大型机学习之具体-z/OS中的作业管理系统,SDSF工具及JCL(二)
接上篇:
7.JCL 的位置参数与关键字参数最多只能由两级子参数。也就是说用于括起子参数列表的括号最多只能有两层。
四、JCL语句的位置
在下面各节中我们将详细讨论各语句的书写方法,为了便于编写 JCL,下面按照 JCL语句的放置顺序来说明它们的位置:
1.JOB 语句。
2.JOBLIB 语句。
3.JOBCAT 及 SYSCHK 语句。
4.任何流内过程。
5.第一个 EXEC 语句。
6.任何的 STEPCAT、STEPLIB,或一般的属于这一步的 DD语句。
7.任何更多的 EXEC 语句及与他们相关联的 DD语句。
8.任何空语句。
五、JCL语法实例
作业语句 //EXPJOB JOB ,’USERNAME’,MSGLEVEL=(1,1), EXAMPLE
作业语句续行 // MSGCLASS=Q,CLASS=A
//**********************
注释语句 //* IT IS A EXAMPLE *
//**********************
执行语句 //STEP1 EXEC PGM=IEFBR14
DD语句 //DD1 DD DSN=MJSN.TEAM01.ONE,DISP=(,CATLG),
DD语句续行 // SPACE=(TRK,(5,2)), UNIT=SYSDA
DD语句 // DD1 DD DSN=MJSN.TEAM01.TWO,DISP=(,KEEP),
DD语句续行 // SPACE=(TRK,(1,1)), UNIT=SYSDA
值得注意的是:在例中,采取了两种注释说明的方式,一种为作业句中的“EXAMLE”,这是在说明区中说明的方式;另一种则是注释语句的方式。注释语句以第 1~3列的“//*”开始,可以将它放在 JOB 语句后的任何 JCL 语句的前面或后面来说明 JCL。
JOB语句:
JOB 语句标志一个作业的开始、分配作业名并设置相关的位置参数及关键字参数,每个
作业的第一个语句必须是 JOB 语句。
JOB 语句的格式如下:
//作业名 JOB 位置参数[,关键字参数][,关键字参数]。。。[注释说明]
一、 作业名
作业名是用户给作业指定的名字。为使操作系统识别作业,必须选择确定的作业名字,
由于系统不能同时运行具有相同名字得到作业,因此只能给作业一个唯一确定的名字。一般
来说,建议用户采用“ USERID+数字或字符”的作业名,例如用户标识为 JACK,则作业名可用 JACKA。
二、位置参数
作业语句中的位置参数有两个:
1.记账信息(accounting information):
记账信息位于操作符“JOB”后,它用于提供用户使用系统的合法性、机时及纸张的收
费管理等。其格式为:
([account-number][,accounting-information]…)
account-number:用户账号;
accounting-information:附加的记账信息,如房间号、部门名等等。
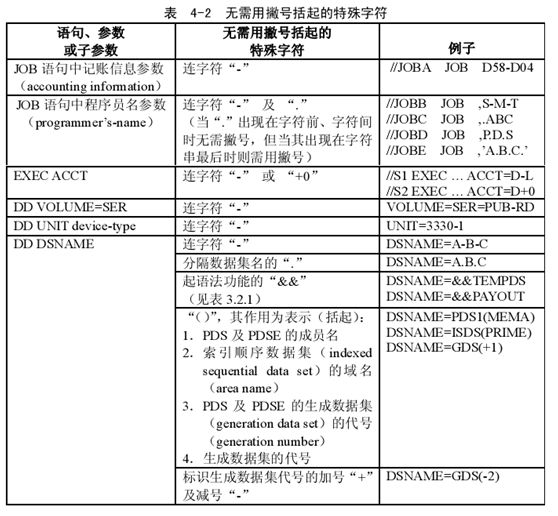
记账信息参数及其子参数最多不可超过 143 个字符(包括分隔子参数的逗号,但不包括括起子参数列表的括号)。例:
//EXAMPLE1 JOB (D548-8686,’12/8/98’,PGMBIN)
//EXAMPLE2 JOB D548-8686
2.程序员名(programmer’s name)
程序员名用于标识作业的所有者(owner)信息,包括特殊字符在内,其长度不得超过
20 个字符。例:
//EXAMPLE1 JOB 2000,J.A.C.K
//EXAMPLE2 JOB 2001,JACK
//EXAMPLE3 JOB 2003,’O’’SUN’
下面是几个位置参数不同的书写格式的例子:
带有全部位置参数的作业语句:
//JOBA JOB (20008,60),A.B.C,CLASS=S,…
缺省记账信息的作业语句:
//JOBB JOB ,USER-NAME,CLASS=A,…
不带位置参数的作业语句:
//JOBC JOB CLASS=Q,…
三: 关键字参数
JOB 语句中的关键字参数有如下几个:
1. ADDRSPC
指明作业所需之存储类型,它有两个子参数:VIRT 及 REAL。VIRT 表示作业请求虚拟
页式存贮,而 REAL 表示作业请求实存存储空间。缺省值为 VIRT。其格式为:
ADDRSPC={VIRT}
{REAL}
例:
//PEH JOB ,BAKER,ADDRSPC=VIRT
//DEB JOB ,ERIC,ADDRSPC=REAL,REGION=100K
2. BYTES
指明打印作业的系统输出数据集的最大千字节数,同时该参数还指出当超过所给出的最
大字节数时,系统对作业的处理方式。这些方式包括:取消作业(转储(dump)或不转储)
或继续作业并向操作员发出超过最大字节数的警告信息。其格式为:
BYTE={nnnnn}
{([nnnnnn][,CANCEL])}
{([nnnnnn][,DUMP])}
{([nnnnnn][,WARNING])}
nnnnnn:指明打印输出的最大千字节数,例:nnnnnn 取值500,则表示500,000 字节。
nnnnnn 取值范围为:0 ~ 999999。
CANCEL:当作业输出字节数超过 nnnnnn 时,系统将不转储而直接取消该作业。
DUMP:当作业输出字节数超过 nnnnnn 时,系统在取消该作业前将发出转储请求。
WARNING:当作业输出字节数超过 nnnnnn 时,作业继续执行,系统将按照安装时规
定的时间间隔不断向操作员发送警告信息。
当 BYTE 参数或其子参数省略不写时,系统将采用安装时定义的默认值。
例:
//JOB1 JOB (123456),’R F B’,BYTES=(5000,CANCEL)
// JOB1 JOB (123456),’R F B’,BYTES=40
除了 BYTES参数外,JOB 语句中还有另三个参数可以限制作业输出的最大值,其格式
及子参数的意义也与 BYTES 类似,它们是:CARDS、LINES 及 PAGES。上述三个参数与
BYTES不同之处在于子参数 nnnnnn的单位不同,分别是:卡数、行数及页数,读者可以类
推使用。
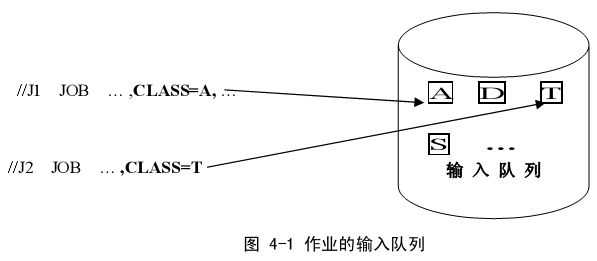
3. CLASS
CLASS 参数规定了作业的类别,JCL 中可选用的作业类别有 36 个,用字母 A~Z 及数
字 0~9 表示。相同类别的作业处于同一输入队列等待执行(如图 4-1),并具有相同的处理
属性。作业类别的属性定义在 JES 中。当 CLASS 参数缺省时,JES 将会根据安装时的缺省
值赋予该作业一个缺省的 CLASS值。
格式:CLASS=jobclass
4.MSGCLASS
用于为作业日志(job log)设置输出类别。作业日志是为程序员提供的与作业相关信息
的记录。当该参数省略时,系统将会采用默认值。
