前端性能优化之缓存利用
缓存种类
大体想了一下,关于缓存,无非有如下几种:
1、CDN缓存
2、DNS缓存
3、客户端缓存(无需请求的memory cache,disk cache,需要发请求验证的Etag、Last-Modified304)
4、Service Worker与缓存及离线缓存
5、PageCache与ajax缓存
CDN缓存
看到一个形象的比喻,来比喻CDN。
10年前,还没有火车票代售点一说,12306.cn更是无从说起。那时候火车票还只能在火车站的售票大厅购买,而我所在的小县城并不通火车,火车票都要去市里的火车站购买,而从我家到县城再到市里,来回就是4个小时车程,简直就是浪费生命。后来就好了,小县城里出现了火车票代售点,甚至乡镇上也有了代售点,可以直接在代售点购买火车票,方便了不少,全市人民再也不用在一个点苦逼的排队买票了。
CDN就可以理解为分布在每个县城或者乡镇的火车票代售点,用户在浏览网站的时候,CDN会选择一个离用户最近的CDN边缘节点来响应用户的请求,这样海南移动用户的请求就不会千里迢迢跑到北京电信机房的服务器(假设源站部署在北京电信机房)上了。
CDN的优势很明显:(1)CDN节点解决了跨运营商和跨地域访问的问题,访问延时大大降低;(2)大部分请求在CDN边缘节点完成,CDN起到了分流作用,减轻了源站的负载。
关于CDN缓存 ,在浏览器本地缓存失效后,浏览器会向CDN边缘节点发起请求。类似浏览器缓存,CDN边缘节点也存在着一套缓存机制。CDN边缘节点缓存策略因服务商不同而不同,但一般都会遵循http标准协议,通过http响应头中的
Cache-control: max-age的字段来设置CDN边缘节点数据缓存时间。
当客户端向CDN节点请求数据时,CDN节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则,CDN节点就会向源站发出回源请求,从源站拉取最新数据,更新本地缓存,并将最新数据返回给客户端。 CDN服务商一般会提供基于文件后缀、目录多个维度来指定CDN缓存时间,为用户提供更精细化的缓存管理。
CDN缓存刷新
CDN边缘节点对开发者是透明的,相比于浏览器Ctrl+F5的强制刷新来使浏览器本地缓存失效,开发者可以通过CDN服务商提供的“刷新缓存”接口来达到清理CDN边缘节点缓存的目的。这样开发者在更新数据后,可以使用“刷新缓存”功能来强制CDN节点上的数据缓存过期,保证客户端在访问时,拉取到最新的数据。
DNS缓存
DNS(Domain Name System): 负责将域名URL转化为服务器主机IP。
DNS查找流程:首先查看浏览器缓存是否存在,不存在则访问本机DNS缓存,再不存在则访问本地DNS服务器。所以DNS也是开销,通常浏览器查找一个给定URL的IP地址要花费20-120ms,在DNS查找完成前,浏览器不能从host那里下载任何东西。
TTL(Time To Live):表示查找返回的DNS记录包含的一个存活时间,过期则这个DNS记录将被抛弃。浏览器DNS缓存也有自己的过期时间,这个时间是独立于本机DNS缓存的,相对也比较短,例如chrome只有1分钟左右。
DNS性能优化最佳实践
当客户端的DNS缓存为空时,DNS查找的数量与Web页面中唯一主机名的数量相等。所以减少唯一主机名的数量就可以减少DNS查找的数量。
但是问题来了,有时候需要多设置主机数量,来增加DNS的负载均衡,因此减少DNS查找和增加主机数量形成了矛盾关系,经过实战DNS设置2-4个主机名是最佳的。更多负载均衡可以用其他方式实现,例如用nginx做负载均衡!
