LeNet-Pytorch-MNIST手写数字识别
LeNet-Pytorch-MNIST手写数字识别
近几年,基于深度学习的应用越来越多,可以说深度学习已经遍及我们生活的各个角落。同时卷积神经网络(CNN: Convolution Neural Network)在计算机视觉领域大放光彩,作为一名没有跨入深度学习门槛的萌新,在迷茫了一阵时间以后,还是打算从最基本的LeNet-5网络学起,并用现在比较流行的Pytorch将其实现。通过写博客,一方面可以加深自己的理解,另一方面希望能够帮助需要的人。由于水平有限,博客中不免存在一些问题,请在评论区告诉我。
LeNet简介
我们在平时所说的LeNet一般都指的是LeNet-5,出自论文Gradient-Based Learning Applied to Document Recognition,LeNet-5网络非常适合于手写数字的识别,比较熟悉LeNet-5网络的话可以直接跳入下一节。
下图是LeNet-5的网络结构。
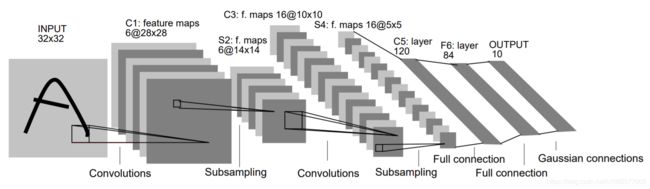
该网络包含7层(输入层不算入层数),由两个卷积层,两个池化层,三个全连接层组成。
第一层,卷积层
这一层的输入就是原始图像的像素,在论文中,LeNet模型接受的输入层大小为32 * 32 * 1,卷积层过滤器的尺寸为5 * 5,深度为6,步长为1,所以这一层的输出尺寸为32 - 5 + 1 = 28,同时采用ReLu函数作为激活函数。
第二层,池化层
这一层的输入为第一层的输出,输入尺寸为28 * 28 * 6,池化层采用的过滤器大小为2 * 2,长和宽的步长均为2 * 2,采用最大池化的方式,所以本层的输出尺寸为14 * 14 * 6。
第三层,卷积层
这一层输入尺寸为14 * 14 * 6,过滤器尺寸为5 * 5,深度为16,步长为1,所以这一层的输出尺寸为14 - 5 + 1 = 10,同时采用ReLu函数作为激活函数。
第四层,池化层
本层的输入尺寸为10 * 10 * 16,其他参数与第二层保持一致,所以本层的输出尺寸为5 * 5 * 16。
第五层,全连接层
本层的输入尺寸为5 * 5 * 16,在全连接层,首先将输入矩阵拉成一个向量,这里将把输入转换成一个5 * 5 * 16维的向量,输出向量的维数为120,将输入向量与输出向量全连接,参数矩阵的尺寸为[5 * 5 * 16, 120]。
第六层,全连接层
本层输入向量维数为120,输出向量维数为84,将输入向量与输出向量全连接,参数矩阵的尺寸为[120, 84]。
第七层,全连接层
本层输入向量维数为84,输出向量维数为10,将输入与输出进行全连接,参数矩阵的尺寸为[84, 10]。最终输出是一个范围为[0, 1]的10维向量,依次代表0-9,取10个数中最大的值为预测结果。
代码实现
代码基于Pytorch框架实现,由三个文件model.py, train.py, test.py组成。
- model.py定义了LeNet-5网络结构。
- train.py用于训练。
- test.py用于测试,计算准确率。
使用MNIST数据集进行训练与测试,该数据集中包含60000张手写图片用于训练,10000张手写图片用于测试。
定义网络模型(model.py)
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 卷积层
# i --> input channels
# 6 --> output channels
# 5 --> kernel size
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接层
# 16 * 4 * 4 --> input vector dimensions
# 120 --> output vector dimensions
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 卷积 --> ReLu --> 池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), (2, 2))
# reshape, '-1'表示自适应
# x = (n * 16 * 4 * 4) --> n : input channels
# x.size()[0] == n --> input channels
x = x.view(x.size()[0], -1)
# 全连接层
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
- 在Pytorch中每定义一个网络模型都要继承nn.Module这个类,实现 __ init __ ,forward方法,并在 __ init __ 方法的第一行调用父类的__ init __方法。
- __ init __ 方法中定义了每一层的输入输出尺寸,forward方法就会使用到 __ init __中定义的层来拼接网络模型。
- 由于MNIST数据集中的图像尺寸为28 * 28 * 1,与论文中模型输入的尺寸不一致,所以需要适当修改一些参数,将fc1的输入向量维数改成16 * 4 * 4即可。
训练(train.py)
import torchvision as tv
import torchvision.transforms as transforms
import torch
import torch.nn as nn
from torch import optim
from torch.utils.data import DataLoader
from torch.autograd import Variable
from model import Net
if __name__ == '__main__':
# 定义对数据的预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转换为Tensor,并归一化至[0, 1]
])
# 训练集
trainset = tv.datasets.MNIST(
root='data/',
train=True,
download=True,
transform=transform
)
trainloader = DataLoader(
dataset=trainset,
batch_size=4,
shuffle=True
)
# MNIST数据集中的十种标签
classes = ('0', '1', '2', '3', '4',
'5', '6', '7', '8', '9')
# 创建网络模型
net = Net()
if torch.cuda.is_available():
# 使用GPU
net.cuda()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.005, momentum=0.9)