格式:
MSGCLASS=class
class:定义作业日志的类别。与输入队列相似,class 是一个 A~Z 的字母或一个 0~9 的
数字。 例:
//EXMP1 JOB ,GEORGE,MSGCLASS=F
5.MSGLEVEL
用于控制 JCL 作业输出清单的内容,用户可以要求系统打印出如下内容: JCL 语句; 输入流中的所有控制语句,即:所有的 JCL 语句及 JES2 或JES3 语句; 任何作业步调用的流内过程和编目过程语句; 作业控制语句的信息; JES及操作员对作业的处理信息:设备和卷的分配、作业步及作业的执行和终止、
数据集的处理等。
格式:
MSGLEVEL=([statements][,messages])
tatements:指明在 JCL 作业输出清单中应打印出的作业控制语句的类型,取值范围为:
0 ~ 2。
取值 0:仅打印出作业的 JOB 语句;
取值 1:打印出作业中包括过程语句在内的所有JCL 语句;
取值 2:输入流中的所有控制语句。
messages:指明在 JCL作业输出清单中应打印出信息的类型,取值范围为:0 ~ 1。
取值 0:只有在作业异常终止时,打印出有关 JCL、JES、操作员及 SMS的处理信息;
取值 1:无论作业是否异常终止,都打印出有关 JCL、JES、操作员及 SMS的处理信息。
例:
//EXMP3 JOB ,MSGLEVEL=(2,1)
//EXMP4 JOB ,MENTLE,MSGLEVEL=0
//EXMP5 JOB ,MIKE,MSGLEVEL=(,0)
6.NOTIFY
用于请求系统在后台作业处理完毕时给指定用户发送信息。如果作业完成时,该用户未
在系统登录,则系统所发送的信息将会保留到此用户下次登录。
格式:
NOTIFY={userid}
userid:必须以字母或通配符开头的 1~7 个字母、数字或通配符组成,其值必须是一个
存在的 TSO用户标识。 例:
//SIGN JOB ,TLOMP,NOTIFY=TSOUSER
7.PRTY
用于为相应的输入队列中的作业分配优先级。系统根据作业优先级的高低来选择来选择
作业执行,对于同一级的作业的选择将采取“
格式:
PRTY=priority
priority:用数字量来表示优先级,数字越大表示优先级越高。根据作业进入子系统的
类型,其取值范围是 JES2:0~15;JES3:0~14。 例:
//JOBA JOB 1,’JIM WEBSTER’,PRTY=12
8.REGION
用于指定作业所需的实存或虚存空间的大小,系统将在该作业中的每一作业步使用该
值。所需空间大小必须包含以下内容:
运行所有程序所需的空间
在运行期间,程序中宏指令 GETMAIN所需的所有附加空间
任务初始化和终止时需要的自由空间
如果 JOB 语句中的 REGION 参数省略不写的话,系统将采用每条 EXEC语句中所定义
的 REGION 参数,当 EXEC 语句中的REGION 参数省略不写时,系统将采用安装缺省值。
格式:
REGION={valueK}
={valueM}
valueK:以千字节(Kb)为单位指出所需空间大小,
value可取 1~7 位的十进制数,其
取值范围为 1~2096128。系统以每 4k为一存储单位分配空间,所以 value值应取 4 的倍数,如 REGION=68K。当value 值不是4 的倍数时,系统会将其增至一最为接近的 4 的倍数的值。
valueM:以兆字节(Mb)为单位指出所需空间大小,value 可取 1~4 位的十进制数,
其取值范围为 1~2047
注:REGION 值必须是有效的存储空间,如果取值为 0 或任何大于系统极限的值时都有可能会引起存储问题。当系统未定义极限值时,value 值不能超过 16384K 或 16M。
例:
//ACCT1 JOB A23,SMITH,REGION=100K,ADDRSPC=REAL
//ACCT2 JOB 175,FRED,REGION=250K
9.TIME
用于指定作业占用处理器的最长时间并可通过一些信息得知该作业占用处理器的时间。
当作业占用处理器时间超过指定值时,系统将终止该作业。通常情况下,此参数不用设置。
当作业所需处理器时间长于系统缺省值时,或出于某种测试目的才设置此参数。
格式:
TIME={([minutes][,seconds])}
={1440 }
={NOLIMIT }
={MAXIMUM }
minutes:指定作业可占用处理器最长时间的分钟数,取值范围为 0~357912(248.55 天)。
不可以将 TIME 参数写作 TIME=0,这样将导致不可预知的后果。
Seconds:作为 minutes 的补充,定义指定作业可占用处理其最长时间的秒钟数,取值
范围为 0~59。
NOLIMIT:表明作业的运行无时间限制,等同于TIME=1440。
1440:表明表明作业的运行无时间限制,即 24小时。
MAXIMUM:表示作业的运行时间为 357912 分钟。
当 JOB 语句中的 TIME参数没有指明时,每作业步的运行时间限制由以下值决定: EXEC语句中 TIME 参数的值。 EXE 语句中没有设置 TIME 参数时,采用默认的时间限制值(也就是 JES 默认作业步时间限制值)。
例 1:
//STD1 JOB ACCT271,TIME=(12,10)
例 2:
//STD2 JOB ,GOR,TIME=(,30)
例 3:
//FIRST JOB ,SMITH,TIME=2
//STEP1 EXEC PGM=READER,TIME=1
。
。
。
//STEP2 EXEC PGM=WRITER,TIME=1
在上例中,JOB 语句中规定了 2 分钟的作业运行时间限制,每个作业步允许 1 分钟,如果任何一个作业步的执行时间超过 1 分钟,作业将会异常终止。
例 4:
//SECOND JOB ,JONES,TIME=3
//STEP1 EXEC PGM=ADDER,TIME=2
。
。
。
//STEP2 EXEC PGM=PRINT,TIME=2
上例中,JOB 语句中规定了 3 分钟的作业运行时间限制,每个作业步允许 2 分钟,如果任何一个作业步的执行时间超过 2分钟,作业将会异常终止。但两个作业步的总共运行时间不得超过作业运行时间限制 3 分钟,也即:如果作业步 1 的运行时间为 1.56 分钟,则作业步 2 的运行时间不得超过 1.44 分,否则作业也会异常终止。
10.TYPRUN
用于请求特殊的作业处理。TYPRUN可以告知系统如下要求: JES2 中,将输入作业流直接拷贝到系统输出数据集并对其进行输出处理。 JES2 或 JES3 中,挂起一个作业,直至某特定事件发生。当该特定事件发生时,操作员根据用户的要求释放该作业,并允许系统选择该作业执行。使用 JES2 中的/*MASSAGE 语句或 JES3中的//*OPERATOR 语句通知操作员释放该作业。 JES2 或JES3 中,对作业的 JCL进行语法检查。
