spark ml实现逻辑回归案例分析
一、spark ml介绍
spark ml对机器学习算法的api进行了标准化,使将多个算法合并到一个管道或工作流变得更容易。为了更清楚了解,从以下及几个方面展开说明。
DataFrame:这个ML API使用Spark SQL的DataFrame作为ML数据集,它可以容纳各种数据类型。例如,DataFrame可能有不同的列存储文本、特征向量、真实标签和预测。
Transformer: Transformer是一种可以将一个DataFrame转换成另一个DataFrame的算法。例如,ML模型是一个转换器,它将具有特性的DataFrame转换为具有预测的DataFrame。
Estimator:估计器是一种算法,用于DataFrame转换。例如,学习算法是一种估计器,它训练一个DataFrame并生成一个模型。
pipeline:管道将多个变压器和估计器链接在一起,以指定一个ML工作流。
二、spark ml实现
尝试用spark ml实现广告点击预测,训练和测试数据使用Kaggle Avazu CTR 比赛的样例数据,下载地址:https://www.kaggle.com/c/avazu-ctr-prediction/data。
开发环境:java1.8.0_172+scala2.11.8+spark2.3.1
依赖包
org.apache.spark
spark-core_2.11
2.3.1
org.apache.spark
spark-sql_2.11
2.3.1
org.apache.spark
spark-hive_2.11
2.3.1
org.apache.spark
spark-mllib_2.11
2.3.1
1. 数据集
spark加载csv文件,dataframe基本结构如下:
val data = spark.read.csv("/opt/data/ads_6M.csv").toDF(
"id","click","hour","C1","banner_pos","site_id","site_domain",
"site_category","app_id","app_domain","app_category","device_id","device_ip",
"device_model","device_type","device_conn_type","C14","C15","C16","C17","C18",
"C19","C20","C21")
data.show(5,false)+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+---+------+---+
|id |click|hour |C1 |banner_pos|site_id |site_domain|site_category|app_id |app_domain|app_category|device_id|device_ip|device_model|device_type|device_conn_type|C14 |C15|C16|C17 |C18|C19|C20 |C21|
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+---+------+---+
|10153523536315735769|0 |14102100|1005|0 |85f751fd|c4e18dd6 |50e219e0 |53de0284|d9b5648e |0f2161f8 |a99f214a |788c3e75 |2ea4f8ba |1 |0 |20508|320|50 |2351|3 |163|-1 |61 |
|10448041871517116234|0 |14102100|1005|0 |1fbe01fe|f3845767 |28905ebd |ecad2386|7801e8d9 |07d7df22 |a99f214a |99cd8fa2 |81b42528 |1 |0 |15707|320|50 |1722|0 |35 |-1 |79 |
|10488488220071431784|0 |14102100|1005|1 |72a56356|45368af7 |3e814130 |ecad2386|7801e8d9 |07d7df22 |a99f214a |e8fc2f9f |900981af |1 |2 |18993|320|50 |2161|0 |35 |-1 |157|
|10625948582770087788|0 |14102100|1005|0 |85f751fd|c4e18dd6 |50e219e0 |5e3f096f|2347f47a |0f2161f8 |a99f214a |9c1b8be7 |24f6b932 |1 |0 |18993|320|50 |2161|0 |35 |100215|157|
|11151072182888929242|0 |14102100|1005|1 |5b4d2eda|16a36ef3 |f028772b |ecad2386|7801e8d9 |07d7df22 |a99f214a |866e0a54 |d787e91b |1 |0 |16208|320|50 |1800|3 |167|-1 |23 |
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+---+------+---+
包含24个字段:
- 1-id: ad identifier
- 2-click: 0/1 for non-click/click
- 3-hour: format is YYMMDDHH, so 14091123 means 23:00 on Sept. 11, 2014 UTC.
