【Keras-NIN】CIFAR-10
系列连载目录
- 请查看博客 《Paper》 4.1 小节 【Keras】Classification in CIFAR-10 系列连载
学习借鉴
- github:BIGBALLON/cifar-10-cnn
- 知乎专栏:写给妹子的深度学习教程
参考
- 【NIN】《Network In Network》(arXiv-2013)
- 【Keras-CNN】CIFAR-10
- 本地远程访问Ubuntu16.04.3服务器上的TensorBoard
硬件
- TITAN XP
文章目录
- 1 Introduction
- 1.1 CIFAR-10
- 1.2 NIN
- 2 Code
- 2.1 Without Batch Normalization(BN)
- 2.2 With Batch Normalization(BN)
- 2.2.1 原版(bamd)
- 2.2.2 NIN with badm
- 2.2.3 NIN with dbam
- 2.2.4 NIN with bdam
- 2.2.5 小节
1 Introduction
1.1 CIFAR-10
CIFAR-10.是由Alex Krizhevsky、Vinod Nair 与 Geoffrey Hinton 收集的一个用于图像识别的数据集,60000个32*32的彩色图像,50000个training data,10000个test data有10类,飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车,每类6000张图。与MNIST相比,色彩、颜色噪点较多,同一类物体大小不一、角度不同、颜色不同。

1.2 NIN

图片来源 https://zhuanlan.zhihu.com/p/28339912
- 卷积中插入MLP(等价 1*1 conv)增加非线性
- FC替换成 global average pooling
理论细节请参考 【NIN】《Network In Network》(arXiv-2013)。
without Batch Normalization 的版本网络结构以及参数量如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 32, 32, 192) 14592
_________________________________________________________________
activation_1 (Activation) (None, 32, 32, 192) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 32, 32, 160) 30880
_________________________________________________________________
activation_2 (Activation) (None, 32, 32, 160) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 32, 32, 96) 15456
_________________________________________________________________
activation_3 (Activation) (None, 32, 32, 96) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 96) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 16, 16, 96) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 16, 16, 192) 460992
_________________________________________________________________
activation_4 (Activation) (None, 16, 16, 192) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 16, 16, 192) 37056
_________________________________________________________________
activation_5 (Activation) (None, 16, 16, 192) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 16, 16, 192) 37056
_________________________________________________________________
activation_6 (Activation) (None, 16, 16, 192) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 8, 192) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 8, 8, 192) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 8, 8, 192) 331968
_________________________________________________________________
activation_7 (Activation) (None, 8, 8, 192) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 8, 8, 192) 37056
_________________________________________________________________
activation_8 (Activation) (None, 8, 8, 192) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 8, 8, 10) 1930
_________________________________________________________________
activation_9 (Activation) (None, 8, 8, 10) 0
_________________________________________________________________
global_average_pooling2d_1 ( (None, 10) 0
_________________________________________________________________
activation_10 (Activation) (None, 10) 0
=================================================================
Total params: 966,986
Trainable params: 966,986
Non-trainable params: 0
parameters 计算
3 ∗ 5 ∗ 5 ∗ 192 + 192 = 14592 3*5*5*192 + 192 = 14592 3∗5∗5∗192+192=14592
192 ∗ 1 ∗ 1 ∗ 160 + 160 = 30880 192*1*1*160 + 160 = 30880 192∗1∗1∗160+160=30880
160 ∗ 1 ∗ 1 ∗ 96 + 96 = 15456 160*1*1*96 + 96 = 15456 160∗1∗1∗96+96=15456
96 ∗ 5 ∗ 5 ∗ 192 + 192 = 460992 96*5*5*192 + 192 = 460992 96∗5∗5∗192+192=460992
192 ∗ 1 ∗ 1 ∗ 192 + 192 = 37056 192*1*1*192 + 192 = 37056 192∗1∗1∗192+192=37056
192 ∗ 1 ∗ 1 ∗ 192 + 192 = 37056 192*1*1*192 + 192 = 37056 192∗1∗1∗192+192=37056
192 ∗ 3 ∗ 3 ∗ 192 + 192 = 331968 192*3*3*192 + 192 = 331968 192∗3∗3∗192+192=331968
192 ∗ 1 ∗ 1 ∗ 192 + 192 = 37056 192*1*1*192 + 192 = 37056 192∗1∗1∗192+192=37056
192 ∗ 1 ∗ 1 ∗ 10 + 10 = 1930 192*1*1*10 + 10 = 1930 192∗1∗1∗10+10=1930
2 Code
2.1 Without Batch Normalization(BN)
Here we go!!!
1)导入必要的库,设置好 hyper-parameters
import keras
import numpy as np
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, AveragePooling2D
from keras.initializers import RandomNormal
from keras import optimizers
from keras.callbacks import LearningRateScheduler, TensorBoard
from keras.layers.normalization import BatchNormalization
weight_decay = 0.0001# 新增
batch_size = 128
epochs = 200
iterations = 391
num_classes = 10
dropout = 0.5
log_filepath = './nin'
2)数据预处理(减均值,除以标准差),training schedule(learning rate 的设置)
def color_preprocessing(x_train,x_test):
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
mean = [125.307, 122.95, 113.865]
std = [62.9932, 62.0887, 66.7048]
for i in range(3):
x_train[:,:,:,i] = (x_train[:,:,:,i] - mean[i]) / std[i]
x_test[:,:,:,i] = (x_test[:,:,:,i] - mean[i]) / std[i]
return x_train, x_test
def scheduler(epoch):
if epoch <= 80:
return 0.01
if epoch <= 140:
return 0.005
return 0.001
3)构建 NIN 网络,相比 【Keras-LeNet】CIFAR-10多了 drop out 和 global average pooling
网络的 W 默认为初始化为 kernel_initializer='glorot_uniform'
Glorot均匀分布初始化方法,又成 Xavier 均匀初始化,参数从 [ − l i m i t , l i m i t ] [-limit, limit] [−limit,limit] 的均匀分布产生,其中 l i m i t limit limit 为 s q r t ( 6 / ( f a n _ i n + f a n _ o u t ) ) sqrt(6 / (fan\_in + fan\_out)) sqrt(6/(fan_in+fan_out))。 f a n _ i n fan\_in fan_in 为权值张量的输入单元数, f a n _ o u t fan\_out fan_out是权重张量的输出单元数。
def build_model():
model = Sequential()
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
input_shape=x_train.shape[1:]))# 32, 32, 3
model.add(Activation('relu'))
model.add(Conv2D(160, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(Conv2D(96, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Dropout(dropout))
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Dropout(dropout))
model.add(Conv2D(192, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(Conv2D(10, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Activation('relu'))
model.add(GlobalAveragePooling2D())
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
当然可以把 activation 融入 Conv2D 中的,结果精度无差别,速度可能融入到 Conv2D 中会更快一些,分开写的目的是为了方面后面 Batch Normalization 的插入,这种操作要介于 Conv 和 activation 之间的,细节请见 2.2 。