值得注意的是:不能对已经开始的任务(task)设置该参数,否则该作业将会出错。
格式:
TYPRUN={COPY }
{HOLD }
{JCLHOLD }
{SCAN }
子参数说明:
COPY(仅支持 JES2): 请求 JES2 将输入作业流直接拷贝到系统输出数据集并对其进
行输出处理。系统并不执行该作业。系统输出数据集的类别与该作业JOB语句中MSGCLASS参数定义的信息类别(massage class)相同 。
HOLD:请求系统在执行作业之前将其挂起,等待某特定事件发生后,请求操作员将其
释放。如果在作业的输入过程中出现错误,JES将不会挂起该作业。
JCLHOLD(仅支持 JES2):请求 JES2在 JCL 执行前将其挂起,直到操作员将其释放。
SCAN:请求系统只对作业的 JCL 进行语法检查,不执行也不为其分配设备。
例:
//UPDTAE JOB ,HUBBARD
//STEP1 EXEC PGM=LIBUTIL
。
。
。
//LIST JOB ,HUBBARD,TYPRUN=HOLD
//STEPA EXEC PGM=LIBLIST
。
。
。
上例中,作业 UPDATE 与 LIST 在同一个作业流中被提交执行。作业 UPDATE 的功能
是在库中增加一个成员再删除一个成员;作业 LIST 则列出该库的成员目录。显然,LIST 应
在 UPDATE 之后在执行。作业 LIST 的 JOB 语句中设置的 TYPRUN=HOLD 使得保证了这一
执行顺序。
如果输入流中或操作员已执行了MONITOR JOBNAMES的命令,当UPDATE执行完后系统会通知控制台操作员。操作员释放作业后,系统可以选择该作业执行。
11.其他参数
在 JCL 的 JOB 语句中的关键字参数还有:
COND、GROUP、PASSWORD、PERFORM、RD、RESTART、SECLABEL、USER,
由于本书篇幅有限,在这里就不再一一介绍了,详细的使用方法读者可以参考《MVS JCL
Reference》一书。
EXEC语句:
EXEC 语句标明作业或过程中的每一作业步的开始,并告知系统如何执行该作业步。包括所有在 EXEC 语句中调用的过程中的所有作业步在内,一个作业最多可以有 255 个作业步。
EXEC 语句格式如下:
//[作业步名] EXEC 位置参数[,关键字参数]…[符号参数=值]… [注释]
一、作业步名
作业步名是可以省略不写的,如需标明作业名时,该作业名必须在该作业内以及该作业
调用的所有过程中是唯一的,它由 1~8 个字母或通配符开头的字符数字构成。
二、位置参数
EXEC 语句中的位置参数有两个:PGM 和 PROC。每条 EXEC 语句必须有且仅有一个
位置参数或过程名。
1. PGM
PGM 参数用于指明所要执行的程序名。该程序必须是一个分区数据集(PDS)的成员
或用作系统库(system library)、私有库(private library)及临时库(temporary library)的
扩充分区数据集(PDSE)的成员。程序名的调用方法分为直接调用和间接调用。
格式:
PGM={program-name}
{*.stepname.ddname}
{*.stepname.procstepname.ddname}
program-name:program-name(程序名)指明要执行程序的成员名或别名。程序名由
由 1~8 个字母或通配符开头的字符数字构成。
*.stepname.ddname:表示要执行的程序名由本 stepname”的作业步内名为“ddname”的 DD语句的 DSN 参数决定。
*.stepname.procstepname.ddname:表示要执行的程序名由本 stepname”的作业步里所调用过程内名为“procstepname”的过程步中相应名为“ddname”DD 语句DSN 参数决定。
在上述三种程序调用方法中,第一种为直接调用,而后两种为间接调用,间接调用采用
向后参考的方法,这里的“后”指在本作业步读入之前,已先读入系统的本作业其它 JCL
语句。当需调用的程序在系统库(如 SYS1.LINKLIB)或私有库(由作业中的JOBLIB DD 语句或本作业步中的 STEPLIB DD 定义)中时使用第一种调用方法;而当需调用的程序在本作业步前的某一作业步创建的临时库中时采用后两种调用方法。
例:
//JOBC JOB ,JOHN,MSGCLASS=H
//STEP2 EXEC PGM=UPDT
//DDA DD DSNAME=SYS1.LINKLIB(P40),DISP=OLD
//STEP3 EXEC PGM=*.STEP2.DDA
在上例中,名为 STEP3 的EXEC 语句采用程序间接调用方式,所调用的程序名由作业
步 STEP2 中的名为DDA 的DD 语句决定,在该DD 语句中定义了系统库 SYS1.LINKLIB,
程序 P40 是该库的一个成员。“P40”即STEP3 中要调用执行的程序名。关于DD 语句的详
细情况我们将在后面讨论。
2. PROC
指明作业步所要运行的过程名。
格式:
{PROC=procedure-name}
{procedure-name }
procedure-name:需要调用的过程名,过程名由1~8 个字母或通配符开头的字符数字构成。所调用的过程名可以是:
·编目过程的成员名或别名。
·由PROC 语句定义的流内过程的过程名,该流内过程必须在本作业内且本作业步前定义。
在设定该参数时,可直接写出过程名。
例:
//SP EXEC PROC=PAYWRKS
//BK EXEC OPERATE
三、 关键字参数
EXEC 语句的关键字参数是可选的,这些参数制作用于本作业步。当EXEC 语句的位置
参数指定程序名时,关键字参数的写法同 JOB 语句;当 EXEC 语句的位置参数指定编目或
流内过程时,EXEC 语句的关键字参数将覆盖所调用过程中各EXEC 语句的关键字参数。因
此如果想仅覆盖过程中的某个 EXEC 语句的关键字参数,则应在设置关键字参数时,同时指出所调用过程的相关过程步的名字。书写形式如下:
关键字参数.过程步名=值
下面将分别介绍EXEC语句中常用的关键字参数:
1. ACCT
指明作业步所需的一个或多个记账信息子参数。记账信息参子参数最多不可超过 142
个字符(包括分隔子参数的逗号,但不包括括起子参数列表的括号)。
格式:
ACCT[.过程步名]=(记账信息)
例:
//STP3 EXEC PROC=LOOKUP,ACCT=(‘/83468’)
2.ADDRSPC
指明作业步所需之存贮类型,它有两个子参数:VIRT 及REAL。VIRT 表示作业步请求
虚拟页式存贮,而REAL 表示作业步请求实存空间,不能进行页式处理。缺省值为VIRT 。
EXEC 语句中的 ADDRSPC 参数仅在本作业步中起作用,JOB 语句中的 ADDRSPC 参数会
覆盖该作业中的所有EXEC 语句中的ADDRSPC 参数。
格式:
ADDRSPC[.过程步名]={VIRT}
{REAL}
