Java网络爬虫之自动爬取必应每日一图
经过了上一次的了解,我们已经轻松地爬取网络资源到本地。微软必应搜索首页每天会更新一张背景图,这次我们来实现每天定时爬取这张背景图到本地。
一、Jsoup的简单使用
Jsoup是一款Java的HTML解析器,主要用来对HTML解析。就像我们熟知的dom4j一样,都是文档解析器,只不过后者主要用来解析XML文件。
配置好Jsoup的jar包,我们来看一下它简单的使用。
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupTest {
public static void main(String[] args) throws IOException {
//发送get请求获取必应首页文档对象
Document doc=Jsoup.connect("https://cn.bing.com").get();
//使用选择器选取类名为a11yhide的h1元素
Elements elements=doc.select("h1.a11yhide");
System.out.println("类名为a11yhide的h1标签的数量:"+elements.size());
//获取第一个元素
Element element=elements.get(0);
String text=element.text();
System.out.println(text);
}
}
Jsoup提供select方法来帮助我们筛选想要的节点,该方法返回Elements对象,Elements类继承List,本质是一种线性数据结构,所以该对象具有List的相关方法。
Document类继承Elenent类,Element类继承Node类。
输出结果:

浏览器打开必应首页按F12查看DOM结构:

我们可以使用Jsoup获取必应首页背景图的URL:
首先查看图片URL所在节点:
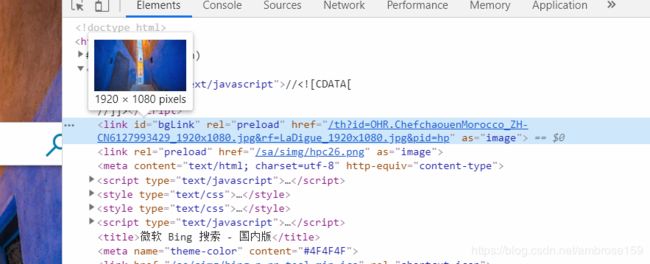
背景图的URL在标签内的标签中, id为“bgLink”。
代码:
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class Bing {
public static void main(String[] args) throws IOException {
Document doc=Jsoup.connect("https://cn.bing.com").get();
Element imageLink=doc.getElementById("bgLink");
//获取绝对路径
String imageURL=imageLink.absUrl("href");
System.out.println(imageURL);
}
}
结果:
![]()
将结果输入浏览器地址栏即可访问,也可通过IO流下载到本地。
二、每天定时获取必应每日一图
获取当天保存的文件名
因为要自动获取,首先要保证每天保存到本地的文件不能重名,下面是获取当天保存的文件名的方法,以当天日期为文件名。
/**
* 获取自定义的时间戳
* @author luckyriver
*
* @return 当天日期的字符串形式.如:当天为6月20日,则返回 “06-28”
*/
public static String getSaveName() {
SimpleDateFormat formater = new SimpleDateFormat("MM-dd");
formater.applyPattern("MM-dd");
String saveName=formater.format(new Date());
return saveName;
}
当然你也可以用Java提供的UUID等作为文件名,保证文件名称的唯一性是最终目的,要不文件会被覆盖。
根据URL下载资源到本地:
/**
* 拷贝URL资源到本地
*
* @author luckyriver
*
* @param url URL的字符串形式
* @param file 将要保存的文件
*/
public static void URLToFile(String url,File file){
URL imageURL=null;
InputStream is=null;
try {
//以必应首页图片为例
imageURL = new URL(url);
is=imageURL.openConnection().getInputStream();//得到输入流
} catch (Exception e1) {
e1.printStackTrace();
}
//建立缓冲输入流,包装得到的普通输入流
try(BufferedInputStream bif=new BufferedInputStream(is);
//建立缓冲输出流,包装文件输出流
BufferedOutputStream bof=
new BufferedOutputStream(new FileOutputStream(file)))
{//读写流程
int len;
byte[] buffer=new byte[1024*10];
while (-1!=(len=bif.read(buffer))) {
bof.write(buffer, 0, len);
}
bof.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
我们知道文件后缀为.jpg,但是那是我们能看见罢了,我们要尽量提高代码复用性。
获取文件后缀:
/**
* 根据URL获取资源文件后缀名
* @author luckyriver
* @param url 目标URL
* @return 后缀名 如".jpg", ".html"
*/
public static String getSuffix(URL url){
String suffix="";
try {
String type=url.openConnection().getContentType().split(";")[0];
suffix="."+type.split("/")[1];
} catch (IOException e) {
e.printStackTrace();
}
return suffix;
}
使用Jsoup获取必应首页背景图的URL:
/**
* 获取必应每日一图的URL
* @author luckyriver
* @return URL的字符串形式,失败则返回""
*/
public static String getBingImageURL() {
Document doc;
String imageURL="";
try {
doc = Jsoup.connect("https://cn.bing.com").get();
Element imageLink=doc.getElementById("bgLink");
imageURL=imageLink.absUrl("href");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return imageURL;