4)导入数据集
# load data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes) # one-hot 编码
y_test = keras.utils.to_categorical(y_test, num_classes) # one-hot 编码
x_train, x_test = color_preprocessing(x_train, x_test) # 把减均值,除以标准差封装成了函数
5)开始训练
model = build_model()
print(model.summary())
# set callback
tb_cb = TensorBoard(log_dir=log_filepath, histogram_freq=0)
change_lr = LearningRateScheduler(scheduler)
cbks = [change_lr,tb_cb]
# set data augmentation
print('Using real-time data augmentation.')
datagen = ImageDataGenerator(horizontal_flip=True,width_shift_range=0.125,height_shift_range=0.125,fill_mode='constant',cval=0.)
datagen.fit(x_train)
# start training
model.fit_generator(datagen.flow(x_train, y_train,batch_size=batch_size),
steps_per_epoch=iterations,
epochs=epochs,
callbacks=cbks,
validation_data=(x_test, y_test))
6)保存模型
# save model
model.save('nin.h5')
结果
training accuracy 和 training loss
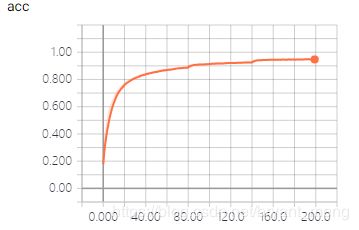

