Spark Application执行流程
对书籍以及博客中的Spark知识简单的梳理、记录。
(一) 什么是Spark Application?
application(应用)其实就是spark-submit提交的spark应用程序。一个完整的Spark应用程序包含如下几个基本步骤:
- 获取输入数据(通过序列获取,读取HDFS,读取数据库,读去S3等!)
- 处理数据(具体的代码逻辑)
- 输出结果(导入到HDFS,Hbase,MySQL等存储)

从spark官网的这幅图可以简单看出,提交一个spark应用程序会创建一个driver端来管理这个spark应用程序。和YARN的ApplicationMaster相似,完成任务的调度以及与executor和ClusterManager协调。有两种模式,client以及cluster模式。client模式将driver运行在spark-submit执行的机器中,cluster则是在spark集群中随机挑选一台执行。如果spark调度器集成了YARN,那么这两种模式在YARN中也有类似的体现!
(二) Spark 中的Job如何划分?
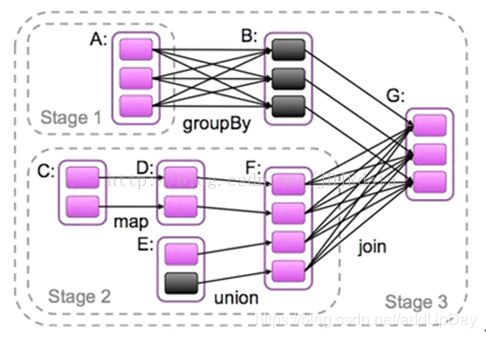
如图:

我们可以看出,Driver在管理一个Spark Application的时候。会根据代码的流程初始化一个SparkContext对象,每个SparkApplication都会有一个SparkContext对象,它里面封装了创建RDD、加载集群配置(SparkConf)以及创建任务划分的三大核心组件。
- DAGScheduler:一个面向Job的划分stage的高层调度器。
- TaskScheduler:接口,是低层调度器,根据具体的ClusterManager的不同会有不同的实现。Standalone模式下具体实现的是TaskSchedulerlmpl。
- SchedulerBackend:接口,根据具体的ClusterManger的不同会有不同的实现,Standalone模式下具体的实现是SparkDeloySchedulerBackend。
在spark代码中,当运行到Action算子时,SparkContext就会将其作为一个Job去划分处理,具体的DAG划分以及Task运行就是这三大核心组件实现的。
(三) Spark Job的DAG是如何划分和执行?
1. 什么是DAG(有向无环图)?
DAG(Directed Acyclic Graph)有向无环图。对于这个概念只有数学专业的运筹学和计算机专业的数据结构的图中讲到了DAG,所以我先普及一下理论。图是数据结构中最复杂的,泛指无组织的结构体由关联关系形成图。DAG(有向无环图)是拓扑图的一种,比较有规律,适合做血缘关系描述。看起来很晕乎是不是?简单理解为记录RDD依赖关系的有方向没有回路的线路图。
2.Spark DAG是做什么的?
RDD算子构建了RDD之间的关系,整个计算过程形成了一个由RDD和关系构成的DAG。
简单理解为点和线构成图。Spark中的每一个Job执行时都会有DAG的划分过程,而实现这一步的便是DAGScheduler,在到执行这个Job,就是将这个Job的DAG中的stage交给TaskScheduler分发至spark集群中执行。
3.关于Job的DAG划分
前面我们有提到当spark代码运行到行动算子时就会将其划分为一个Job去执行处理。当RDD触发一个Action操作(如:colllect)后,导致SparkContext.runJob的执行。而在SparkContext的run方法中会调用DAGScheduler的run方法最终调用了DAGScheduler的submit方法:
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
//给eventProcessLoop发送JobSubmitted消息
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
DAGScheduler的submit方法中,向eventProcessLoop对象发送了JobSubmitted消息。eventProcessLoop是DAGSchedulerEventProcessLoop类的实例对象。DAGSchedulerEventProcessLoop会接收传递来的消息(例如:JobSubmitted)使用其doOnReceive方法进行处理:
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
//Job提交
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
//省略部分源码模式匹配
.......
}
可以把DAGSchedulerEventProcessLoop理解成DAGScheduler的对外的功能接口。它对外隐藏了自己内部实现的细节。无论是内部还是外部消息,DAGScheduler可以共用同一消息处理代码,逻辑清晰,处理方式统一。
接下来分析DAGScheduler的Stage划分,handleJobSubmitted方法首先创建ResultStage(就是action算子前的最后一个RDD(finalRDD图中:RDD G)创建一个finalStage(finalRDD图中:Stage3),并创建一个待提交的ActiveJob。开始对这个Job逆向递归遍历划分DAG。)
创建finalStage的源码:
try {
//创建新stage可能出现异常,比如job运行依赖hdfs文文件被删除
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
首先由finalRDD获取它的父RDD依赖,判断依赖类型,如果是窄依赖,则将父RDD压入栈中,如果是宽依赖(进行了shuffle操作),则作为父Stage。
源码分析:
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage] //存储需要返回的父Stage
val visited = new HashSet[RDD[_]] //存储访问过的RDD
//自己建立栈,以免函数的递归调用导致溢出
val waitingForVisit = new Stack[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
for (dep <- rdd.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
val mapStage = getShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
missing += mapStage //遇到宽依赖,加入父stage
}
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd) //窄依赖入栈,
}
}
}
}
}
//回溯的起始RDD入栈
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
missing.toList
}
然后,再由submitstage(也是一个逆向的递归调用)方法将划分好的DAG stage整个打包好发给TaskScheduler,并有封装成taskset,分发给集群的worker计算出结果。
源码分析:
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
//如果没有父stage,则提交当前stage
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
//如果有父stage,则递归提交父stage
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
提交的过程很简单,首先当前stage获取父stage,如果父stage为空,则当前Stage为起始stage,交给submitMissingTasks处理,如果当前stage不为空,则递归调用submitStage进行提交。
到这里,DAGScheduler中的DAG划分与提交就讲完了,下次解析这些stage是如何封装成TaskSet交给TaskScheduler以及TaskSchedule的调度过程。
(四) 如何理解Spark DAG中的Stage划分?
Stage概念是spark中独有的。一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。至于stage是怎么切分的,首选得知道spark论文中提到的narrow dependency(窄依赖)和wide dependency( 宽依赖)的概念。
其实很好区分,看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。宽依赖和窄依赖的边界就是stage的划分点。从spark的论文中的两张截图,可以清楚的理解宽窄依赖以及stage的划分。
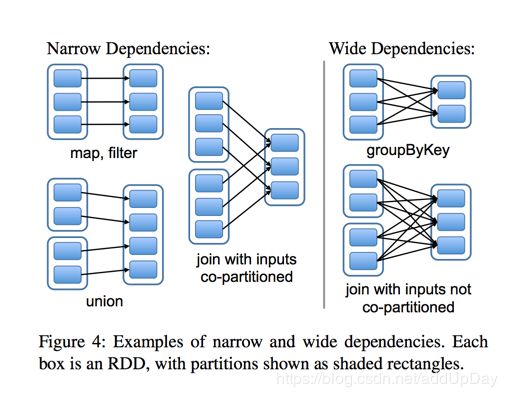