浏览器缓存策略之客户端缓存
1、Cache-control: max-age
假设你的站点有引用一个脚本文件,你非常确认这个脚本文件内容五十年不变。那么自然希望浏览器把这个脚本缓存起来,不用每一次都请求服务器,然后服务器再返回相同的内容。这样能够节省带宽开销并且提升性能。
此时你只需要设置文件返回的HTTP头中的Cache-Control设置为:
Cache-Control: max-age=31536000虽然是五十年不变,但是标准中规定max-age值最大不能超过一年,又因为是以秒为单位,所以值为31536000
例如这个五十年不变的脚本地址是 www.haorooms.com/never-expire.js 那么接下来每次用户请求这个地址时,浏览器都不会再向服务器发出请求,而是直接从本地的浏览器缓存中取。直到一年以后或者用户手动的清除了缓存。
但是,如果这一年中的某一天你发现脚本内容必须要更改了怎么办?很简单,改变请求的文件名就好了,例如never-expire-v2.js。
Cache-control: max-age 可以控制缓存时间。如下图:
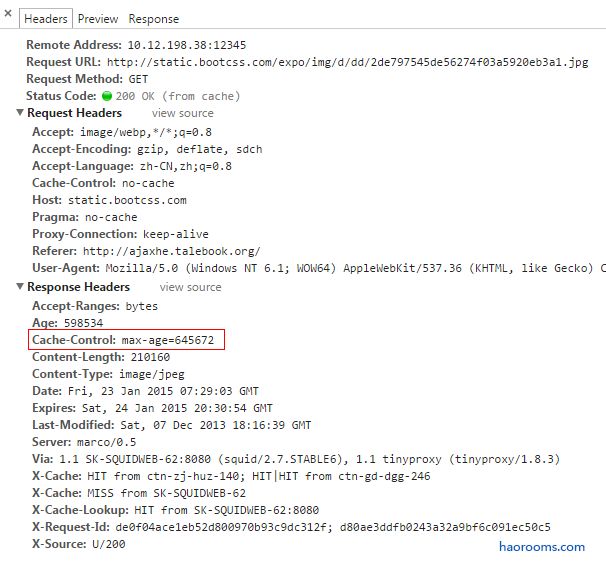
Max-age 使用秒来计量,如:
Cache-Control:max-age=645672指定页面645672秒(7.47天)后过期。
2、Expires
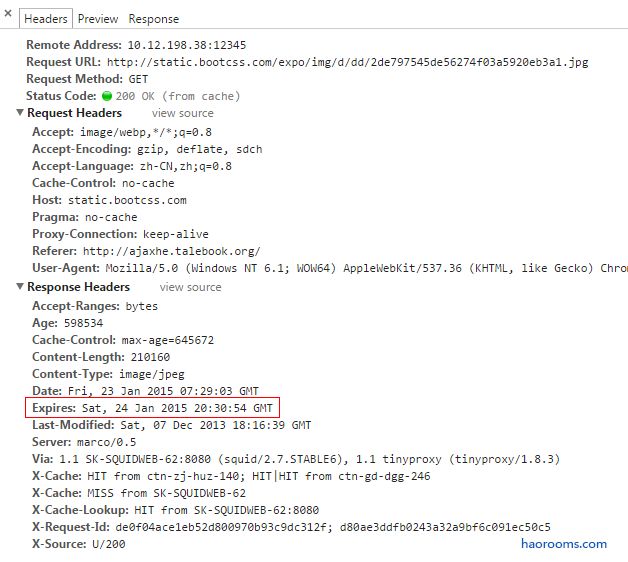
设置了Expires也可以避免浏览器和服务器发请求,直到时间过期。
以上2个缓存,遵循三级缓存原理
3、Last-Modified 304协商缓存
服务器为了通知浏览器当前文件的版本,会发送一个上次修改时间的标签,例如:
Last-Modified:Tue, 06 Jan 2018 08:26:32 GMT如下图:

假如是304协商缓存,验证步骤如下:
浏览器:Hey,我需要jquery.min.js这个文件,如果是在 Last-Modified:Tue, 06 Jan 2018 08:26:32 GMT 之后修改过的,请发给我。
服务器:(检查文件的修改时间)
服务器:Hey,这个文件在那个时间之后没有被修改过,你已经有最新的版本了。
浏览器:太好了,那我就显示给用户了。
4、ETag
上面截图中也圈出来了,其实Etag和304类似,但是级别比 Last-Modified 高一些。
请求过程如下:
1. 浏览器:Hey,我需要haorooms的main.css这个文件,有没有不匹配"61213-1762a-50bf790757204"这个串的
2. 服务器:(检查ETag…)
3. 服务器:Hey,我这里的版本也是"61213-1762a-50bf790757204",你已经是最新的版本了
4. 浏览器:好,那就可以使用本地缓存了Service Worker与缓存及离线缓存
随着Service Worker(以下简称SW)的普及和规范,我们可以使用SW提供的缓存接口替代HTTP缓存。当然SW的功能是强大的,除了缓存功能,还能够使用它来实现离线、数据同步、后台编译等等。
一个标配版的sw缓存工代代码应该有以下的片段:
const version = '2';
self.addEventListener('install', event => {
event.waitUntil(
caches.open(`static-${version}`)
.then(cache => cache.addAll([
'/styles.css',
'/script.js'
]))
);
});
self.addEventListener('fetch', event => {
event.respondWith(
caches.match(event.request)
.then(response => response || fetch(event.request))
);
});首先你要明白的前提是,网络请求首先到达的是SW脚本中,如果未命中再转发给HTTP缓存。