test accuracy 和 test loss

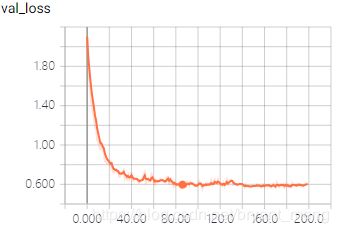

可以看出,和 【Keras-LeNet】CIFAR-10 相比,有很大的提升
我也尝试了变换顺序,结果并没有上述标配版本好
conv→activation→max pooling→dropout
具体的探索我们留给有 BN 的版本,见 2.2 节。
2.2 With Batch Normalization(BN)
【BN】《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》(arXiv-2015)
2.2.1 原版(bamd)
conv→BN→activation→max pooling→dropout
以下都简称为 bamd,话不多说,Here we go!!!
1)首先,导入必要的库,设置好 hyper parameters
import keras
import numpy as np
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, AveragePooling2D
from keras.initializers import RandomNormal
from keras import optimizers
from keras.callbacks import LearningRateScheduler, TensorBoard
from keras.layers.normalization import BatchNormalization
weight_decay = 0.0001# 新增
batch_size = 128
epochs = 200
iterations = 391
num_classes = 10
dropout = 0.5
log_filepath = './nin_bamd'
2) 然后设置好数据预处理过程,和 training schedule(和 without BN,有不同)
def color_preprocessing(x_train,x_test):
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
mean = [125.307, 122.95, 113.865]
std = [62.9932, 62.0887, 66.7048]
for i in range(3):
x_train[:,:,:,i] = (x_train[:,:,:,i] - mean[i]) / std[i]
x_test[:,:,:,i] = (x_test[:,:,:,i] - mean[i]) / std[i]
return x_train, x_test
def scheduler(epoch):
if epoch <= 60:
return 0.05
if epoch <= 120:
return 0.01
if epoch <= 160:
return 0.002
return 0.0004
3)搭建 NIN,涉及到有 dropout的时候,采用 bamd 顺序
def build_model():
model = Sequential()
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(160, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(96, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Dropout(dropout))
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Dropout(dropout))
model.add(Conv2D(192, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(10, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(GlobalAveragePooling2D())
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
4)导入数据集
# load data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes) # one-hot 编码
y_test = keras.utils.to_categorical(y_test, num_classes) # one-hot 编码
x_train, x_test = color_preprocessing(x_train, x_test) # 把减均值,除以标准差封装成了函数
5)开始训练
# build network
model = build_model()
print(model.summary())
# set callback
tb_cb = TensorBoard(log_dir=log_filepath, histogram_freq=0)
change_lr = LearningRateScheduler(scheduler)
cbks = [change_lr,tb_cb]
# set data augmentation
print('Using real-time data augmentation.')
datagen = ImageDataGenerator(horizontal_flip=True,width_shift_range=0.125,height_shift_range=0.125,fill_mode='constant',cval=0.)
datagen.fit(x_train)
# start training
model.fit_generator(datagen.flow(x_train, y_train,batch_size=batch_size),
steps_per_epoch=iterations,
epochs=epochs,
callbacks=cbks,
validation_data=(x_test, y_test))
6)保存模型
# save model
model.save('nin_bamd.h5')
看看模型咯
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 32, 32, 192) 14592
_________________________________________________________________
batch_normalization_1 (Batch (None, 32, 32, 192) 768
_________________________________________________________________
activation_1 (Activation) (None, 32, 32, 192) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 32, 32, 160) 30880
_________________________________________________________________
batch_normalization_2 (Batch (None, 32, 32, 160) 640
_________________________________________________________________
activation_2 (Activation) (None, 32, 32, 160) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 32, 32, 96) 15456
_________________________________________________________________
batch_normalization_3 (Batch (None, 32, 32, 96) 384
_________________________________________________________________
activation_3 (Activation) (None, 32, 32, 96) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 96) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 16, 16, 96) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 16, 16, 192) 460992
_________________________________________________________________
batch_normalization_4 (Batch (None, 16, 16, 192) 768
_________________________________________________________________
activation_4 (Activation) (None, 16, 16, 192) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 16, 16, 192) 37056
_________________________________________________________________
batch_normalization_5 (Batch (None, 16, 16, 192) 768
_________________________________________________________________
activation_5 (Activation) (None, 16, 16, 192) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 16, 16, 192) 37056
_________________________________________________________________
batch_normalization_6 (Batch (None, 16, 16, 192) 768
_________________________________________________________________
activation_6 (Activation) (None, 16, 16, 192) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 8, 192) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 8, 8, 192) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 8, 8, 192) 331968
_________________________________________________________________
batch_normalization_7 (Batch (None, 8, 8, 192) 768
_________________________________________________________________
activation_7 (Activation) (None, 8, 8, 192) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 8, 8, 192) 37056
_________________________________________________________________
batch_normalization_8 (Batch (None, 8, 8, 192) 768
_________________________________________________________________
activation_8 (Activation) (None, 8, 8, 192) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 8, 8, 10) 1930
_________________________________________________________________
batch_normalization_9 (Batch (None, 8, 8, 10) 40
_________________________________________________________________
activation_9 (Activation) (None, 8, 8, 10) 0
_________________________________________________________________
global_average_pooling2d_1 ( (None, 10) 0
_________________________________________________________________
activation_10 (Activation) (None, 10) 0
=================================================================
Total params: 972,658
Trainable params: 969,822
Non-trainable params: 2,836
_________________________________________________________________
比 without Batch Normalization 多了一些参数,多的就是 Batch Normalization 操作的计算量
- without Batch Normalization :966986
- with Batch Normalization :972658
BN 层的 parameters 如何计算呢?根据 【BN】《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》 可知,BN 引入了四个变量,均值 μ \mu μ、方差 σ 2 \sigma^2 σ2 以及线性变换系数 γ \gamma γ 和 β \beta β,所以 BN 层 parameters 的计算方式为 4 ∗ c h a n n e l s 4*channels 4∗channels,详细计算如下:
- 4 ∗ 192 = 768 4*192 = 768 4∗192=768
- 4 ∗ 160 = 640 4*160 = 640 4∗160=640
- 4 ∗ 96 = 384 4*96 = 384 4∗96=384
- 4 ∗ 192 = 768 4*192 = 768 4∗192=768
- 4 ∗ 192 = 768 4*192 = 768 4∗192=768
- 4 ∗ 192 = 768 4*192 = 768 4∗192=768
- 4 ∗ 192 = 768 4*192 = 768 4∗192=768
- 4 ∗ 192 = 768 4*192 = 768 4∗192=768
- 4 ∗ 10 = 40 4*10 = 40 4∗10=40
上述加起来 768 + 640 + 384 + 768 + 768 + 768 + 768 + 768 + 40 = 5672 768+640+384+768+768+768+768+768+40 = 5672 768+640+384+768+768+768+768+768+40=5672
966986 ( w i t h o u t B N ) + 5672 ( B N ) = 972658 ( w i t h B N ) 966986(without \ BN) + 5672(BN) = 972658(with \ BN) 966986(without BN)+5672(BN)=972658(with BN)
至此,total parameters 解决了,Trainable params 和 Non-trainable params 又是什么?
BN 中的均值 μ \mu μ 和方差 σ 2 \sigma^2 σ2 是根据 mini-batch 来更新的,而 γ \gamma γ 和 β \beta β 是根据网络的训练得到的,所以
- Trainable params: 966986 + 5672 / 2 = 969822 966986 + 5672/2 = 969822 966986+5672/2=969822( γ \gamma γ、 β \beta β)
- Non-trainable params: 5672 / 2 = 2836 5672/2 = 2836 5672/2=2836 ( μ \mu μ 、 σ 2 \sigma^2 σ2)
结果如下,橘色的是 2.1 中的 without bn,他们的 training schedule 不一样(其实比起来有些不公平滴)
training accuracy 和 training loss
![]()
![]()


