java序列化机制和Serialize接口
java序列化机制 Serialize 接口
java本身的序列化机制存在问题:
1.序列化数据结果比较大,传输效率低
2.不能跨语言对接
XML编码格式的对象序列化机制成为主流
序列化机制:
MessagePack
Protocol Buffers
Dubbo、 kyro
恰当的序列化机制能够提高系统的通用性、强壮性、安全性、性能优化,能够让我们更加的异域调优和扩展。
把对象转化为字节序列的过程称之为序列化,反之是反序列化
怎么实现一个序列化操作
ObjectInputStream : 通过这个类进行序列化的操作
ObjectOutputStream : 通过这个类进行反序列化的操作
SerialVersionUID 的作用: 相当于是对对象进行了一个摘要算法,如果不加入这个SerialVersionUID的话编译器在编译的时候会自动的给我们生成一个SerialVersionUID,使用SerialVersionUID保证序列化和反序列化的对象是同一个
静态变量的序列化:
来,我们看下这个例子:
package com.testserialize;
import java.io.*;
public class SerializerDemo {
public static void main(String[] args) throws Exception {
///先执行序列化的操作
SerializePerson();
//把静态变量设置上值
Person.height = 3;
//进行反序列化的操作
Person p = DeSerializePerson();
//结果发现静态变量没有被序列化,不是原来在类当中定义的2
/*
结论:序列化并不保存静态变量的状态
*/
System.out.println( p.getHeight() );
}
//
private static void SerializePerson() throws Exception {
ObjectOutputStream oo = new ObjectOutputStream(new FileOutputStream(new File("person")));
Person person = new Person();
person.setAge(18);
person.setName("mic");
oo.writeObject(person);
System.out.println("序列化成功");
oo.close();
}
private static Person DeSerializePerson() throws Exception {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("person")));
Person obj = (Person) ois.readObject();
// System.out.println( obj );
return obj;
}
}
class Person{
private static final long serialVersionUID = -374834738493L;
public static int height = 2;
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getHeight() {
return height;
}
public void setHeight(int height) {
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}根据上面的代码可以看出静态变量是不参与的序列化的过程当中的
Transient关键字:
这个关键字在序列化的时候不参与到序 列化的过程中,上面例子中可以将 Person类的name属性加上这个关键字进行验证。
这里有一个需要注意的关键点是当自父类继承关系的时候在序列化的时候一定要把父类对象也加上 Serializer接口
如果父类没有实现序列化,子类实现了,那么父类的成员没办法实现序列化操作。
序列化的存储规则:
浅克隆:只复制对象,不复制引用
深克隆:复制对象复制引用
总结:
1.在java当中,只要一个类实现了 java.io.Serializable 这个接口,那么它就可以被序列化
2.通过ObjectOutputStream 和 ObjectInputStream 可以对对象进行序列化和反序列化的操作
3.虚拟机是否允许被反序列化,不仅仅取决于对象代码是否一致,还有一个因素是 UID
4.序列化不保存静态变量
5.要想父类对象也参与序列化操作,那么必须让父类也实现Serializable接口。
6.Transient关键字,主要是控制变量是否能被序列化,没有被序列化的成员变量被反序列化之后会被设置成初始值。
7.通过序列化操作实现深度克隆
主流的序列化技术有哪些?
JSON、Hessian2、xml、protobuf、kyro、MsgPack、FST、thrift、protustuff、Avro
1、JSON的序列化机制:
首先需要在pom.xml文件中导入下面的包
org.codehaus.jackson
jackson-mapper-asl
1.9.13
编写程序测试 JSON的序列化:
package com.myserializable;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.testserialize.Person;
public class JsonDemo {
private static Person init() {
Person person = new Person();
person.setName("mic");
person.setAge(18);
return person;
}
public static void main(String[] args) throws Exception {
Person p = init();
executeWithJack();
}
//测试循环100次执行JSON序列化所需要消耗的时间
private static void executeWithJack() throws Exception {
Person p = init();
ObjectMapper mapper = new ObjectMapper();
byte[] writeBytes = null;
long start = System.currentTimeMillis();
for(int i=0;i<100;i++){
writeBytes = mapper.writeValueAsBytes(p);
}
System.out.println("Json序列化:"+(System.currentTimeMillis()-start)+"ms 序列化之后的总大小是这个:"+writeBytes.length);
Person person1 = mapper.readValue( writeBytes, Person.class);
System.out.println(person1);
}
}
class Person{
private static final long serialVersionUID = -374834738493L;
public static int height = 2;
private transient String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getHeight() {
return height;
}
public void setHeight(int height) {
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}输出:
编写测试程序 FastJSON 的序列化:
com.alibaba
fastjson
1.2.49
程序改成下面的:
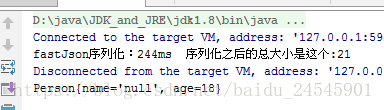
//测试循环100次执行FastJSON序列化所需要消耗的时间
private static void executeWithFastJson() throws Exception {
Person p = init();
String text = null;
long start = System.currentTimeMillis();
for(int i=0;i<100;i++){
text = JSON.toJSONString(p);
}
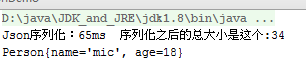
System.out.println("fastJson序列化:"+(System.currentTimeMillis()-start)+"ms 序列化之后的总大小是这个:"+text.length());
Person p1 = JSON.parseObject(text,Person.class);
System.out.println(p1);
}输出结果:
3、Protobuffer 序列化(google传输协议,用于结构化数据序列化,数据存储,rpc数据交换,语言平台无关跨语言)
导入下面的 pom:
com.baidu
jprotobuf
2.1.2
能够跨语言的序列化 除了上面的 fst、kyro不支持跨语言其他都跨语言
要使用 Protobuf需要在要序列化的类的字段上面定义下面的注解:
@protobuf(fieldType=FieldType.STRING)
代码调用如下:
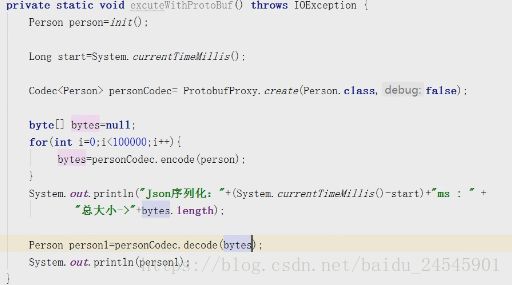
Protobuf的优势:字节数少,非常适合网络传输
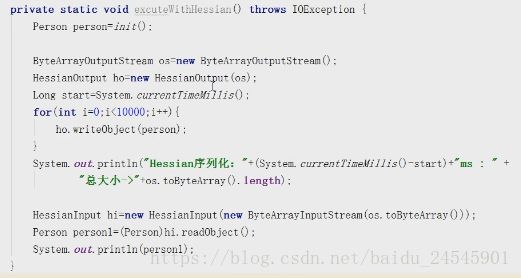
hessian的序列化方式
导入pom
com.caucho
hessian
4.0.51