Apache HBase的现状和展望
本文来自于2018-09-15在深圳举办第五次HBase Meetup会议,分享嘉宾杨文龙,阿里巴巴技术专家。HBase社区Committer,Ali-HBase内核负责人,对分布式存储系统的设计、实践具备丰富的大规模生产的经验。
备注:历届HBase Meetup会议的PPT: http://hbase.group/slides/
本文PPT下载地址:http://hbase.group/slides/86
HBase基本概念
HBase(Hadoop Database),是一个基于Google BigTable论文设计的高可靠性、高性能、可伸缩的分布式存储系统。
松散表结构(Schema free)
原生海量数据分布式存储
随机查询、范围查询
高吞吐,低延迟
在线NOSQL数据库
多版本,增量导入、多维删除
HBase的四大基因
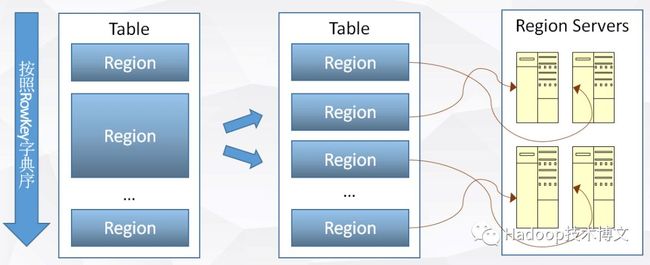
1.自动分区
数据分片
分区自动分裂
分区在线Merge
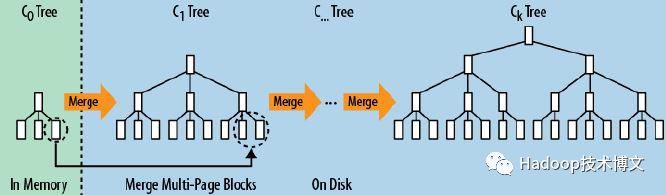
2.LSM-Tree
LSM (Log Structured Merge) Tree
HBase/Level DB/RocksDB
随机写 -> 顺序写
LSM特点
写吞吐高
不受HDD随机写瓶颈和SSD随机写入放大干扰
超强数据导入能力(相对B+Tree)
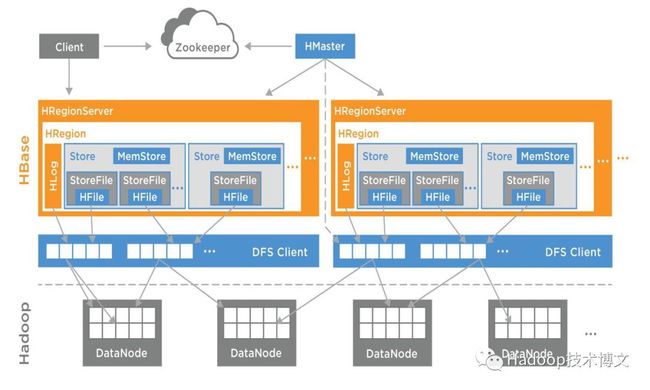
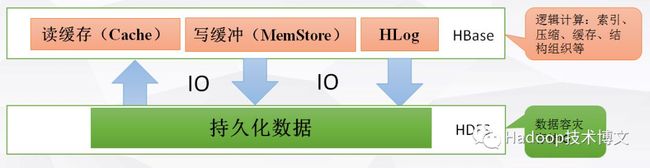
3.存储计算分离
负载均衡更高效
资源扩容更节省
存储优化更便捷
非对称副本冗余:异构介质、ErasureCode等
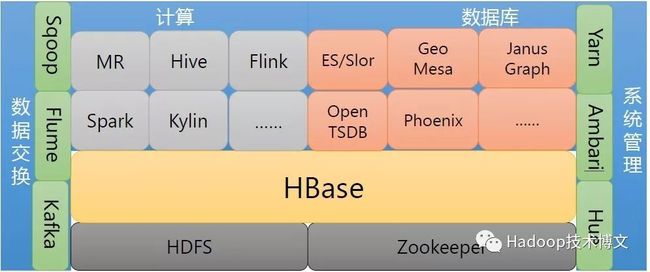
4.HBase生态
HBase特性总结
HBase,为大数据而生
(1)LSM树
离线导入效率巨高
实时写入吞吐大
增量导入隔离性强
(2)伸缩性强
(3)TTL
因大而生
时效性的个性化设置
(4)多版本
数据的第三维度
高效删除方式
动态列
数据发散的利器
协处理器
数据校正
高效适应个性化
异构介质多副本存储
海量与实时的性价比满足
Erasure Code
因大而生
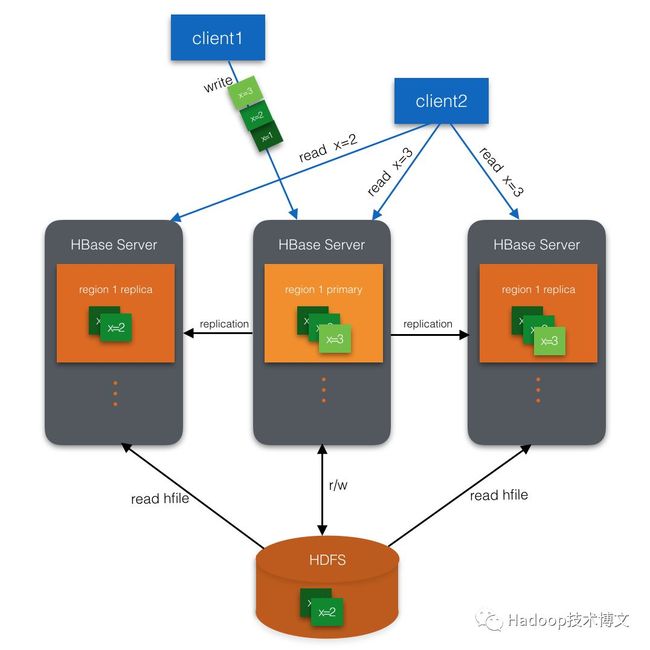
HBase2.0新功能:Region Replica
在CAP理论中,HBase一直是一个CP系统,遵循强一致的读写语义。
Server宕机后需要一定的恢复时间
为数据分片Region准备多个副本,host在不同的RegionServer上,称为Region Replica
提供高可用读,宕机0影响,规避抖动,毛刺,降低P999延迟
高可用读遵循最终一致性协议
需要额外耗费CPU/Memory资源,但不会占用额外空间
HBase2.0新功能:读写链路Off-heap
读写链路数据端到端Off-heap,减少java GC带来的停顿,进一
步降低P999延迟,提高吞吐。
写链路 Off-heap:
在RPC层使用Netty的Off-heap ByteBuffer
使用支持Off-heap的Protobuf
使用Off-heap的Chunk 来存储Memstore中的KeyValue
读链路 Off-heap:
使用Off-heap的Bucket Cache
对Bucket Cache进行引用计数,读取时不再需要先拷贝到heap