例:
//CAC1 EXEC PGM=A,ADDRSPC=VIRT
//CAC2 EXEC PROC=B,ADDRSPC=REAL,REGION=100K
3.REGION
用于指定作业步所需的实存或虚存空间的大小,系统仅在本作业步中使用该值。
格式:
REGION[.过程步名]={valueK}
={valueM}
EXEC 语句中REGION 的子参数定义与JOB 语句中相同。
例:
//MKBOYLE EXEC PROC=A,REGION=100K,ADDRSPC=REAL
//STEP6 EXEC PGM=CONT,REGION=250K
4. TIME
用于指定作业步占用处理器的最长时间,并可通过作业输出清单得知该作业步占用处理器的时间。当作业步占用处理器时间超过指定值时,系统将终止该作业。
格式:
TIME[.过程步名]={([minutes][,seconds])}
={1440 }
={NOLIMIT }
={MAXIMUM }
EXEC 语句与JOB 语句中的TIME 参数的子参数的设置方法基本相同。值得注意的是:
在JOB 语句中不可设置TIME=0,而在EXEC 语句中则可以设置TIME=0,当TIME=0 时表
示本作业步的执行时间由前面作业步的剩余执行时间决定。
例 1:
//STP1 EXEC PGM=ACCT,TIME=(12,10)
例2:
//STP2 EXEC PGM=PAY,TIME=(,30)
例3:
//FIRST JOB ,SMITH MSGLEVEL=(1,1)
//STEP1 EXEC PGM=READER,TIME=1
·
·
·
//STEP2 EXEC PGM=WRITER
·
在上例中,STEP1 规定了 1 分钟的执行时间,STEP2 的运行时间将由STEP1 决定,也
即STEP2 的执行时间为:(1 分钟 – STEP2 实际运行时间)。
5. COND
用于对先前作业步执行的返回码(return code )进行测试,以决定是否执行本作业步。
用户可以对特定作业步的返回码进行测试也可以对每一执行完毕的的返回码都进行测试。如
果测试条件不满足,系统执行本作业步;如果测试条件满足系统则不执行该作业步。作业中
的第一个EXEC 语句中的 COND 参数将被系统忽略。注意,当测试条件满足时,系统并非
不正常终止该作业步,而只是跳过该作业步,该作业仍将正常执行。
格式:
(1)COND[.过程步名]=(code,operator)
(2)COND[.过程步名]=((code,operator[,作业步名][,过程步名])
[,(code,operator[,作业步名][,过程步名])]…[,EVEN])
[,ONLY]
(3)COND=EVEN
COND=ONLY
利用COND 参数最多可以有 8 个返回码测试,如果有EVEN 或ONLY 时,最多有7 个
测试。格式(1)只有在先前作业步没有非正常终止时,才能进行该测试。格式(2 )、(3)
测试决定于EVEN 和ONLY 的设置。
code:系统使用code (测试码)与先前作业步或某特定作业步的返回码进行比较。Code 的取值范围为:0~4095。
operater:表示code 与返回码的比较类型,这些比较的操作符是:GT (大于)、GE (大
于等于)、EQ (等于)、NE (不等于)、LT (小于)、LE (小于等于)。
作业步名:指定先前某一作业步,并用该作业步的返回码与本作业步的测试码进行比较。
当省略作业步名时,表示本作业步的测试码将与先前所有作业定额的返回码进行比较测试。
作业步名.过程步名:指定先前某一作业步调用过程的过程步。系统将用该过程步的返
回码与给定的测试码进行比较。其中该作业步由“作业步名”指定,而过程步由“过程步名” 指定。
EVEN:表示无论即使先前作业步异常终止,本作业步都要执行。当EVEN 子参数设定
时:
| EVEN/ ONLY |
先前作业步是否异常终止? |
测试条件是否满足? |
本作业步是否 执行? |
| EVEN |
否 |
否 |
是 |
| EVEN |
否 |
是 |
否 |
| EVEN |
是 |
否 |
是 |
| EVEN |
是 |
是 |
否 |
| ONLY |
否 |
否 |
否 |
| ONLY |
否 |
是 |
否 |
| ONLY |
是 |
否 |
是 |
| ONLY |
是 |
是 |
否 |
例 1.
//STEP6 EXEC PGM=DISKUTIL,COND=(4,GT,STEP3)
在本例中如果 STEP3 的返回码小于4,系统将不执行STEP6。由于没有设置EVEN 或
ONLY,如果先前的作业步异常终止,系统将不会执行本作业步。
例2.
//TEST2 EXEC PGM=DUMPINT,COND=(16,GE),(90,LE,STEP1),ONLY)
由于设置了ONLY 子参数,系统只在以下两种情况满足时执行本作业步:
(1)先前作业步异常终止;
(2 )返回值的测试条件都不满足。
那么对于本例来说,系统将会在以下三种情况都满足的情况下执行本作业步:
·一个先前作业步异常终止。
·所有先前作业步的返回码大于等于17。
·STEP1 的返回码小于等于89。
例3.
//STEP1 EXEC PGM=CINDY
·
·
·
//STEP2 EXEC PGM=NEXT,COND=(4,EQ,STEP1)
·
·
·
//STEP3 EXEC PGM=LAST ,COND=((8,LT,STEP1),(8,GT,STEP2))
·
在本例中,如果 STEP1 的返回码为4,STEP2 将不被执行。在 STEP3 执行前,系统将执行第一个返回码测试。而由于 STEP2 并未被执行,所以将不会进行第二个返回码的测试。 由于8 大于4 所以 STEP3 被执行。
例4.
//STP4 EXEC PROC=BILLING,COND.PAID=((20,LT),EVEN),
// COND.LATE=(60,GT,FIND),
// COND.BILL=((20,GE),(30,LT,CHGE))
在本例中的EXEC 语句调用了一个名叫BILLING 的过程。这条语句中定义了几个不同
的分别对过程步PAID、LATE、BILL 的返回码的测试。由于设置了EVEN 子参数,除非相应的返回值测试满足条件,那么即使先前作业步异常终止,过程步PAID 都将被执行。
6. PARM
用于向本作业步执行的程序传递变量信息。该程序必须有相应的指令接收这些信息,并
使用它们。
格式:
PARM[.过程步名]= 子参数
PARM[.过程步名]=( 子参数, 子参数)
PARM[.过程步名]=(‘子参数’, 子参数)
PARM[.过程步名]=’子参数, 子参数’
包括所有的逗号、撇号以及括号在内,所有子参数的总长度不得超过 100 个字符。当某子参数中含有特殊字符或空格时,可以将该子参数用撇号括起来,在其它子参数一起用括号括起来,或将所有在参数用撇号括起来。
子参数:包含传递给程序的变量信息。
例 1.