test accuracy 和 test loss
![]()
![]()
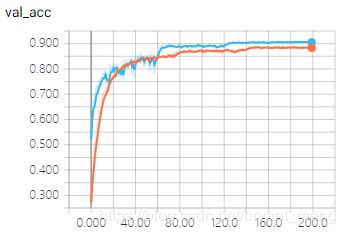

可以看出,加了 BN 之后,收敛更快,最终结果更好,带来的 side effect 是训练时间会多一些

2.2.2 NIN with badm


任恒之:“命若天定,我便破了这个天”。(出自某 top 互联网公司的某款卡牌游戏中的语音设定)
我们尝试别的顺序咯,注意一个准则, BN 要在 conv 和 activation 之间
conv→BN→activation→dropout→max pooling
以下都简称为 badm
和 2.2.1 节相比,做如下修改即可
1)最开始 log_filepath 修改如下
log_filepath = './nin_badm'
2)最后保存的模型名字做相应的修改
model.save('nin_badm.h5')
3)模型修改,调换 max pooling 和 dropout 的顺序
def build_model():
model = Sequential()
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(160, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(96, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Conv2D(192, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(10, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(GlobalAveragePooling2D())
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
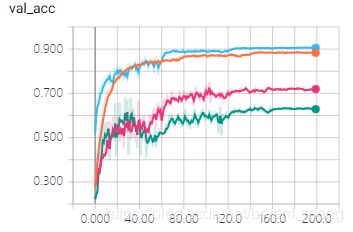
结果如下:
training accuracy 和 training loss
![]()
![]()
![]()