这段代码的意思是,在SW的install阶段我们将script.js和styles.css放入缓存中;而在请求发起的fetch阶段,通过资源的URL去缓存内查找匹配,成功后立刻返回,否则走正常的网络请求流程。
但你有没有考虑过,在install阶段的资源内容是哪里来的?仍然是从HTTP缓存中。这样SW缓存机制又有可能随着HTTP缓存陷入了之前所说的版本不一致的困境中。
既然我们借助SW重写了缓存机制,所以也不想再受牵制于旧的HTTP缓存。解决办法是让SW中的请求必须向服务端验证:
self.addEventListener('install', event => {
event.waitUntil(
caches.open(`static-${version}`)
.then(cache => cache.addAll([
new Request('/styles.css', { cache: 'no-cache' }),
new Request('/script.js', { cache: 'no-cache' })
]))
);
});目前并非所有的浏览器都支持cache选项的配置。但这个不是太大问题,我们可以通过添加随机数来保证每次请求的URL都不相同,间接的使得缓存失效:
self.addEventListener('install', event => {
event.waitUntil(
caches.open(`static-${version}`)
.then(cache => Promise.all(
[
'/styles.css',
'/script.js'
].map(url => {
// cache-bust using a random query string
return fetch(`${url}?${Math.random()}`).then(response => {
// fail on 404, 500 etc
if (!response.ok) throw Error('Not ok');
return cache.put(url, response);
})
})
))
);
});离线缓存
关于离线缓存,可以看我之前的文章:http://www.haorooms.com/post/html5_appcache
PageCache与Ajax可缓存
PageCache其实是facebook提出的,解决ajax缓存的一种方案!简单的说,就是将访问过的页面缓存在客户端。但我们知道,作为Facebook这样交互性很强的网站,需要保障用户能尽早的获得更新后的信息,而不是给用户展示一个毫无意义的过期页面。
Facebook设计了一个框架来识别一个页面是否来自于缓存(猜测:页面首次加载完毕后将所有Ajax的Callback和Result缓存在本地。Facebook页面是基于Ajax获取页面内容,参见BigPipe),若来自于缓存,通过Ajax来更新所需更新的模块(猜测:通过JS预先定义本页面所需更新的div Id及对应的callback handler,并在页面下载时同时下载下来)。
其提到了三种更新类型:增量更新,用户复写(例如用户在页面上回复了一则评论)及跨页更新(例如在消息详细页面将一则消息标识为已读,需将首页的未读消息数进行更新。)。核心思路还是依据Ajax进行更新。具体思路为:
1、增量更新:只要页面来自于缓存,即更新所有预定义的需增量更新的模块。
2、用户复写:通过HistoryManager记录用户操作并在cache页面读取后重放所有被标记为“replayable”的操作。
3、跨页更新:通过服务端Database API发送信号至客户端将过期缓存标识为invalid(不清楚如何实现。也许是DB端提供一个开放的webservice,客户端通过Ajax持续访问此API来获得此信息)。获得了缓存过期信号后,通过Ajax更新需要更新的信息。
Facebook顺带提到了一个更新Ajax内容避免页面变化/闪烁的小技巧,就是先将需更新的地方设置为blank,而非直接更新其内容。
原文链接:https://www.haorooms.com/post/cache_huancunliyong