- 4-C1 — anonymized categorical variable
- 5-banner_pos
- 6-site_id
- 7-site_domain
- 8-site_category
- 9-app_id
- 10-app_domain
- 11-app_category
- 12-device_id
- 13-device_ip
- 14-device_model
- 15-device_type
- 16-device_conn_type
- 17~24—C14-C21 — anonymized categorical variables
其中5到15列为分类特征,16~24列为数值型特征。将数据集分为训练集和测试集,比例为0.7:0.3。
val splited = data.randomSplit(Array(0.7,0.3),2L)2. 特征处理
2.1 StringIndexer
对于分类特征可以使用StringIndexer将标签的字符串列编码为标签索引列,将字符串特征转化为数值特征,便于下游管道组件处理。
val catalog_features = Array("click","site_id","site_domain","site_category","app_id","app_domain","app_category","device_id","device_ip","device_model")
var train_index = splited(0)
var test_index = splited(1)
for(catalog_feature <- catalog_features){
val indexer = new StringIndexer()
.setInputCol(catalog_feature)
.setOutputCol(catalog_feature.concat("_index"))
val train_index_model = indexer.fit(train_index)
val train_indexed = train_index_model.transform(train_index)
val test_indexed = indexer.fit(test_index).transform(test_index,train_index_model.extractParamMap())
train_index = train_indexed
test_index = test_indexed
}
println("字符串编码下标标签:")
train_index.show(5,false)
test_index.show(5,false)字符串编码下标标签:
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+----+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
|id |click|hour |C1 |banner_pos|site_id |site_domain|site_category|app_id |app_domain|app_category|device_id|device_ip|device_model|device_type|device_conn_type|C14 |C15|C16|C17 |C18|C19 |C20 |C21|click_index|site_id_index|site_domain_index|site_category_index|app_id_index|app_domain_index|app_category_index|device_id_index|device_ip_index|device_model_index|
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+----+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
|10000133892746881176|0 |14102813|1005|0 |85f751fd|c4e18dd6 |50e219e0 |febd1138|82e27996 |0f2161f8 |a99f214a |f5c62586 |b4b19c97 |1 |0 |21611|320|50 |2480|3 |297 |100111|61 |0.0 |0.0 |0.0 |0.0 |4.0 |4.0 |1.0 |0.0 |23751.0 |64.0 |
|10000987464039884177|0 |14102816|1005|0 |5bcf81a2|9d54950b |f028772b |ecad2386|7801e8d9 |07d7df22 |a99f214a |845f69f4 |fa61e8fe |1 |0 |23438|320|50 |2684|2 |1319|-1 |52 |0.0 |11.0 |7.0 |1.0 |0.0 |0.0 |0.0 |0.0 |5237.0 |67.0 |
|10001055656394300907|0 |14102814|1005|0 |85f751fd|c4e18dd6 |50e219e0 |e9739828|df32afa9 |cef3e649 |a99f214a |6454c6ba |ecb851b2 |1 |0 |23441|320|50 |2685|1 |33 |100083|212|0.0 |0.0 |0.0 |0.0 |13.0 |11.0 |2.0 |0.0 |18147.0 |8.0 |
|10001237608243220141|0 |14102701|1005|0 |85f751fd|c4e18dd6 |50e219e0 |febd1138|82e27996 |0f2161f8 |a99f214a |ab986e15 |2ea4f8ba |1 |0 |19743|320|50 |2264|3 |427 |100000|61 |0.0 |0.0 |0.0 |0.0 |4.0 |4.0 |1.0 |0.0 |23941.0 |34.0 |
|10001363001408225332|0 |14102812|1005|1 |85f751fd|c4e18dd6 |50e219e0 |1dc72b4d|2347f47a |0f2161f8 |b7c2e4b6 |bce45090 |5db079b5 |1 |2 |22998|300|50 |2657|3 |35 |100013|23 |0.0 |0.0 |0.0 |0.0 |25.0 |1.0 |1.0 |1760.0 |729.0 |25.0 |
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+----+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
only showing top 5 rows
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+---+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
|id |click|hour |C1 |banner_pos|site_id |site_domain|site_category|app_id |app_domain|app_category|device_id|device_ip|device_model|device_type|device_conn_type|C14 |C15|C16|C17 |C18|C19|C20 |C21|click_index|site_id_index|site_domain_index|site_category_index|app_id_index|app_domain_index|app_category_index|device_id_index|device_ip_index|device_model_index|
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+---+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
|10002333262420133303|0 |14102211|1005|1 |856e6d3f|58a89a43 |f028772b |ecad2386|7801e8d9 |07d7df22 |a99f214a |ac322dfb |0dc22ebc |1 |0 |19771|320|50 |2227|0 |679|100077|48 |0.0 |6.0 |6.0 |1.0 |0.0 |0.0 |0.0 |0.0 |6004.0 |279.0 |
|10002749335348787004|1 |14102800|1005|0 |2a68aa20|9b851bd8 |3e814130 |ecad2386|7801e8d9 |07d7df22 |a99f214a |b4a0ec64 |49bc419a |1 |0 |20213|320|50 |2316|0 |167|100079|16 |1.0 |57.0 |56.0 |3.0 |0.0 |0.0 |0.0 |0.0 |30.0 |563.0 |
|10003763177308262205|0 |14102814|1002|0 |7971d583|c4e18dd6 |50e219e0 |ecad2386|7801e8d9 |07d7df22 |fffcf8a4 |f615f762 |a5df7413 |0 |0 |23441|320|50 |2685|1 |33 |-1 |212|0.0 |408.0 |0.0 |0.0 |0.0 |0.0 |0.0 |1003.0 |5471.0 |982.0 |
|10005435104591133943|0 |14102719|1005|0 |85f751fd|c4e18dd6 |50e219e0 |92f5800b|ae637522 |0f2161f8 |a99f214a |8f2784a2 |0bcabeaf |1 |3 |21189|320|50 |2424|1 |161|100193|71 |0.0 |0.0 |0.0 |0.0 |1.0 |2.0 |1.0 |0.0 |4207.0 |19.0 |
|10006076676750034840|0 |14102522|1005|1 |e151e245|7e091613 |f028772b |ecad2386|7801e8d9 |07d7df22 |a99f214a |dc88197f |fce66524 |1 |0 |4687 |320|50 |423 |2 |39 |100148|32 |0.0 |2.0 |2.0 |1.0 |0.0 |0.0 |0.0 |0.0 |4109.0 |22.0 |
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+---+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
only showing top 5 rows
2.2 FeatureHasher
特征哈希将一组分类或数值特征投射到指定维的特征向量(通常比原始特征空间小很多)。这是使用哈希技巧将特征映射到特征向量中的索引。
val hasher = new FeatureHasher()
.setInputCols("site_id_index","site_domain_index","site_category_index","app_id_index","app_domain_index","app_category_index","device_id_index","device_ip_index","device_model_index","device_type","device_conn_type","C14","C15","C16","C17","C18","C19","C20","C21")
.setOutputCol("feature")
val train_hs = hasher.transform(train_index)
val test_hs = hasher.transform(test_index)
println("特征Hasher编码:")
train_index.show(5,false)
test_index.show(5,false)特征Hasher编码:
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+----+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
|id |click|hour |C1 |banner_pos|site_id |site_domain|site_category|app_id |app_domain|app_category|device_id|device_ip|device_model|device_type|device_conn_type|C14 |C15|C16|C17 |C18|C19 |C20 |C21|click_index|site_id_index|site_domain_index|site_category_index|app_id_index|app_domain_index|app_category_index|device_id_index|device_ip_index|device_model_index|
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+----+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
|10000133892746881176|0 |14102813|1005|0 |85f751fd|c4e18dd6 |50e219e0 |febd1138|82e27996 |0f2161f8 |a99f214a |f5c62586 |b4b19c97 |1 |0 |21611|320|50 |2480|3 |297 |100111|61 |0.0 |0.0 |0.0 |0.0 |4.0 |4.0 |1.0 |0.0 |23751.0 |64.0 |
|10000987464039884177|0 |14102816|1005|0 |5bcf81a2|9d54950b |f028772b |ecad2386|7801e8d9 |07d7df22 |a99f214a |845f69f4 |fa61e8fe |1 |0 |23438|320|50 |2684|2 |1319|-1 |52 |0.0 |11.0 |7.0 |1.0 |0.0 |0.0 |0.0 |0.0 |5237.0 |67.0 |
|10001055656394300907|0 |14102814|1005|0 |85f751fd|c4e18dd6 |50e219e0 |e9739828|df32afa9 |cef3e649 |a99f214a |6454c6ba |ecb851b2 |1 |0 |23441|320|50 |2685|1 |33 |100083|212|0.0 |0.0 |0.0 |0.0 |13.0 |11.0 |2.0 |0.0 |18147.0 |8.0 |
|10001237608243220141|0 |14102701|1005|0 |85f751fd|c4e18dd6 |50e219e0 |febd1138|82e27996 |0f2161f8 |a99f214a |ab986e15 |2ea4f8ba |1 |0 |19743|320|50 |2264|3 |427 |100000|61 |0.0 |0.0 |0.0 |0.0 |4.0 |4.0 |1.0 |0.0 |23941.0 |34.0 |
|10001363001408225332|0 |14102812|1005|1 |85f751fd|c4e18dd6 |50e219e0 |1dc72b4d|2347f47a |0f2161f8 |b7c2e4b6 |bce45090 |5db079b5 |1 |2 |22998|300|50 |2657|3 |35 |100013|23 |0.0 |0.0 |0.0 |0.0 |25.0 |1.0 |1.0 |1760.0 |729.0 |25.0 |
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+----+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
only showing top 5 rows
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+---+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
|id |click|hour |C1 |banner_pos|site_id |site_domain|site_category|app_id |app_domain|app_category|device_id|device_ip|device_model|device_type|device_conn_type|C14 |C15|C16|C17 |C18|C19|C20 |C21|click_index|site_id_index|site_domain_index|site_category_index|app_id_index|app_domain_index|app_category_index|device_id_index|device_ip_index|device_model_index|
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+---+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
|10002333262420133303|0 |14102211|1005|1 |856e6d3f|58a89a43 |f028772b |ecad2386|7801e8d9 |07d7df22 |a99f214a |ac322dfb |0dc22ebc |1 |0 |19771|320|50 |2227|0 |679|100077|48 |0.0 |6.0 |6.0 |1.0 |0.0 |0.0 |0.0 |0.0 |6004.0 |279.0 |
|10002749335348787004|1 |14102800|1005|0 |2a68aa20|9b851bd8 |3e814130 |ecad2386|7801e8d9 |07d7df22 |a99f214a |b4a0ec64 |49bc419a |1 |0 |20213|320|50 |2316|0 |167|100079|16 |1.0 |57.0 |56.0 |3.0 |0.0 |0.0 |0.0 |0.0 |30.0 |563.0 |
|10003763177308262205|0 |14102814|1002|0 |7971d583|c4e18dd6 |50e219e0 |ecad2386|7801e8d9 |07d7df22 |fffcf8a4 |f615f762 |a5df7413 |0 |0 |23441|320|50 |2685|1 |33 |-1 |212|0.0 |408.0 |0.0 |0.0 |0.0 |0.0 |0.0 |1003.0 |5471.0 |982.0 |
|10005435104591133943|0 |14102719|1005|0 |85f751fd|c4e18dd6 |50e219e0 |92f5800b|ae637522 |0f2161f8 |a99f214a |8f2784a2 |0bcabeaf |1 |3 |21189|320|50 |2424|1 |161|100193|71 |0.0 |0.0 |0.0 |0.0 |1.0 |2.0 |1.0 |0.0 |4207.0 |19.0 |
|10006076676750034840|0 |14102522|1005|1 |e151e245|7e091613 |f028772b |ecad2386|7801e8d9 |07d7df22 |a99f214a |dc88197f |fce66524 |1 |0 |4687 |320|50 |423 |2 |39 |100148|32 |0.0 |2.0 |2.0 |1.0 |0.0 |0.0 |0.0 |0.0 |4109.0 |22.0 |