//RUN3 EXEC PGM=APG22,PARM=’P1,123,P2=5’
在本例中,系统将参数P1、123 及P2=5 传递给程序APG22 。
例2.
// STP6 EXEC PROC=ASFCLG,PARM.LKED=(MAP,LET)
在本例中系统将MAP、LET 传递到过程ASFCLG 中名为LKED 的过程步。
DD 语句 :
数据定义语句(DD 语句)用于定义一个数据集以及该数据集所需的输入输出资源。DD
语句相对与前面介绍过的 JOB 语句和 EXEC 语句来说,其参数的定义、子参数的设置要复
杂一些,在本小节内我们将仅讨论DD 语句的一般规则以及部分位置参数,关于DD 语句的
一些常用参数以及特殊用法我们将用单独的一节讨论。
一、 格式:
//[dd 名 ] DD [位置参数][,关键字参数]… [注释]
[过程步名.dd 名]
//[dd 名 ] DD
[过程步名.dd 名]
二、dd 名
“dd 名”是为 DD 语句定义的名字,它由 1~8 个字母或通配符开头的字符数字构成。
在一个作业步内可以有多个 DD 语句,但每个 DD 语句的 dd 名在本作业步中应该是唯一确定的。“dd 名”可以由系统定义也可以由用户自己定义,当用户需要调用公用程序时,需根据公用程序的具体要求选用系统定义的“dd 名”。用户自定义的“dd 名”不可与系统定义“dd名”相重复。系统定义“dd”名有如下几个:
JOBCAT SYSCHK
JOBLIB SYSCKEOV
STEPCAT SYSIN
STEPLIB SYSMDUMP
SYSBEND SYSDUMP
JES2 子系统中:
JESJCLIN JESMSGLG
JESJCL JESYSMSG
JES3 子系统中:
JCBIN JESJCL JS3CATLG
JCBLOCK JESMSGLG J3JBINFO
JCBTAB JOURNAL J3SCINFO
JESJCLIN JOURNAL J3STINFO
JESInnnn JESYSMSG STCINRDR
TSOINRDR
用户子定义“dd 名”可以根据数据的用途,遵循“dd 名”的规则来命名,当为应用程序输入输出结果定义数据集时,“dd 名”的命名规则取决于程序所用语言的类型。汇编语言由DCB 宏指令指定;COBOL 语言由ASSIGN 子名指定;PL/1 语言由DECLARE 语句指定;
FORTRAN 语言由READ 或WRITE 语句中的通道号构成。
三、参数
DD 语句的参数也分为位置参数及关键字参数,这些参数都是可选的。每个DD 语句只能有一个位置参数,但根据需要可以有个关键字参数。位置参数有“* ”、“DATA ”和
“DUMMY”。在本小节中将只介绍位置参数的使用,关键字参数将在下一节中介绍。
1.参数“*”
参数“*”用于开始一个流内数据集。数据记录跟在“DD ”语句之后,其第一、二列不能是“// ”或“/*”;该记录可以是任何编码,如EDCBIC。下列符号表明流内数据记录的结束:
·输入流中的“/* ”。
·表示另一个JCL 语句开始的“// ”。
当数据记录中需以“// ”开始时,就必须使用DATA 参数来代替“*”参数。
格式:
//dd 名 DD *[,参数]… [注释]
例 1.
//INPUT1 DD *
·
·
data
·
//INPUT2 DD *
·
·
data
·
/*
例2.
//INPUT3 DD *,DSNAME=&&INP3
·
data
·
/*
例3.
//STEP2 EXEC PROC=FRESH
//SETUP.WORK DD UNIT=3400-6,LABEL=(,NSL)
//SETUP.INPUT1 DD *
·
·
data
·
/*
//PRINT.FRM DD UNIT=180
//PRINT.INP DD *
·
·
data
·
/*
例 3 在输入流中定义了两组数据。DD 语句“SETUP.INPUT1”定义的输入数据将被编
目过程中名为“SETUP”的过程步使用。而DD 语句“PRINT.INP”定义的输入数据将被编
目过程中名为“PRINT”的过程步使用。
2. DATA
用作一个流内数据集的开始,该流内数据集里含有以“// ”开头的语句。数据记录紧跟在“DD DATA”语句之后;该数据记录可以是BCD 或EDCBIC 编码。数据记录将以“/* ”
作为结束。
格式:
//dd 名 DD DATA[,参数]… [注释]
例 1.
//GROUP1 DD DATA
·
·
data
·
//GROUP2 DD DATA
·
·
data
·
/*
例2.
//GROUP3 DD DATA,DSNAME=&&GRP3
·
data
·
/*
例3.
//STEP2 EXEC PROC=UPDATE
//PREP.DD4 DD DSNAME=A.B.C,UNIT=3350,VOLUME=SER=D88230
// SPACE=(TRK,(10,5)),DISP=(,CATLG,DELETE)
//PREP.IN1 DD DATA
·
·
data
·
/*
//ADD.IN2 DD *
·
·
data
·
/*
3. DUMMY
DUMMY 参数用于标明:
(1) 没有设备或外存空间分配给该数据集。
(2 ) 对该数据集不进行状态处理。
(3) 对BSAM (Basic Sequential Access Method )或QSAM (Queued Sequential Access Method )来说,不对该数据集作输入输出操作。
用户使用 DUMMY 参数对程序进行测试。当测试完成时,如果用户希望恢复对数据集
的输入输出操作时,只需将DD DUMMY 参数替换成完整的数据集定义DD 语句。DUMMY
的另一个用途是在编目或流内过程中,这将会在本章后续节中讨论。
格式:
//dd 名 DD DUMMY[,参数]…
所有在DUMMY 语句中的参数必须在语法上是正确的。系统将对他们进行语法检查。
例 1.