对Bucket Cache进行了一系列性能优化
HBase2.0新功能:读写链路Off-heap
Offheap Read-Path in Production - The Alibaba story
https://blogs.apache.org/hbase/entry/offheap-read-path-in-production
HBase2.0新功能:In Memory Compaction
把Memstore使用的ConcurrentSkipListMap 在内存中flush成更加紧凑的CellArrayMap
多个CellArrayMap会在内存中做compaction,使内存的使用更加紧凑
通过In memory的flush和compaction,在内存中可以存储更多的数据,因此可以提高读性能,同时减少磁盘IO,减轻compaction小文件造成的写放大
HBase2.0新功能:小对象存储MOB
MOB(Moderate Object Storage) 功能使HBase能高效地存储那些100k~10M 中等大小的对象。这使得用户可以把文档、图片对象保存到HBase系统中
用户写入的小对象flush成一个独立文件,原有的KV中的value只存这个对象的引用路径
对于存储对象文件,更少地进行compaction来减少写入放大效应
HBase2.0新功能:Assignment MangerV2
旧AM系统参与角色多,状态更新混乱,效率低,无事务保证,容易出现RIT问题
AM V2使用ProcedureV2来保证 Table/Region状态转换在master重启后仍然能恢复执行旧AM中Region变化的过程
AM V2中去除了Zookeeper做为中间角色,Master/RegionServer直接交互,Region assign/unassgin速度大大提升
解读文章:https://yq.aliyun.com/articles/601096
HBase2.0新功能:其他
使用Netty替代原有的RPC框架
提供原生Async客户端
Async WAL(WAL并发写三副本)
更完善的Quota机制
Region Server Group
依赖升级
Guava 0.12 => 0.22
Protobuf 2.5 => 3.3
所有的三方依赖都做了shade,防止和应用依赖冲突
HBase2.0中共提交了3000多个Issue(包含bugfix)
兼容性和升级建议
HBase-1.x的客户端都可以直接读写HBase2.0的集群
HBase-1.x的集群可以和HBase2.0的集群进行双向的Replication
由于AMv2变化较大,HBase-1.x中的部分DML/Admin操作可能不兼容
HBase-1.x中的Endpoint Coprocessor 可以在HBase2.0中直接工作
由于Coprocessor的接口发生变化,Observer Coprocessor需要重写
HBase-1.x Rolling Update to HBase2.0的方案社区还在试验中(不建议滚动级)
HBase2.x仍然在快速演进中,目前已经发布2.0.2版本和2.1.0版本,
目前HBCK不可用,针对HBase2.0的HBCK2还在研发中
HBase未来规划
1.更加易用
提供Native的SQL接口
轻量级的SQL支持:
Something like CQL(Apache Calcite, Presto, Apache Derby?)
