Hbase中Rowkey设计对入库效率的影响
Rowkey是Hbase每一行记录的唯一标识,在设计Rowkey时,不仅要考虑业务需求,也需要考虑Hbase本身的特性。如果Rowkey设计不合理,不仅不能充分发挥Hbase集群并行处理的优势,还会造成数据倾斜、Region热点等影响读写效率的问题。
Rowkey设计原则
Rowkey设计一般遵循以下三个原则:
1、 唯一性原则
Rowkey在设计时必须保持唯一性,如果两条记录Rowkey相同,Hbase会存储为同一个Rowkey的不同版本。
2、 长度原则
Hbase数据的持久化文件Hfile是按照KeyValue存储的,如果Rowkey过长,在数据量大的时候,会占用很大的存储,极大的影响Hfile的存储效率。
3、 散列原则
建议Rowkey的高位作为散列字段,低位作为时间字段,这样Rowkey会比较均匀的分布到各个Region上,以实现负载均衡的几率。如果没有散列字段,大部分数据都会集中在某些Region上,而某些Region数据量小甚至没有分配到数据,造成热点问题,降低Hbase读写效率。
建表预分区原则
Hbase Region在大小达到一定阈值后(目前是10G),就会Splite(分裂)两个Region,而当一个Region的Hfile个数达到一定的阈值(目前为4个),就会对这些Hfile进行Compact(合并)。Splite和Compact都会比较消耗IO,所以要尽量减少Region分裂和合并的次数。这就需要对数据的大小进行评估,建表时预先分区。如果不预分区,默认就只有一个分区,在导入数据时就只会起一个Reduce任务处理,而且Region达到阈值大小后会不断分裂,非常影响入库效率。所以需要合理估算分区数,过小会导致Region不断分裂,过大又会增加MasterServer管理的压力。计算分区数原则如下:
N = TotalSize/hbase.hregion.max.filesize(目前是10G)
例如目前http接口信令数据一天的大小约为6.5T,那么分区数为:6.5*1024/10=665.6,因为建表时一般会指定压缩方式,入库后的数据会变小,故分区数设置为600就足够了。DNS接口每天大小约2T,分区数为:2*1024/10=204.8,分区数设置为了200就可以了。
建议Hbase按以下方式来建表:
create 'ns_boco:test ', {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy'}},{NAME => 'info', COMPRESSION => 'SNAPPY' },{NUMREGIONS => 600, SPLITALGO => 'HexStringSplit'}该建表语句指定了表ns_boco:test Region split策略为按固定大小分裂(ConstantSizeRegionSplitPolicy),压缩方式采用SNAPPY,表预分600(需按业务实际情况估算)个Region,列族为info
下面测试Rowkey在有散列字段和无散列字段对HDFS文件入库Hbase效率的影响。
1、 使用bulkload方式把HDFS的文件导入Hbase,大小均为340.7G。建表均采用预分40个Region。

create 'ns_boco:import_test1', {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy'}},{NAME => 'info', COMPRESSION => 'SNAPPY' },{NUMREGIONS => 40, SPLITALGO => 'HexStringSplit'}
create 'ns_boco:import_test2', {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy'}},{NAME => 'info', COMPRESSION => 'SNAPPY' },{NUMREGIONS => 40, SPLITALGO => 'HexStringSplit'}2、 import_test2 Rowkey设计为MD5(MSISDN)取前4位+MSISDN+时间,高位使用MD5得到散列字段。如41c11877721065620170801142654645。
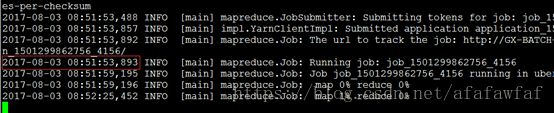

入库时间:09:23:35–08:51:53≈31分钟。
可以发现入库后各Region的数据量分布比较均衡,每个Region约分配到了7.5G的数据。
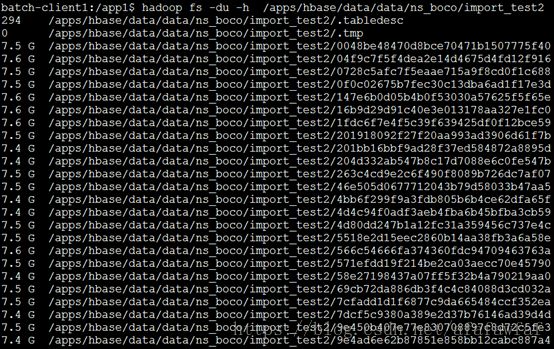
3、 import_test1 RowkeyRowkey设计为MSISDN(8-11位)+MSISDN+时间,高位直接取手机号码8-11位,没做散列处理,如06561877721065620170801142654645。


入库时间:10:20:12-09:25:54≈54分钟。
入库后各Region的数据量分布不均衡,40个Region中有19个(大小为63字节的目录)没有分配到数据,有些Region分配到的数据又比较大,大于20G。
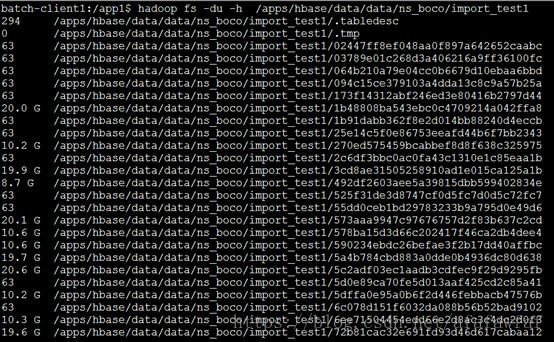
由此可见,Rowkey设计时对高位进行散列处理,不仅能提高读写效率,还能让数据均衡的分布到各个Regions上,实现负载均衡