B 粉红色
C 黑色
D 都相同
正确答案是:A
解析:最佳分类是曲线下区域面积最大者,而黄线在曲线下面积最大
2、假设你在测试逻辑回归分类器,设函数H为
下图中的哪一个代表上述分类器给出的决策边界?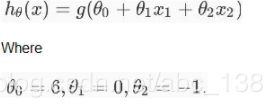
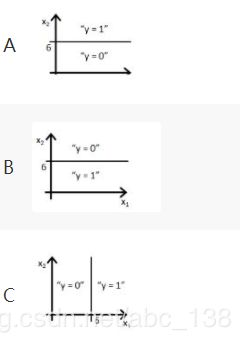
解析:选项B正确。虽然我们的式子由选项A和选项B所示的y = g(6- x2)表示,但是选项B才是正确的答案,因为当将x2 = 6的值放在等式中时,要使y = g(0)就意味着y = 0.5将在线上,如果你将x2的值增加到大于6,你会得到负值,所以输出将是区域y = 0。
3、所谓几率,是指发生概率和不发生概率的比值。所以,抛掷一枚正常硬币,正面朝上的几率(odds)为多少?A 0.5
B 1
C 都不是
正确答案是: B
解析:几率(odds)是事件发生不发生概率的比率,正面朝上概率为1/2和反面朝上的概率都为1/2,所以几率为1。
4、Logit函数(给定为l(x))是几率函数的对数。域x = [0,1]中logit函数的范围是多少?A ( - ∞,∞)
B (0,1)
C (0,∞)
D ( - ∞,0)
正确答案是:A
解析:为了与目标相适应,几率函数具有将值从0到1的概率函数变换成值在0和∞之间的等效函数的优点。当我们采用几率函数的自然对数时,我们便能范围是-∞到∞的值。
5、如果对相同的数据进行逻辑回归,将花费更少的时间,并给出比较相似的精度(也可能不一样),怎么办?
(假设在庞大的数据集上使用Logistic回归模型。可能遇到一个问题,Logistic回归需要很长时间才能训练。)A 降低学习率,减少迭代次数
B 降低学习率,增加迭代次数
C 提高学习率,增加迭代次数
D 增加学习率,减少迭代次数
正确答案是:D
解析:如果在训练时减少迭代次数,就能花费更少的时间获得相同的精度,但需要增加学习率。
6、以下哪些选项为真?A 线性回归误差值必须正态分布,但是在Logistic回归的情况下,情况并非如此
B 逻辑回归误差值必须正态分布,但是在线性回归的情况下,情况并非如此
C 线性回归和逻辑回归误差值都必须正态分布
D 线性回归和逻辑回归误差值都不能正态分布
正确答案是:A
7、以下哪个图像显示y = 1的代价函数?
以下是两类分类问题的逻辑回归(Y轴损失函数和x轴对数概率)的损失函数。注:Y是目标类
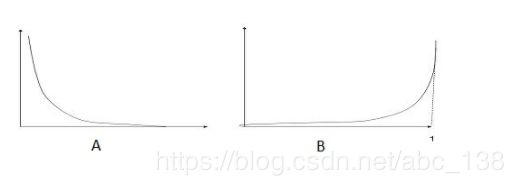
A A
B B
C 两者
D 这些都没有
正确答案是:A
解析:A正确,因为损失函数随着对数概率的增加而减小
8、对于任意值“x”,考虑到
Logistic(x):是任意值“x”的逻辑(Logistic)函数
Logit(x):是任意值“x”的logit函数
Logit_inv(x):是任意值“x”的逆逻辑函数
以下哪一项是正确的?A Logistic(x)= Logit(x)
B Logistic(x)= Logit_inv(x)
C Logit_inv(x)= Logit(x)
D 都不是
正确答案是: B
9、假设,下图是逻辑回归的代价函数,现在,图中有多少个局部最小值?
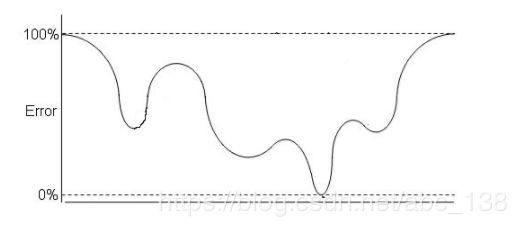
A 1
B 2
C 3
D 4
正确答案是:D
解析:图中总共有四个凹的地方,故有四个局部最小值
10、使用 high(infinite) regularisation时偏差会如何变化?,有散点图“a”和“b”两类(蓝色为正,红色为负)。在散点图“a”中,使用了逻辑回归(黑线是决策边界)对所有数据点进行了正确分类。
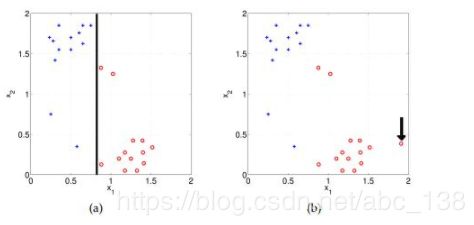
A偏差很大
B 偏差很小
C 不确定
D 都不是
正确答案是:A
解析:模型变得过于简单,所以偏差会很大。