}
最后的测试:
public static void main(String[] args) throws MalformedURLException {
URL imageURL=new URL(getBingImageURL());
String FileName=getSaveName()+getSuffix(imageURL);//"07-08.jpeg"
File parent=new File("D:\\desktop\\images\\");//保存路径
if (!parent.exists()) {
parent.mkdirs();
}
URLToFile(imageURL, new File(parent,FileName));//获取文件
}
打开对应路径查看:
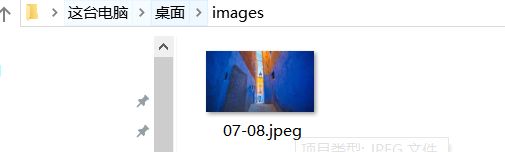
完整代码如下:
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class Bing {
/**
* 获取自定义的时间戳
* @author luckyriver
*
* @return 当天日期的字符串形式.如:当天为6月20日,则返回 “06-28”
*/
public static String getSaveName() {
SimpleDateFormat formater = new SimpleDateFormat("MM-dd");
formater.applyPattern("MM-dd");
String saveName=formater.format(new Date());
return saveName;
}
/**
* 拷贝URL资源到本地
* @param url URL的字符串形式
* @param file 将要保存的文件
*/
public static void URLToFile(URL url,File file){
InputStream is=null;
try {
//以必应首页图片为例
is=url.openConnection().getInputStream();//得到输入流
} catch (Exception e1) {
e1.printStackTrace();
}
//建立缓冲输入流,包装得到的普通输入流
try(BufferedInputStream bif=new BufferedInputStream(is);
//建立缓冲输出流,包装文件输出流
BufferedOutputStream bof=
new BufferedOutputStream(new FileOutputStream(file)))
{//读写流程
int len;
byte[] buffer=new byte[1024*10];
while (-1!=(len=bif.read(buffer))) {
bof.write(buffer, 0, len);
}
bof.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 根据URL获取资源文件后缀名
* @author luckyriver
* @param url 目标URL
* @return 后缀名,失败则返回""。 如 ".jpg", ".html"
*/
public static String getSuffix(URL url){
String suffix="";
try {
String type=url.openConnection().getContentType().split(";")[0];
suffix="."+type.split("/")[1];
} catch (IOException e) {
e.printStackTrace();
}
return suffix;
}
/**
* 获取必应每日一图的URL
* @author luckyriver
* @return URL的字符串形式,失败则返回""
*/
public static String getBingImageURL() {
Document doc;
String imageURL="";
try {
doc = Jsoup.connect("https://cn.bing.com").get();
Element imageLink=doc.getElementById("bgLink");
imageURL=imageLink.absUrl("href");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return imageURL;
}
/**
*测试
*
*/
public static void main(String[] args) throws MalformedURLException {
URL imageURL=new URL(getBingImageURL());
String FileName=getSaveName()+getSuffix(imageURL);//"07-08.jpeg"
File parent=new File("D:\\desktop\\images\\");//保存路径
if (!parent.exists()) {
parent.mkdirs();
}
URLToFile(imageURL, new File(parent,FileName));//获取文件
}
}
实现每天定时爬取
上面的代码我们每天都要手动执行,考虑每天定时自动执行爬取:
一开始想到了Java提供的Timer类,但是不能因为每天爬一张图就让JVM一直跑着啊!
回想刚开始学java,记事本里写完的代码要在命令行窗口编译运行,又因为我操作系统为Windows,自然想到写个简单的bat文件,然后设置系统定时任务。
但是,我们的类里面用到了第三方jar包,在命令行窗口编译会报错:
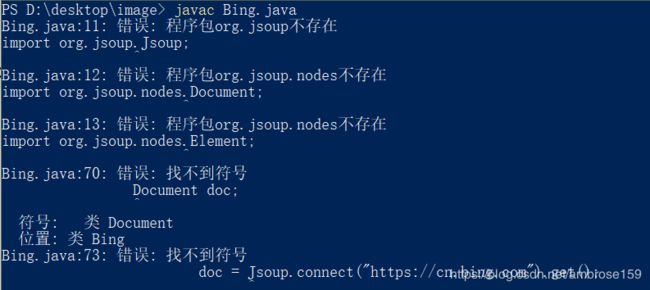
解决方法:
1.下载并解压使用的Jsoup包
![]()
2.把我们的Bing.java文件放在解压后的路径下:

删除之前的文件夹,然后在该目录下打开命令行窗口(shift+鼠标右键),编译并运行:

查看结果:

编写简单bat文件执行.class文件
@echo off
set CLASSPATH=%CLASSPATH%
set PATH=%PATH%
set JAVA_HOME=%JAVA_HOME%
d:
cd D:\desktop\reptile\jsoup-1.12.1\
start java Bing
exit
@pause
整个过程就是设置java环境变量,然后执行cmd命令,进入.class文件所在文件夹,执行java Bing 语句,保存为.bat文件。
这时,我们只要点击这个bat文件,就会爬取图片。

设置Windows定时任务
以Win10为例,设置系统定时任务,每天定时执行我们写好的bat文件
进入计算机管理:

点击任务计划程序,创建任务:
设置名称,触发器,操作,条件等信息:

新建操作选择我们写好的bat文件

到时电脑只要开机联网,就可以定时自动爬取,附近二十天爬取的背景图:
