java学习(一) -----Java代码编译和执行的过程
一、编译
Java代码编译和执行的整个过程包含了以下三个重要的机制:
- Java源码编译机制
- 类加载机制
- 类执行机制
Java源码编译机制
Java 源码编译由以下三个过程组成:
- 分析和输入到符号表
- 注解处理
- 语义分析和生成class文件
流程图如下所示:

最后生成的class文件由以下部分组成:
- 结构信息。包括class文件格式版本号及各部分的数量与大小的信息
- 元数据。对应于Java源码中声明与常量的信息。包含类/继承的超类/实现的接口的声明信息、域与方法声明信息和常量池
- 方法信息。对应Java源码中语句和表达式对应的信息。包含字节码、异常处理器表、求值栈与局部变量区大小、求值栈的类型记录、调试符号信息
二、加载
类加载机制
JVM的类加载是通过ClassLoader及其子类来完成的,类的层次关系和加载顺序可以由下图来描述:

1)Bootstrap ClassLoader
负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类,该路径不需要我们指定
2)Extension ClassLoader
负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包,该路径不需要我们指定
3)App ClassLoader
负责记载classpath中指定的jar包及目录中class,命令行可以通过-classpath 或者CLASSPATH环境变量来指定,IDE中可以在项目当前目录直接加入jar文件即可。
4)Custom ClassLoader
属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader
加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个classloader已加载就视为已加载此类,保证此类只所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
附:可参考《Java虚拟机原理图解》
class文件的基础结构 http://blog.csdn.net/luanlouis/article/details/39892027
class文件中的常量池讲解(上):http://blog.csdn.net/luanlouis/article/details/39960815
class文件中的常量池讲解(下):http://blog.csdn.net/luanlouis/article/details/40148053
三、执行
类执行机制JVM是基于栈的体系结构来执行class字节码的。线程创建后,都会产生程序计数器(PC)和栈(Stack),程序计数器存放下一条需要执行的指令在方法内的偏移量(建议看计算机内存管理)。
问题:接下来我们思考一下,在执行一个方法时,内存中的状态是什么样的。
理论:
1、JVM内存和其他系统的交互图如下 图1
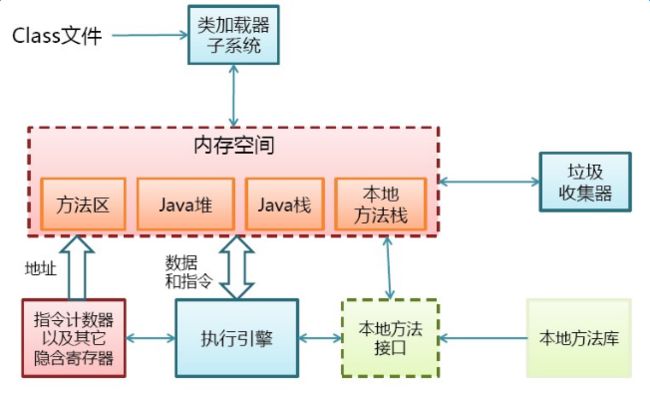
如下对java内存和Linux内存进行比对
java 堆 栈 方法区(class(类)信息,常量,静态变量) 程序计数器
Linux 堆 栈 (代码段,BSS段(Block Started by Symbol 全局未初始化的变量,属静态内存分配),数据段(全局初始化的变量,属静态内存分配))
2、对以上几个内存进行介绍
2.1 程序计数器
在JVM线程创建之后,都会产生PC,PC存放下一条需要执行的指令在方法内的偏移量,因为在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令,因此,为了线程切换后恢复到正确的执行位置,每条线程都需要有自己独立的程序计数器,所以PC是线程独享的。
2.2 java虚拟机栈
java虚拟机栈描述的是java方法执行(方法运行的过程产出)的内存模型。每个方法在运行的时候都会产生一个栈帧用于存储局部变量表,操作数栈,动态链接,方法出口等信息。这里我们主要关注的是局部变量表。
1、局部变量表的结构如下图:
局部变量表中存储了基本类型和对象的引用,基本类型中除了long和double占用了2个局部变量空间(slot)之外,其他类型都占用一个slot,对象引用占用一个slot。

2、局部变量表大小
局部变量表所需的内存空间在编译期已经确定,在运行期间局部变量表的大小不会变化
在JVM规范中,对于栈区域规定了两种异常,StackOverflowError(当栈深度大于JVM所允许的深度时抛出);OutOfMemoryError(无法申请到足够内存时抛出)
2.3 堆
对于大多数应用来说,java堆是JVM中内存最大的一块,堆是线程间共享的一块内存。其唯一的目的就是存放对象实现。所以该区域也是垃圾回收的重点区域,故从GC的角度可以将该区域分为新生代(Eden,From Survivor,To Survivor)和老年代。从内存的角度来看,可分出多个线程私有的分配缓存区(Thread Local Allocation Buffer,TLAB)。该区域定义的异常为OutOfMemoryError。
2.4 方法区
方法区定义为堆区的逻辑部分,当然同样也是线程共享的。方法区中存储着被JVM加载的类信息(个人理解就是Class文件信息),常量,静态变量(在考虑静态变量初始化时为什么只需初始化一次),编译的代码等数据。垃圾回收主要是常量和类型的卸载。该区域的异常被定义为OutOfMemoryError。
2.4.1 运行时常量
运行时常量属于方法区的一部分,存放的是class文件的常量池,除此之外还有一个特性,具备动态性,即常量是在运行时产生而非编译期产生,该特性被开发利用最多的而是String类的intern()方法(参考String的学习) 。
2.5 本地方法栈
本地方法栈和JVM栈的区别是后者为java方法服务,而前者是为Native方法服务。本地方法栈同样会抛出StackOverflowError和OutOfMemoryError异常。
3、通过对JVM的内存信息进行了解之后,我们来回答下之前提出的问题,程序是如何访问一个对象,访问一个方法的。
Student stu = new Student();
创建对象并访问该对象的过程如下
- 当创建类型为Student对象时,java解释器查找类路径,定位Student.class文件(根据classpath的目录下加载该类的class文件)
- 然后载入Student.class。
- 当new Student()创建对象的时候,首先在堆上为Student对象分配足够的内存空间(stu对象中的name 指针及其内容如何存放),这块空间会被清零,将stu对象中所以的属性都设置成了默认值,之后再执行其他初始化动作。
- 因为stu只是Student对象的引用,故要通过这个引用去访问真实的student对象。java虚拟机对reference类型只规定了指向对象的引用,ing没有定义通过什么方式去找到真实对象,目前有两种方式:句柄和指针,两个的不同点如下:句柄(对象移动,但reference本身不需要修改)和指针(访问速度快):


参考:《Java编程思想》 《深入理解Java虚拟机》 图1引用链接http://blog.csdn.net/cutesource/article/details/5904501,http://blog.csdn.net/cutesource/article/details/5904542