//OUTDD1 DD DUMMY,DSNAME=X.X.Z,UNIT=3380,
// SPACE=(TRK,(10,2)),DISP=(,CATLG)
本例中 DD 语句“OUTDD1”定义了一个空数据集。该语句中除DUMMY 以外的参数将接受系统语法检查但并不起作用。
DD语句的关键字参数
DD 语句的关键字参数及其相关内容相对JOB 语句和EXEC 语句来说比较复杂,所以在
这里作为单独的一节讲述。DD 语句的关键字参数有很多,但总体上可分为两大类,一类与
设备相关,另一类则与数据集或数据相关,与设备相关的参数有 UNIT、 VOLUME、SPACE、
LABEL 等,与数据集、数据相关的参数有 DSNAME、 DISP、 DCB、RECORG、EXPDT、
RETPD、PROTECT、SYSOUT、HOLD 等。在实际应用中,这两类参数是配合使用的,没有一个绝对的分界线。DD 语句通过这些参数完成下述任务:
(1)定义顺序数据集(sequential data set)或分区数据集(partitioned data set )名;
(2)描述数据集状态、属性及保留期限;
(3)描述设备类型、数量;
(4)设置数据集的记录格式、占用空间;
(5)描述作业的处理方式。
DD 语句的关键字参数很多,在本节中我们仅讨论一些最常用的参数,并介绍一些基本
概念及实例,以便于大家进一步的学习。
1. UNIT
UNIT 参数用于请求物理设备,用户通过设置设备地址或设备类型或设备组名等子参数
确定设备;通过设置设备数或P 等子参数确定设备数量。
格式:
{UNIT=([三位设备地址 ] [,设备数] [,DEFER])}
[/三位设备地址] [,P ]
[/四位设备地址] [, ]
[设备类型 ]
[设备组名 ]
{UNIT=AFF=DD 名}
设备地址:通过设备地址指定设备。设备地址是在系统安装时建立的,它由一个3 位的十进制数或 4 位十六进制数构成。如用户请求的某设备其地址为 340 时,参数设置为
UNIT=340 。
设备类型:通过设备类型名称指定设备,这个名称通常是数字的,如通过 3480、3422
指定磁带机,通过3340、3375、3380、3390 指定磁盘机。如用户请求设备是3380 磁盘机时,参数设置UNIT=3380 。
设备组名:通过设备组名请求一台或一组设备。被定义在一组中的设备可以是相同的,
也可以可以是不同的。如一组设备中可以包含磁盘设备也可包含磁带设备。但通常都是将一
类设备作为一个设备组,具体的设备组名在系统安装时定义。设备组名由 l—8 个字母符号构成,常见的有 SYSDA、DASD、TAPE、CART 等。如需要直接访问的存储设备时,参数
设置为:UNIT=DASD 。
设备数:指定数据集所需的设备数量,取值范围为1~59。
SER:SER 子参数的设置方式有两种:“SER=卷标号”和“SER=(卷标号[,卷标号]...)”,
卷标号由 l~6 位的数字字母、通配符或特殊字符构成。用户通过 SER 定义数据集已占用或 将占用的卷标号。在一个 DD 语句中最多可以有 255 个互不相同的卷标号。但需要注意的 是:卷标号不能取作 SCRTCH、PRIVAT、 Lnnnnn(字母 L 带5 个数)或MIGAT。
REF :REF 子参数的设置方式有如下四种:“REF=数据集名”、“REF=* .DD 名”、
“REF=*.作业步名.DD 名”及“REF= *.作业步名.过程步名. DD 名”。通过 REF 子参数可以从其它已知数据集或本语句前某个DD 语句中获得所需的卷标号。
(1)“REF=数据集名”表示从其它已知数据集所在卷获得卷标号,定义中的数据集可
以是编目数据集,也可以是由本语句前某个DISP 参数传过来的数据集,但它不能是生成数
据集(GDG)或 其成员。
(2 )“REF=*.DD 名”表示从本作业步中的由“DD 名”指定的 DD 语句中获得卷标号。
(3)“REF=*.作业步名.DD 名”表示由指定的作业步中指定的 DD 语句获得所需卷标,其中作业步与DD 语句分别由“作业步名”与“DD 名”指定。
(4 )“REF=*.作业步名.过程步名.DD 名”表示从相关过程步中的相关 DD 语句中获得卷标,这个过程是由指定的作业步调用的。其中作业步、过程步、及DD 语句分别由“作业步名”、“过程步名”及“DD 名”指定。
例 1.
//STEP2 EXEC PGM=POINT
//DDX DD DSNAME=EST,DISP=MOD,VOLUME=SER=(42569,42570),
// UNIT=(3480,2)
//DDY DD DSNAME=ERAS,DISP=OLD,UNIT=3480
//DDZ DD DSNAME=RECK,DISP=OLD,
// VOLUME=SER=(40653,13262),UNIT=AFF=DDX
DD 语句DDX 请求分配两个 3480 设备,DD 语句DDZ 申请分配与DDX 相同的两个设备。DD 语句DDY 申请分配一个3480 设备。
例2.
//DD2 DD DSNAME=X.Y.Z,DISP=OLD,UNIT=(,2)
本例中的DD 语句定义了一个已编目的数据集,并且要求系统赋予两个设备给这个数据集,设备类型可以从相应的编目中获得。
例3.
//DD3 DD DSNAME=COLLECT,DISP=OLD,
// VOLUME=SER=1095,UNIT=(3590,,DEFER)
在本例中定义了一个位于磁带卷上的已存在的数据集,并且请求系统分配一个 3590 磁带设备。由于指定了DEFER 子参数,相应的磁带卷直到数据集被打开时才会装载。
例4
//STEPA DD DSNAME=FALL,DISP=OLD,UNIT=237
对于这个数据集来说,系统将会从相应的编目中检索它的卷和设备类型。由于UNIT 参数被指定为设备237,这将覆盖数据集在编目中的设备类型定义,因此要求设备237 应该与
编目中的定义相同。
2. VOLUME
通过VOLUME 参数可以指定所引用的数据集所在的卷或卷组,也可以用来指定新建数
据集所在的卷或卷组。在使用这个参数时,用户可以指定一个特定的卷、一组卷、具有特定
序列号的卷或另外一个数据集所使用的卷。对于一个跨越多个卷的数据集来说,这个参数还
可以用来指定首先被处理的卷。对于一个新建的数据集来说,可以通过不指定VOLUME 参
数或在VOLUME 参数中不指定 SER 和 REF 子参数的方法在任何一个卷或卷组上创建该数
据集,我们称这种方法为非特定卷。
格式:
{VOLUME} = ([PRIVATE] [,RETAIN] [,卷顺序号] [,卷数])
{VOL } [, ] [, ]
[SER=序列号 ]
[SER=(序列号[,序列号]...) ]
[,] [REF=数据集名 ]
[REF=*.DD 语句名 ]
[REF=*.作业步名.DD语句名 ]
[REF=*.作业步名.过程作业步名. DD 语句名]
PRIVATE:
申请一个私有的卷。这里的私有卷是指:
1.除非使用VOLUME=SER 子参数明确地请求这个卷,否则系统不会在这个卷上
分配输出数据集。
2.对于一个磁带卷来说,除非指定了RETAIN 子参数或在DISP 参数中指定PASS,
否则这个磁带卷将会在数据集关闭后被卸载。
3.对于一个可卸载的直接访问卷来说,这个卷将在数据集关闭后被卸载。
RETAIN:
对于一个私有的磁带卷来说,指定 RETAIN 子参数表示在数据集关闭后或在作业步结束后,这个卷不会被卸载;对于一个公共的磁带卷来说,如果这个卷在作业中被卸载,它将保留在相应的设备上。
卷顺序号:
用来在一个多卷的数据集确定开始处理的卷。卷顺序号为 1~255 的十进制数,第一
个卷的顺序号为 1,卷的顺序号必须小于等于数据集所占用的实际卷数,否在作业将会失败。如果不指定卷顺序号,则系统从 1 开始处理。
对于一个新数据集系统将忽略所指定的卷顺序号。
卷数:
用来确定一个输出数据集所申请的卷的最大数量。卷数为 1~255 的一个十进制数,
在一个作业步中所有的DD 语句中的卷数总和不能超过4095。
SER=序列号
SER=(序列号[,序列号]...)