哈哈,开心,调整了顺序猛多了
test accuracy 和 test loss
![]()
![]()
![]()
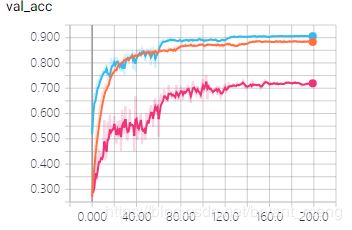
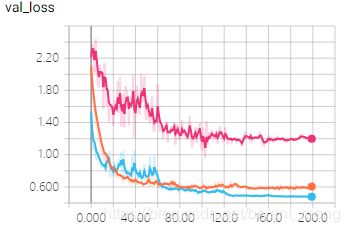
……高兴的太早了,超级过拟合,效果好差,为什么差……以后再分析!暂存错误经验

2.2.3 NIN with dbam
任恒之:“命若天定,我便破了这个天”。(出自某 top 互联网公司的某款卡牌游戏中的语音设定)
我还是不服,继续来
conv→dropout→BN→activation→max pooling
以下都简称为 dbam
和 2.2.1 节相比,做如下修改即可
1)最开始 log_filepath 修改如下
log_filepath = './nin_dbam'
2)最后保存的模型名字做相应的修改
model.save('nin_dbam.h5')
3)模型修改
def build_model():
model = Sequential()
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(160, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(96, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Dropout(dropout))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(Dropout(dropout))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Conv2D(192, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(10, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(GlobalAveragePooling2D())
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
结果如下:
training accuracy 和 training loss
![]()
![]()
![]()
![]()


一脸灰线,新增的模型呢? what?点具体的才发现和 2.2.2 中的艳红色重叠了,开心,效果不错,而且训练时间比不加 BN 还短,好兆头

test accuracy 和 test loss
![]()
![]()
![]()
![]()
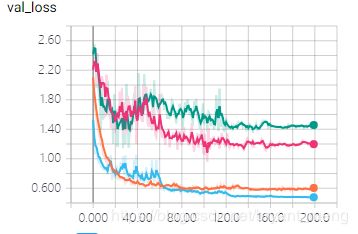
……咳咳,各位,不好意思,我有事先走了,有缘再见……,这效果,超级过拟合哟,比 2.2.2 还差,严重鄙视+嫌弃,哈哈哈

2.2.4 NIN with bdam
任恒之:“命若天定,我便破了这个天”。(出自某 top 互联网公司的某款卡牌游戏中的语音设定)
继续继续
conv→BN→dropout→activation→max pooling
以下都简称为 bdam
和 2.2.1 节相比,做如下修改即可
1)最开始 log_filepath 修改如下
log_filepath = './nin_bdam'
2)最后保存的模型名字做相应的修改
model.save('nin_bdam.h5')
3)模型修改
def build_model():
model = Sequential()
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay), input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(160, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(96, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Dropout(dropout))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Dropout(dropout))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same'))
model.add(Conv2D(192, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(10, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(GlobalAveragePooling2D())
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
结果如下:
training accuracy 和 training loss
![]()
![]()
![]()
![]()
![]()


what?又不见踪影了?有上一小节的情况,这次我并没有那么慌!

果然,又和 2.2.2 和 2.2.3 中的结果重叠了,这下我又开始慌了,这是过拟合的节奏哟……god bless me!
test accuracy 和 test loss
![]()
![]()
![]()
![]()
![]()


……咳咳,确实咯,我只能说,比 2.2.2 和 2.2.3 争气一点吧,但是和蓝色的还是有不小的差距
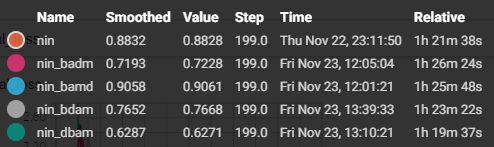
模型的大小
![]()
2.2.5 小节

刘伯温:“大梦谁先觉 平生我自知”。(出自某 top 互联网公司的某款卡牌游戏中的语音设定)
放弃挣扎,结论:还是原配好啊!!!

conv→BN→activation→max pooling→dropout
- without Batch Normalization: 88.32%
- with Batch Normalization: 90.58%