+--------------------+-----+--------+----+----------+--------+-----------+-------------+--------+----------+------------+---------+---------+------------+-----------+----------------+-----+---+---+----+---+---+------+---+-----------+-------------+-----------------+-------------------+------------+----------------+------------------+---------------+---------------+------------------+
only showing top 5 rows
3. LR模型训练和预测
采用spark ml中LR模型,对广告点击进行预测。其中一些设置参数如下:
- setMaxIter设置最大迭代次数(默认100),具体迭代次数可能在不足最大迭代次数停止(见下一条)
- setTol设置容错(默认1e-6),每次迭代会计算一个误差,误差值随着迭代次数增加而减小,当误差小于设置容错,则停止迭代
- setRegParam设置正则化项系数(默认0),正则化主要用于防止过拟合现象,如果数据集较小,特征维数又多,易出现过拟合,考虑增大正则化系数
- setElasticNetParam正则化范式比(默认0),正则化有两种方式:L1(Lasso)和L2(Ridge),L1用于特征的稀疏化,L2用于防止过拟合
- setLabelCol设置标签列
- setFeaturesCol设置特征列
- setPredictionCol设置预测列
- setThreshold设置二分类阈值
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0)
.setFeaturesCol("feature")
.setLabelCol("click_index")
.setPredictionCol("click_predict")
val model_lr = lr.fit(train_hs)
println(s"每个特征对应系数: ${model_lr.coefficients} 截距: ${model_lr.intercept}")
val predictions = model_lr.transform(test_hs)
predictions.select("click_index","click_predict","probability").show(10,false)
val predictionRdd = predictions.select("click_predict","click_index").rdd.map{
case Row(click_predict:Double,click_index:Double)=>(click_predict,click_index)
}
val metrics = new MulticlassMetrics(predictionRdd)
val accuracy = metrics.accuracy
val weightedPrecision = metrics.weightedPrecision
val weightedRecall = metrics.weightedRecall
val f1 = metrics.weightedFMeasure
println(s"LR评估结果:\n分类正确率:${accuracy}\n加权正确率:${weightedPrecision}\n加权召回率:${weightedRecall}\nF1值:${f1}")+-----------+-------------+----------------------------------------+
|click_index|click_predict|probability |
+-----------+-------------+----------------------------------------+
|0.0 |0.0 |[0.8673583515173942,0.13264164848260582]|
|1.0 |0.0 |[0.7065355297971061,0.29346447020289396]|
|0.0 |0.0 |[0.9247213791421071,0.07527862085789287]|
|0.0 |0.0 |[0.9411799267286762,0.05882007327132381]|
|0.0 |0.0 |[0.7534455683444734,0.24655443165552665]|
|0.0 |0.0 |[0.8993737856386326,0.10062621436136741]|
|0.0 |0.0 |[0.8837461636081269,0.11625383639187312]|
|0.0 |0.0 |[0.8320314092251319,0.16796859077486806]|
|0.0 |0.0 |[0.9027137639161569,0.09728623608384318]|
|1.0 |0.0 |[0.8791816482313737,0.12081835176862625]|
+-----------+-------------+----------------------------------------+
only showing top 10 rows
LR评估结果:
分类正确率:0.8308678500986193
加权正确率:0.7886992955593048
加权召回率:0.8308678500986193
F1值:0.7596712330402737
三、总结
1. 流程回顾
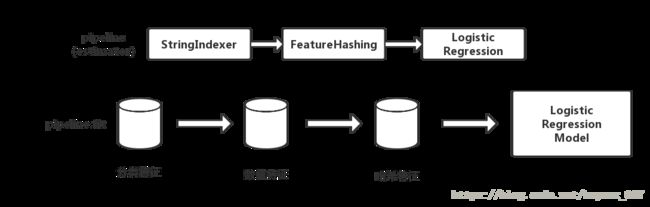
2.源码
object AdsCtrPredictionLR {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("AdsCtrPredictionLR")
.master("local[2]")
.config("spark.some.config.option", "some-value")
.getOrCreate()
/**
* id和click分别为广告的id和是否点击广告
* site_id,site_domain,site_category,app_id,app_domain,app_category,device_id,device_ip,device_model为分类特征,需要OneHot编码