至于为什么这么划分,主要是宽窄依赖在容错恢复以及处理性能上的差异,宽依赖需要进行shuffer,在spark的底层源码中,除开Action算子会创建第一个默认Stage之外(保证一个DAG至少有一个stage划分),在逆向创建stage就是调用的getShuffleMapStage方法导致的。
总结一下:各个Stage的划分以Shuffer为分界线!
(五) TaskScheduler的作用?
相对于DAGScheduler而言,TaskScheduler是一个低级的调度接口。允许实现不同的Task调度器(除了自带的,还有YARN和Mesos),每个TaskScheduler只服务于一个SparkContext(它创建的TaskScheduler)调度。TaskScheduler会从DAGScheduler中获取每个stage的一组Task(单个分区数据及上的最小处理流程单元。),即TaskSet(由一组关联的,但互相之间没有Shuffle依赖关系的任务所组成的任务集。),并负责将他们发送至集群运行,如果出错会重试并将消息返回给DAGScheduler。
整个DAG划分以及提交的简单图形:

(六) 小结
本文主要介绍在单个任务内Spark的调度管理,Spark调度相关概念如下:
Task(任务):单个分区数据及上的最小处理流程单元。
TaskSet(任务集):由一组关联的,但互相之间没有Shuffle依赖关系的任务所组成的任务集。
Stage(调度阶段):一个任务集对应的调度阶段。
Job(作业):有一个RDD Action生成的一个或多个调度阶段所组成的一次计算作业。
Application(应用程序):Spark应用程序,由一个或多个作业组成。
逻辑关系图:
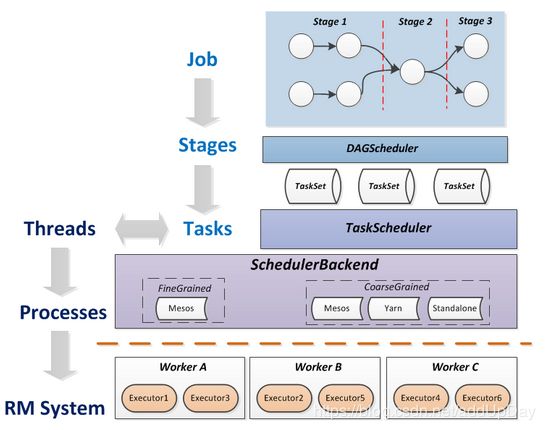
关于stage的执行提交顺序:
当执行其中一个中间的stage时,DAGScheduler(根据TaskScheduler返回的信息)会检查对应调度阶段的所有任务是否都完成了。如果完成了,则DAGScheduler将重新扫描一次等待列表中所有的Stage,检查它们是否还有依赖的Stage没有完成。如果所有依赖的Stage都已执行完毕,则提交该Stage。