通过卷的序列号用来确定数据集占用或将占用那些卷。一个卷的序列号为 1~6 个字符可以包含字母、数字和$、#、@等特殊字符。不足6 位的序列号将被空格填满。
在一条 DD 语句中最多可以指定 255 个卷序列号。不要在一个 SER 子参数中指定
重复的序列号,无论是磁带卷还是磁盘卷,每个卷都应该有唯一的卷序列号。
不要将序列号指定为 SCRTCH、PRIVAT 或Lnnnnn (L 后有五个数字),这些名字已
经被用在请求操作员装载卷的消息中;不要将序列号指定为 MIGRAT ,这个名字被
DFHSM(Data Facility Hierarchical Storage Manager)用来做数据集的移植。
REF=数据集名
REF=*.DD 语句名
REF=*.作业步名.DD 语句名
REF=*.作业步名.过程作业步名.DD 语句名
用来表示系统将从其它的数据集或前面的DD 语句中获得卷序列号的信息。
例 1
//DD1 DD DSNAME=DATA3,UNIT=3340,DISP=OLD,
// VOLUME=(PRIVATE,SER=548863)
在这个DD 语句中指定了一个已存在的数据集,这个数据集位于一个直接访问的卷上,
卷的序列号为 548863。由于指定了PRIVATE,系统将不会将这个卷分配给另外一个申请非
特定卷的数据集,在当前作业结束时系统将会释放这个卷。
例2
//DD2 DD DSNAME=QUET,DISP=(MOD,KEEP),UNIT=(3400-5,2),
// VOLUME=( , , ,4,SER=(96341,96342))
这条DD 语句中指定了一个已存在的数据集,这个数据集跨越两个卷,卷的序列号分别为96341 和96342。如果需要,可以在VOLUME 参数中指定4 个卷,当需要更多的空间时系统会分配第三和第四个卷。
例3
//DD3 DD DSNAME=QOUT,UNIT=3400-5
这个DD 语句中定义了一个在作业步中创建并在同一作业步中被删除的数据集。通过不指定VOLUME 参数表明在卷的分配上采用非特定卷的方式。
例4
//DD4 DD DSNAME=NEWDASD,DISP=(,CATLG,DELETE),UNIT=3390,
// VOLUME=SER=335006,SPACE=(CYL,(10,5))
创建了一个新的数据集,这个数据集位于序列号为 335006 的卷上,这个卷是位于特定的3390 设备上的永久卷。
例 5
//OUTDD DD DSNAME=TEST.TWO,DISP=(NEW,CATLG),
// VOLUME=( , , , 3,SER=(333001,333002,333003)),
// SPACE=(TRK,(9,10)),UNIT=(3330,P)
//NEXT DD DSNAME=TEST.TWO,DISP=(OLD,DELETE)
在DD 语句 OUTDD 中创建了一个多卷数据集并且对这个数据集进行编目,当然如果这个数据集不需要这么多卷的话,可以使用较少的卷。在 DD 语句 NEXT中删除了这个数据集。
如果用户在多个卷上对数据集进行编目而实际上数据集仅使用了减少的卷的话,那么当
系统删除这个数据集时下列信息将会被加入到作业日志中。
IEF285I TEST.TWO DELETED
IEF285I VOL SER NOS=333001,333003.
IEF283I TEST.TWO NOT DELETED
IEF283I VOL SER NOS=333002 1.
IEF283I TEST.TWO UNCATALOGED
IEF283I VOL SER NOS=333001,333002,333003.
但如果数据集使用了所有分配给它的卷的话,当系统删除这个数据集时作业日志中将会包含下列信息。
IEF285I TEST.TWO DELETED
IEF285I VOL SER NOS=333001,333002,333003.
例 6
//STEP1 EXEC PGM=....
//DD1 DD DSN=OLD.SMS.DATASET,DISP=SHR
//DD2 DD DSN=FIRST,DISP=(NEW,CATLG,DELETE),VOL=REF=*.DD1
//STEP2 EXEC PGM=...
//DD3 DD DSN=SECOND,DISP=(NEW,CATLG,DELETE),VOL=REF=*.STEP1.DD1
在作业步 STEP1 中的DD 语句 DD1 标志了一个 SMS 数据集 OLD.SMS.DATASET,在
作业步STEP1 中的DD 语句DD2 和STEP2 中的DD 语句DD3 分别创建了一个SMS 数据集,
数据集的属性引用在DD1 中标志的数据集的属性。
3. SPACE
SPACE 参数用于为新建数据集分配磁盘空间,对于磁带卷不起作用。请求空间分配一
般有两种方法:一是告知系统所需空间大小,由系统来分配合适的空间;二是请求系统分配
某个特定的空间,如:从某个特定磁道到另一个特定磁道。
通常用第一种情况。用此种方法,用户告诉系统所要分配空间的存贮单位及存贮空间单位的数量。空间存贮单位可以是磁道(TRK)、柱面(CYL)、块长及记录长。不同类型的磁盘
设备磁道、柱面容量也不同,所以为数据集分配空间时,要清楚用户所用的设备类型及磁道、
柱面的容量。以 3380 为例,共有 885 个柱面,每个柱面有 15 个磁道,每个磁道的容量为47476 字节。
格式:
由系统分配空间:
SPACE=({TRK,}(初次分配数量[,再次分配数量][,目录空间])[,RLSE][,CONTIG][,ROUND])
({CYL,} [, ][,索引 ] [, ][,MXIG ]
({块长度, } [,ALX ]
({记录长度,} [, ]
请求特定的磁道:
SPACE= (ABSTR,(初次分配数量,地址[,目录空间])
[,索引 ]
仅请求目录空间:
SPACE=(,(,,目录空间))
由系统分配空间:
TRK:表示系统以磁道为单位分配空间。
CYL:表示系统以柱面为单位分配空间。
块长度:用来指定数据的平均块长度(字节),块长度是0~65535 的一个十进制数。这里 指定的块长度用来作为空间分配的单位。(仅在AVGREC 没有指定的情况下使用)
记录长度:在 SMS 环境下用来指定数据的平均记录长度(字节),记录长度是 0~65535
的一个十进制数。这里指定的块长度用来作为空间分配的单位。(仅在指定AVGREC 和 SMS
激活的情况下使用)
初次分配数量:初次为数据集分配的空间的大小,单位为磁道、柱面等。如果使用TRK
或 CYL 作为单位为一个分区数据集分配空间,则初次分配的空间包含了目录空间;如果使
用块长度或记录长度作为单位为一个分区数据集分配空间,则初次分配的空间不包含目录空
间,系统另外分配目录空间。所要求的卷必须有足够的空间用于分配,否则作业将失败。
再次分配数量:当为数据集所分配的空间用完时,指定再次为数据集分配空间的数量。
目录空间:指定在一个分区数据集中用来作为目录的长度为256 字节的记录的数量。
索引:对于一个索引顺序数据集的索引来说,用来指定所需的磁道或柱面,所需的磁道数应该等于一个或多个柱面。
RLSE:表示在数据集关闭时,那些分配给数据集但没有被使用的空间将会被释放。前
提条件是数据集必须为了输出被打开并且最后一个操作为写操作。
CONTIG:指定分配给数据集的空间必须是连续的,这个子参数仅仅影响初次分配。
MXIG:要求为数据集分配的空间必须 1、是卷上最大的连续空间 2、大于或等于初次
分配的空间大小。这个子参数仅仅影响初次分配。
ALX:作业在分配空间是将获得卷上最多 5 个最大的连续空间,并且每一个空间都应
大于或等于初次分配的空间大小。这个子参数仅仅影响初次分配。
ROUND:只有在第一个子参数指定为块长度时表示分配的空间必须等于整数柱面,其
它情况下忽略这个子参数。
申请特定的磁道:
ABSTR:表示将在卷上特定的位置为数据集分配空间。
初次分配数量:指定为数据集分配的磁道数,要求卷上必须有足够的空间。
地址:指定分配的第一个磁道的磁道号,第一个柱面上第一个磁道的磁道号为0。
例 1
//DD1 DD DSNAME=&&TEMP,UNIT=MIXED,SPACE=(CYL,10)
在这个DD 语句中定义了一个临时数据集。UNIT 参数为数据集申请任何有效的磁带或
直接访问设备卷,其中MIXED 是一组磁带和直接访问设备的安装名。如果获得的是磁带卷
的话,SPACE 参数被忽略;如果获得的是直接访问设备卷的话,SPACE 参数被用来为数据
集分配空间。在本例中 SPACE 参数通过子参数指定了分配的单位和初次分配的数量:10 个
柱面。
例2
//DD2 DD DSNAME=PDS12,DISP=(,KEEP),UNIT=3350,
// VOLUME=SER=25143,SPACE=(CYL,(10,,10),,CONTIG)
在 DD 语句中定义了一个新的分区数据集,系统将为这个数据集分配 10 个柱面,其中 创建 10 个256 字节的记录作为目录。由于指定了CONTIG 子参数,系统将在卷上为数据集分配 10 个连续的柱面。
例3
//REQUEST1 DD DSNAME=EXM,DISP=NEW,UNIT=3330,VOLUME=SER=606674,
// SPACE=(1024,75),DCB=KEYLEN=8
//REQUESTA DD DSNAME=EXQ,DISP=NEW,UNIT=3380,
// SPACE=(1024,75),DCB=KEYLEN=8
在本例的DD 语句中根据块长分配空间。数据的平均块长为 1024 字节,需要申请75 个数据块,每一个数据块前都需要有一个 8 个字节长的键,系统将会根据UNIT 参数指定的设备计算需要多少个磁道。
例4
//REQUEST2 DD DSNAME=PET,DISP=NEW,UNIT=3330,VOLUME=SER=606674,
// SPACE=(ABSTR,(5,1))
在本例中,SPACE 参数指定系统从卷上的第2 个磁道起为数据集分配 5 个磁道。
例 5
//DD3 DD DSNAME=MULTIVOL,UNIT=3350,DISP=(,CATLG),
// VOLUME=SER=(223344,223345),SPACE=(CYL,(554,554))
这是一个在两个完整的卷上创建一个多卷数据集的例子,在这两个卷上不包含任何其它
的数据集。一个3350 设备上的卷包含555 个柱面,未非配的柱面用来存放VTOC 。
4. DSNAME
DSNAME 参数被用来指定一个数据集的名字。对于一个新建的数据集来说 DSNAME
参数给定新数据集的名字;对于已存在的数据集来说,通过DSNAME 参数来定位这个数据
集。
格式:
{DSNAME} = 名字
{DSN }
例 1.
//DD1 DD DSNAME=ALPHA,DISP=(,KEEP),
// UNIT=3420,VOLUME=SER=389984
在 DD 语句 DD1 中定义了一个名字为ALPHA 的新数据集,随后的作业步或作业中的DD 语句可以通过指定DSNAME、UNIT 和VOLUME 参数来引用这个数据集。
例2
//DDSMS1 DD DSNAME=ALPHA.PGM,DISP=(NEW,KEEP),DATACLAS=DCLAS1,
// MGMTCLAS=MCLAS1,STORCLAS=SCLAS1
在 DD 语句 DDSMS1 中定义了一个名字为ALPHA.PGM 的新 SMS 数据集,随后的作业步或作业中的 DD 语句可以通过指定 DSNAME 参数为ALPHA.PGM 来引用这个 SMS 数据集。
例3
//DD2 DD DSNAME=LIB1(PROG12),DISP=(OLD,KEEP),UNIT=3350
// VOLUME=SER=882234
DD 语句DD2 中引用分区数据集LIB1 中的数据集成员PROG12 。
例4
//DDIN DD DATA,DSNAME=&&PAYIN1
.
数据
.
/*
在DD 语句DDIN 中指定PAYIN1 作为系统为内部流数据集产生的数据集名的最后一个
部分,这个数据集的名字将会是下面这种形式:
用户ID.作业名.作业ID.D 数据集号.PAYIN1
例 5
//DDOUT DD DSNAME=&&PAYOUT1,SYSOUT=P
在DD 语句DDOUT 中指定PAYOUT1 作为系统为系统输出数据集产生的数据集名的最
后一个部分,这个数据集的名字将会是下面这种形式:
用户ID.作业名.作业ID.D 数据集号.PAYOUT1
例 6
//DD3 DD DSNAME=&&WORK,UNIT=3420
在 DD 语句 DD3 中定义了一个临时数据集。一般来说由于临时数据集将在作业步结束时被删除,所有用户可以在DD 语句中省略DSNAME 参数。
例 7
//STEP1 EXEC PGM=CREATE
//DD4 DD DSNAME=&&ISDATA(PRIME),DISP=(,PASS),UNIT=(3350,2),
// VOLUME=SER=334859,SPACE=(CYL,(10,,2),,CONTIG),DCB=DSORG=IS
//STEP2 EXEC PGM=OPER
//DD5 DD DSNAME=*.STEP1.DD4,DISP=(OLD,DELETE)
在 STEP1 的DD 语句DD4 中定义了一个名为ISDATA 的临时的索引顺序数据集,这条
DD 语句为这个索引顺序数据集定义了所有的区域。在 STEP2 中的DD 语句 DD5 通过引用
前面作业步中的 DD 语句的方式来引用这个数据集,因此这个临时数据集并不会在 STEP1
结束时被删除。