* device_type,device_conn_type,C14,C15,C16,C17,C18,C19,C20,C21为数值特征,直接使用
*/
val data = spark.read.csv("/opt/data/ads_6M.csv").toDF(
"id","click","hour","C1","banner_pos","site_id","site_domain",
"site_category","app_id","app_domain","app_category","device_id","device_ip",
"device_model","device_type","device_conn_type","C14","C15","C16","C17","C18",
"C19","C20","C21")
data.show(5,false)
val splited = data.randomSplit(Array(0.7,0.3),2L)
val catalog_features = Array("click","site_id","site_domain","site_category","app_id","app_domain","app_category","device_id","device_ip","device_model")
var train_index = splited(0)
var test_index = splited(1)
for(catalog_feature <- catalog_features){
val indexer = new StringIndexer()
.setInputCol(catalog_feature)
.setOutputCol(catalog_feature.concat("_index"))
val train_index_model = indexer.fit(train_index)
val train_indexed = train_index_model.transform(train_index)
val test_indexed = indexer.fit(test_index).transform(test_index,train_index_model.extractParamMap())
train_index = train_indexed
test_index = test_indexed
}
println("字符串编码下标标签:")
train_index.show(5,false)
test_index.show(5,false)
// 特征Hasher
val hasher = new FeatureHasher()
.setInputCols("site_id_index","site_domain_index","site_category_index","app_id_index","app_domain_index","app_category_index","device_id_index","device_ip_index","device_model_index","device_type","device_conn_type","C14","C15","C16","C17","C18","C19","C20","C21")
.setOutputCol("feature")
println("特征Hasher编码:")
val train_hs = hasher.transform(train_index)
val test_hs = hasher.transform(test_index)
/**
* LR建模
* setMaxIter设置最大迭代次数(默认100),具体迭代次数可能在不足最大迭代次数停止(见下一条)
* setTol设置容错(默认1e-6),每次迭代会计算一个误差,误差值随着迭代次数增加而减小,当误差小于设置容错,则停止迭代
* setRegParam设置正则化项系数(默认0),正则化主要用于防止过拟合现象,如果数据集较小,特征维数又多,易出现过拟合,考虑增大正则化系数
* setElasticNetParam正则化范式比(默认0),正则化有两种方式:L1(Lasso)和L2(Ridge),L1用于特征的稀疏化,L2用于防止过拟合
* setLabelCol设置标签列
* setFeaturesCol设置特征列
* setPredictionCol设置预测列
* setThreshold设置二分类阈值
*/
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0)
.setFeaturesCol("feature")
.setLabelCol("click_index")
.setPredictionCol("click_predict")
val model_lr = lr.fit(train_hs)
println(s"每个特征对应系数: ${model_lr.coefficients} 截距: ${model_lr.intercept}")
val predictions = model_lr.transform(test_hs)
predictions.select("click_index","click_predict","probability").show(100,false)
val predictionRdd = predictions.select("click_predict","click_index").rdd.map{
case Row(click_predict:Double,click_index:Double)=>(click_predict,click_index)
}
val metrics = new MulticlassMetrics(predictionRdd)
val accuracy = metrics.accuracy
val weightedPrecision = metrics.weightedPrecision
val weightedRecall = metrics.weightedRecall
val f1 = metrics.weightedFMeasure
println(s"LR评估结果:\n分类正确率:${accuracy}\n加权正确率:${weightedPrecision}\n加权召回率:${weightedRecall}\nF1值:${f1}")
}
}参考文献
https://blog.csdn.net/xueqingdata/article/details/50578005
https://blog.csdn.net/yhao2014/article/details/60324939
http://spark.apache.org/docs/latest/ml-features.html
http://spark.apache.org/docs/latest/ml-classification-regression.html