for epoch in range(5):
running_loss = 0.0
for i, data in enumerate(trainloader):
# 输入数据
inputs, labels = data
if torch.cuda.is_available():
inputs = inputs.cuda()
labels = labels.cuda()
inputs, labels = Variable(inputs), Variable(labels)
# 梯度清0
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
# 更新参数
optimizer.step()
# 打印log信息
running_loss += loss.item()
# 每2000个batch打印一次训练状态
if i % 100 == 99:
print('[{}/{}][{}/{}] loss: {:.3f}'.format(epoch + 1, 5, (i + 1) * 4, len(trainset), running_loss / 100))
running_loss = 0.0
# 保存参数文件
torch.save(net.state_dict(), 'checkpoints/model_{}.pth'.format(epoch + 1))
print('model_{}.pth saved'.format(epoch + 1))
print('Finished Training')
打印结果
[1/5][400/60000] loss: 2.303
[1/5][800/60000] loss: 2.261
[1/5][1200/60000] loss: 1.767
[1/5][1600/60000] loss: 0.909
[1/5][2000/60000] loss: 0.724
[1/5][2400/60000] loss: 0.506
[1/5][2800/60000] loss: 0.524
[1/5][3200/60000] loss: 0.472
[1/5][3600/60000] loss: 0.452
...
...
...
[5/5][56800/60000] loss: 0.048
[5/5][57200/60000] loss: 0.025
[5/5][57600/60000] loss: 0.037
[5/5][58000/60000] loss: 0.037
[5/5][58400/60000] loss: 0.062
[5/5][58800/60000] loss: 0.021
[5/5][59200/60000] loss: 0.011
[5/5][59600/60000] loss: 0.004
[5/5][60000/60000] loss: 0.040
测试(test.py)
import torchvision as tv
import torchvision.transforms as transforms
import torch
from torch.utils.data import DataLoader
from torch.autograd import Variable
from model import Net
def get_dataset():
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor()
])
# 测试集
testset = tv.datasets.MNIST(
root='data/',
train=False,
download=False,
transform=transform,
)
testloadter = DataLoader(
dataset = testset,
batch_size = 4,
shuffle = True,
)
return len(testset), testloadter
def main():
# 数字类别
classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9')
# 初始化网络参数
model = Net()
# 加载模型
model.load_state_dict(torch.load('checkpoints/model_5.pth'))
if torch.cuda.is_available():
# 使用GPU
model.cuda()
# get dataloader
data_len, dataloader = get_dataset()
# 预测正确的个数
correct_num = 0
for i, data in enumerate(dataloader):
inputs, labels = data
if torch.cuda.is_available():
inputs = inputs.cuda()
labels = labels.cuda()
inputs, labels = Variable(inputs), Variable(labels)
outputs = model(inputs)
# 取最大值为预测结果
_, predicted = torch.max(outputs, 1)
for j in range(len(predicted)):
predicted_num = predicted[j].item()
label_num = labels[j].item()
# 预测值与标签值进行比较
if predicted_num == label_num:
correct_num += 1
# 计算预测准确率
correct_rate = correct_num / data_len
print('correct rate is {:.3f}%'.format(correct_rate * 100))
if __name__ == "__main__":
main()
运行代码,测试准确率
correct rate is 98.360%
总结
LeNet-5
- 一共有七层,两个卷积层,两个池化层,三个全连接层。
- 卷积层和前两层全连接层都要使用ReLu来作为激活函数。
- 特别适合用于手写数字识别。
训练步骤
- 定义网络模型。
- 对数据进上行预处理(transforms)。
- 使用DataLoader加载数据集。
- 初始化模型。
- 定义损失函数与优化器。
- 迭代训练,获得每一次迭代时的输入数据(inputs)与标签数据(labels)。
- 梯度清0,将输入数据前向传播得到预测数据,和标签数据一起计算loss,将loss反向传播更新参数。
- 打印训练状态。