内置的二级索引方案(与ProcedureV2结合?)
与Spark SQL更好地结合
Phoenix:
提供一个轻量级的Phoenix内置在HBase中?
2.更高性能
目标成为LSM模型下性能最好的Java存储引擎!
Use CCSMap to improve HBase YGC time
(https://yq.aliyun.com/video/play/1547)
全链路异步化
异步客户端(已有)
服务器端SEDA模型的request处理模式
Async HDFS client
基于非易失存储的WALLess方案
(https://yq.aliyun.com/video/play/1548)
Ratis LogService backed WALs
(https://issues.apache.org/jira/browse/HBASE-20951)
3.更强扩展性和稳定性
可分裂的Meta Table
基于新框架实现Distributed Log Replay
Hybrid Logical Clocks(类似Spanner的TrueTime)
Externalized Compaction
Become a Committer
1.关注社区发展
Apache HBase官方网站:
https://hbase.apache.org/
Apache HBase官方博客:
https://blogs.apache.org/hbase
订阅HBase的Issue
问题讨论邮件地址
中文社区网站
http://hbase.group/
2.Become a Contributor
为社区贡献代码的两种途径:
将发现的问题和新功能回馈给社区(Create a Issue)
Take over别人开的Issue
具体参考:
https://hbase.apache.org/book.html#developer
3.Become a Committer
“There is no single path to becoming a committer, nor any expected timeline.Submitting features, improvements, and bug fixes is the most common avenue, but other methods are both recognized and encouraged.”
提交新功能,改进,bugfix
补充文档,增加user case, best practice
保持Build稳定,增加测试case
积极参与mailing list中的讨论
积极帮助别人解决问题
Review别人的代码,提出意见
帮助其他产品与HBase融合
……
只要你为社区做出一定贡献,无论是何种贡献,就会有社区的PMC给你发邮件,问你是否愿意成为Committer
附上Apache HBase的现状和发展PPT:
备注:历届HBase Meetup会议的PPT: http://hbase.group/slides/
下面是完整的PPT资料(本文PPT下载地址:http://hbase.group/slides/86):




欢迎关注本公众号:iteblog_hadoop:
回复 spark_summit_201806 下载 Spark Summit North America 201806 全部PPT
0、回复 电子书 获取 本站所有可下载的电子书
1、Apache Spark 统一内存管理模型详解
2、Elasticsearch 6.3 发布,你们要的 SQL 功能来了
3、Spark Summit North America 201806 全部PPT下载[共147个]
4、干货 | 深入理解 Spark Structured Streaming
5、Apache Spark 黑名单(Blacklist)机制介绍
6、Kafka分区分配策略(Partition Assignment Strategy)
7、Spark SQL 你需要知道的十件事
8、干货 | Apache Spark 2.0 作业优化技巧
9、[干货]大规模数据处理的演变(2003-2017)
10、干货 | 如何使用功能强大的 Apache Flink SQL
11、更多大数据文章欢迎访问https://www.iteblog.com及本公众号(iteblog_hadoop) 12、Flink中文文档: http://flink.iteblog.com 13、Carbondata 中文文档: http://carbondata.iteblog.com